Phiên bản Amazon EC2 Trn2 và UltraServers
Cấu hình EC2 hiệu năng cao nhất cho đào tạo và suy luận AI tạo sinh
Tại sao nên chọn phiên bản Amazon EC2 Trn2 và UltraServers?
Phiên bản Amazon EC2 Trn2 hoạt động bằng 16 chip AWS Trainium2, là thiết kế chuyên dụng cho AI tạo sinh và mang lại phiên bản EC2 hiệu năng cao để đào tạo cũng như triển khai mô hình với từ hàng trăm tỷ đến trên hàng nghìn tỷ tham số. Phiên bản Trn2 giúp tăng 30-40% hiệu năng trên chi phí so với phiên bản EC2 P5e và P5en sử dụng GPU. Với phiên bản Trn2, hiệu suất đào tạo và suy luận sẽ đạt cấp độ hiện đại nhất với chi phí rẻ hơn giúp bạn tiết kiệm thời gian đào tạo, tăng tốc độ lặp lại và tận hưởng trải nghiệm do AI cung cấp theo thời gian thực. Bạn có thể sử dụng phiên bản Trn2 để đào tạo và triển khai các mô hình bao gồm mô hình ngôn ngữ lớn (LLM), mô hình đa phương thức và bộ chuyển đổi khuếch tán để xây dựng các ứng dụng AI tạo sinh thế hệ mới.
Để tiết kiệm thời gian đào tạo và đạt được thời gian phản hồi đột phá (độ trễ theo từng mã thông báo) cho các mô hình tiên tiến và khắt khe nhất, bạn có thể cần đến sức mạnh điện toán và bộ nhớ vượt xa khả năng của một phiên bản đơn lẻ. Trn2 UltraServers sử dụng NeuronLink, công nghệ liên kết giữa các chip độc quyền của chúng tôi, để kết nối 64 chip Trainium2 trên bốn phiên bản Trn2, giúp tăng gấp bốn lần băng thông mạng, bộ nhớ và điện toán hiện có trong một nút duy nhất và mang lại hiệu suất đột phá trên AWS cho khối lượng công việc học sâu và AI tạo sinh. Đối với suy luận, UltraServers giúp mang đến thời gian phản hồi đầu ngành để tạo ra trải nghiệm thời gian thực tốt nhất. Còn với đào tạo, UltraServers thúc đẩy tốc độ và hiệu quả đào tạo mô hình nhờ phương thức giao tiếp tập thể nhanh hơn, hỗ trợ kỹ thuật chạy song song mô hình so với các phiên bản độc lập.
Bạn có thể dễ dàng bắt đầu sử dụng phiên bản Trn2 và Trn2 UltraServers với hỗ trợ thuần cho các nền tảng máy học (ML) phổ biến như PyTorch và JAX.
“Trn2 UltraServers hiện đã được cung cấp nhằm phục vụ khối lượng công việc AI tạo sinh đòi hỏi khắt khe nhất.”
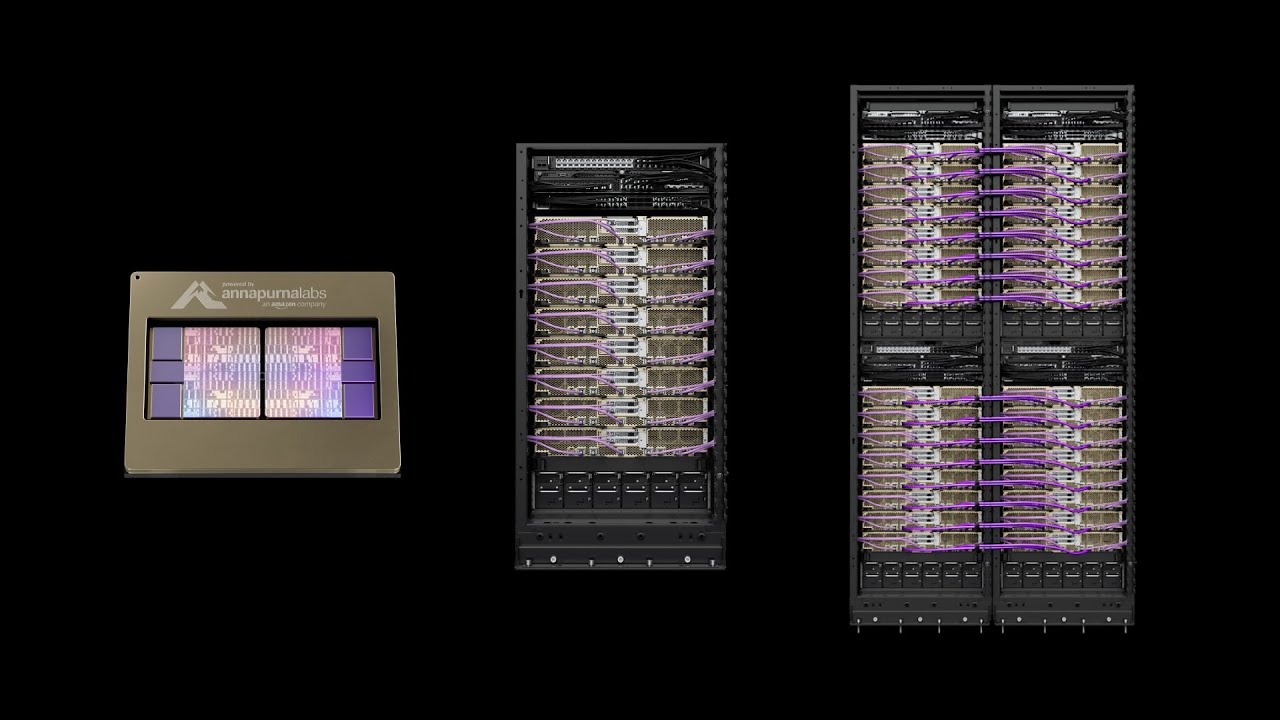
Lợi ích
Phiên bản Trn2 giúp bạn giảm thời gian đào tạo và cung cấp trải nghiệm suy luận theo thời gian thực cho người dùng cuối. Phiên bản Trn2 có 16 chip Trainium2 được kết nối bằng NeuronLink, công nghệ liên kết giữa các chip độc quyền độc quyền của chúng tôi, để cung cấp khả năng điện toán lên đến 20,8 petaflop FP8. Phiên bản Trn2 có tổng cộng 1,5 TB HBM3 với băng thông bộ nhớ 46 terabyte/giây (TBps) và mạng Elastic Fabric Adapter (EFAv3) có tốc độ 3,2 terabit/giây (Tbps). Trn2 UltraServers (được cung cấp dưới dạng phiên bản xem trước), có 64 chip Trainium2 được kết nối bằng NeuronLink và cung cấp khả năng điện toán lên đến 83,2 petaflop FP8, tổng bộ nhớ băng thông cao 6 TB với tổng băng thông bộ nhớ 185 TBps và mạng EFAv3 có tốc độ 12,8 Tbps.
Để tạo điều kiện đào tạo phân tán hiệu quả, phiên bản Trn2 cung cấp mạng EFAv3 có tốc độ 3,2 Tbps còn với Trn2 UltraServers là 12,8 Tbps. EFA được xây dựng trên AWS Nitro System, có nghĩa là tất cả các giao tiếp thông qua EFA đều được mã hóa trong quá trình chuyển tiếp mà không ảnh hưởng đến hiệu suất. EFA cũng sử dụng một giao thức kiểm soát tắc nghẽn và định tuyến giao thông tinh vi cho phép điều chỉnh quy mô lên hàng trăm nghìn chip Trainium2 với độ tin cậy cao. Các phiên bản Trn2 và UltraServers đang được triển khai trong EC2 UltraClusters để tạo điều kiện tăng quy mô theo phiên bản đào tạo phân tán ra hàng chục nghìn chip Trainium trên một mạng không chặn quy mô petabit duy nhất.
Phiên bản Trn2 giúp tăng 30-40% hiệu năng trên chi phí so với phiên bản EC2 P5e và P5en sử dụng GPU
Phiên bản Trn2 tiết kiệm năng lượng gấp 3 lần so với phiên bản Trn1. Các phiên bản này và các chip cơ sở sử dụng quy trình silicon tiên tiến và tối ưu hóa phần cứng và phần mềm để mang lại hiệu quả năng lượng cao khi chạy các khối lượng công việc AI tạo sinh trên quy mô lớn.
SDK AWS Neuron giúp bạn tận dụng tối đa hiệu suất từ các phiên bản Trn2 và UltraServers. Neuron tích hợp thuần với JAX, PyTorch và các thư viện thiết yếu như Hugging Face, PyTorch Lightning và các thư viện khác. Neuron được xây dựng cho các nhà nghiên cứu và nhà khám phá AI để khai mở hiệu suất đột phá. Với khả năng tích hợp PyTorch thuần, bạn có thể đào tạo và triển khai mà không cần thay đổi một dòng mã mô hình nào. Đối với kỹ sư hiệu năng AI, chúng tôi đã mở quyền truy cập sâu hơn vào Trainium 2 để bạn có thể tinh chỉnh hiệu năng, tùy chỉnh nhân và đưa mô hình này đi xa hơn nữa. Với Neuron, bạn có thể sử dụng phiên bản Trn2 với các dịch vụ như Amazon SageMaker, Amazon EKS, Amazon ECS, AWS ParallelCluster và AWS Batch, cũng như các dịch vụ của bên thứ ba như Ray (Anyscale), Domino Data Lab và Datadog. Bởi vì sự cởi mở chính là nền tảng phát triển cho đổi mới, Neuron cam kết thúc đẩy sự đổi mới thông qua nguồn mở và cộng tác mở với cộng đồng AI rộng lớn hơn.
Tính năng
Các phiên bản Trn2 có 16 chip Trainium2 được kết nối với NeuronLink để cung cấp hiệu năng điện toán lên đến 20,8 petaflop FP8. Trn2 UltraServers mở rộng kết nối NeuronLink lên 64 chip Trainium2 trên bốn phiên bản Trn2 để cung cấp hiệu năng điện toán lên đến 83,2 petaflop FP8.
Phiên bản Trn2 cung cấp 1,5 TB bộ nhớ của trình tăng tốc tăng tốc với tổng băng thông bộ nhớ 46 TBps. Trn2 UltraServers cung cấp bộ nhớ của trình tăng tốc dùng chung 6 TB với tổng băng thông bộ nhớ 185 TBps để phù hợp với các mô hình nền tảng siêu lớn.
Để hỗ trợ đào tạo phân tán tăng quy mô theo phiên bản cho các mô hình nền tảng siêu lớn, phiên bản Trn2 cung cấp băng thông mạng EFAv3 có tốc độ là 3,2 Tbps còn với Trn2 UltraServers là 12,8 Tbps. Khi kết hợp với EC2 UltraClusters, EFAv3 mang lại độ trễ mạng thấp hơn so với EFAv2. Mỗi phiên bản Trn2 hỗ trợ tối đa 8 TB còn mỗi Trn2 UltraServers hỗ trợ tối đa 32 TB bộ lưu trữ NVMe cục bộ để truy cập nhanh hơn vào các tập dữ liệu lớn.
Phiên bản Trn2 và UltraServers hỗ trợ FP32, TF32, BF16, FP16 và các kiểu dữ liệu FP8 (cFP8) có thể cấu hình. Phiên bản này cũng hỗ trợ các hạng mục tối ưu hóa AI tối tân bao gồm độ thưa gấp 4 lần (16:4), làm tròn ngẫu nhiên và các công cụ thu thập chuyên dụng. Neuron Kernel Interface (NKI) tạo điều kiện truy cập trực tiếp vào kiến trúc tập lệnh (ISA) bằng cách sử dụng môi trường dựa trên Python bằng giao diện giống Triton cho phép bạn đổi mới kiến trúc mô hình mới và hạt nhân điện toán có mức độ tối ưu hóa cao tạo ra hiệu suất vượt trội hơn các kỹ thuật hiện có.
Neuron hỗ trợ hơn 100.000 mô hình trên trung tâm mô hình Hugging Face để đào tạo và triển khai trên Trn2, trong đó có các kiến trúc mô hình phổ biến như Llama và Stable Diffusion. Neuron tích hợp thuần với JAX, PyTorch và các công cụ, khung và thư viện thiết yếu như NeMo, Hugging Face, PyTorch Lightning, Ray, Domino Data Lab và Data Dog. Công cụ này tối ưu hóa mô hình sẵn dùng cho hoạt động đào tạo và suy luận phân tán, đồng thời cung cấp thông tin có độ chuyên sâu cao để lập hồ sơ và gỡ lỗi. Neuron cũng tích hợp với các dịch vụ như Amazon SageMaker, Amazon EKS, Amazon ECS, AWS ParallelCluster và AWS Batch.
Chứng thực của khách hàng và đối tác
Dưới đây là một số ví dụ về cách khách hàng và đối tác lên kế hoạch đạt được mục tiêu kinh doanh của mình với các Phiên bản Amazon EC2 Trn2.
Anthropic
 Tại Anthropic, mỗi ngày có hàng triệu người dựa vào Claude để thực hiện công việc của họ. Chúng tôi sẽ công bố hai tiến bộ lớn với AWS: Thứ nhất, “chế độ tối ưu hóa độ trễ” mới cho Claude 3.5 Haiku chạy nhanh hơn 60% trên Trainium2 thông qua Amazon Bedrock. Và thứ hai, Project Rainier – một cụm mới với hàng trăm nghìn chip Trainium2 cung cấp hàng trăm exaflop, gấp hơn năm lần kích thước của cụm trước đó của chúng tôi. Dự án Rainier sẽ giúp thúc đẩy cả nghiên cứu và thế hệ mở rộng quy mô tiếp theo của chúng tôi. Đối với khách hàng của chúng tôi, điều này có nghĩa là thông minh hơn, giá thấp hơn và tốc độ nhanh hơn. Chúng tôi không chỉ xây dựng AI có tốc độ nhanh hơn, chúng tôi còn xây dựng AI đáng tin cậy có khả năng điều chỉnh quy mô. - Tom Brown, Giám đốc điện toán tại Anthropic
Tại Anthropic, mỗi ngày có hàng triệu người dựa vào Claude để thực hiện công việc của họ. Chúng tôi sẽ công bố hai tiến bộ lớn với AWS: Thứ nhất, “chế độ tối ưu hóa độ trễ” mới cho Claude 3.5 Haiku chạy nhanh hơn 60% trên Trainium2 thông qua Amazon Bedrock. Và thứ hai, Project Rainier – một cụm mới với hàng trăm nghìn chip Trainium2 cung cấp hàng trăm exaflop, gấp hơn năm lần kích thước của cụm trước đó của chúng tôi. Dự án Rainier sẽ giúp thúc đẩy cả nghiên cứu và thế hệ mở rộng quy mô tiếp theo của chúng tôi. Đối với khách hàng của chúng tôi, điều này có nghĩa là thông minh hơn, giá thấp hơn và tốc độ nhanh hơn. Chúng tôi không chỉ xây dựng AI có tốc độ nhanh hơn, chúng tôi còn xây dựng AI đáng tin cậy có khả năng điều chỉnh quy mô. - Tom Brown, Giám đốc điện toán tại Anthropic
Databricks
 Mosaic AI của Databricks cho phép các tổ chức xây dựng và triển khai Hệ thống tác tử chất lượng. Hệ thốg này được xây dựng thuần trên hồ dữ liệu, tạo điều kiện cho khách hàng tùy chỉnh dễ dàng và bảo mật mô hình của họ bằng dữ liệu doanh nghiệp và cung cấp đầu ra chính xác hơn và cụ thể theo miền. Nhờ hiệu suất cao và hiệu quả chi phí của Trainium, khách hàng có thể điều chỉnh quy mô đào tạo mô hình trên Mosaic AI với chi phí thấp. Tính khả dụng của Trainium2 sẽ là một lợi ích lớn cho Databricks cũng như khách hàng của họ khi nhu cầu về Mosaic AI tiếp tục mở rộng ra tất cả các phân khúc khách hàng và trên toàn thế giới. Databricks, một trong những công ty dữ liệu và AI lớn nhất thế giới, có kế hoạch sử dụng TRN2 để mang lại kết quả tốt hơn và giảm TCO lên đến 30% cho khách hàng của mình. - Naveen Rao, Phó chủ tịch phụ trách AI tạo sinh, Databricks
Mosaic AI của Databricks cho phép các tổ chức xây dựng và triển khai Hệ thống tác tử chất lượng. Hệ thốg này được xây dựng thuần trên hồ dữ liệu, tạo điều kiện cho khách hàng tùy chỉnh dễ dàng và bảo mật mô hình của họ bằng dữ liệu doanh nghiệp và cung cấp đầu ra chính xác hơn và cụ thể theo miền. Nhờ hiệu suất cao và hiệu quả chi phí của Trainium, khách hàng có thể điều chỉnh quy mô đào tạo mô hình trên Mosaic AI với chi phí thấp. Tính khả dụng của Trainium2 sẽ là một lợi ích lớn cho Databricks cũng như khách hàng của họ khi nhu cầu về Mosaic AI tiếp tục mở rộng ra tất cả các phân khúc khách hàng và trên toàn thế giới. Databricks, một trong những công ty dữ liệu và AI lớn nhất thế giới, có kế hoạch sử dụng TRN2 để mang lại kết quả tốt hơn và giảm TCO lên đến 30% cho khách hàng của mình. - Naveen Rao, Phó chủ tịch phụ trách AI tạo sinh, Databricks
poolside
 Tại poolside, chúng tôi sẵn sàng xây dựng một thế giới nơi AI thúc đẩy phần lớn công việc có giá trị kinh tế và tiến bộ khoa học. Chúng tôi tin rằng khả năng chính đầu tiên của các mạng nơ-ron đạt đến trí thông minh ở cấp độ con người là phát triển phần mềm do đây là lĩnh vực chúng tôi có thể kết hợp các phương pháp Tìm kiếm và Học tập tốt nhất. Để mở đường cho viễn cảnh đó, chúng tôi đang xây dựng các mô hình nền tảng, API và Trợ lý để mang sức mạnh của AI tạo sinh đến tay (hoặc bàn phím) các nhà phát triển của bạn. Cơ sở hạ tầng chúng tôi đang sử dụng để xây dựng và chạy các sản phẩm của mình là chìa khóa chính để kích hoạt công nghệ này. Với AWS Trainium2, khách hàng của chúng tôi có thể điều chỉnh quy mô sử dụng poolside với tỷ lệ hiệu năng trên chi phí không giống như các bộ tăng tốc AI khác. Ngoài ra, chúng tôi có kế hoạch đào tạo các mô hình tương lai với Trainium2 UltraServers với mức tiết kiệm dự kiến là 40% so với phiên bản EC2 P5. - Eiso Kant, CTO & Đồng sáng lập, poolside
Tại poolside, chúng tôi sẵn sàng xây dựng một thế giới nơi AI thúc đẩy phần lớn công việc có giá trị kinh tế và tiến bộ khoa học. Chúng tôi tin rằng khả năng chính đầu tiên của các mạng nơ-ron đạt đến trí thông minh ở cấp độ con người là phát triển phần mềm do đây là lĩnh vực chúng tôi có thể kết hợp các phương pháp Tìm kiếm và Học tập tốt nhất. Để mở đường cho viễn cảnh đó, chúng tôi đang xây dựng các mô hình nền tảng, API và Trợ lý để mang sức mạnh của AI tạo sinh đến tay (hoặc bàn phím) các nhà phát triển của bạn. Cơ sở hạ tầng chúng tôi đang sử dụng để xây dựng và chạy các sản phẩm của mình là chìa khóa chính để kích hoạt công nghệ này. Với AWS Trainium2, khách hàng của chúng tôi có thể điều chỉnh quy mô sử dụng poolside với tỷ lệ hiệu năng trên chi phí không giống như các bộ tăng tốc AI khác. Ngoài ra, chúng tôi có kế hoạch đào tạo các mô hình tương lai với Trainium2 UltraServers với mức tiết kiệm dự kiến là 40% so với phiên bản EC2 P5. - Eiso Kant, CTO & Đồng sáng lập, poolside
Itaú Unibanco
 Mục đích của Itaú Unibanco là cải thiện mối quan hệ của mọi người với tiền bạc, tạo ra tác động tích cực đến cuộc sống của họ đồng thời mở rộng cơ hội chuyển đổi của họ. Tại Itaú Unibanco, chúng tôi tin rằng không có khách hàng giống khách hàng nào và chúng tôi tập trung vào việc đáp ứng nhu cầu của họ thông qua hành trình kỹ thuật số trực quan, tận dụng sức mạnh của AI để liên tục thích ứng với thói quen tiêu dùng của họ. Chúng tôi đã thử nghiệm AWS Trainium và Inferentia trên nhiều nhiệm vụ khác nhau, từ suy luận tiêu chuẩn đến các ứng dụng tinh chỉnh. Hiệu suất của các chip AI này đã tạo điều kiện cho chúng tôi đạt được các cột mốc quan trọng trong nghiên cứu và phát triển của mình. Đối với cả tác vụ suy luận hàng loạt và trực tuyến, chúng tôi đã chứng kiến thông lượng tăng 7 lần so với GPU. Hiệu suất tăng cao này đang thúc đẩy việc mở rộng nhiều trường hợp sử dụng hơn trên khắp tổ chức. Thế hệ chip Trainium2 mới nhất mở ra các tính năng đột phá cho GenAI và mở ra cánh cửa cho sự đổi mới tại Itau. - Vitor Azeka, Trưởng bộ phận Khoa học dữ liệu, Itaú Unibanco
Mục đích của Itaú Unibanco là cải thiện mối quan hệ của mọi người với tiền bạc, tạo ra tác động tích cực đến cuộc sống của họ đồng thời mở rộng cơ hội chuyển đổi của họ. Tại Itaú Unibanco, chúng tôi tin rằng không có khách hàng giống khách hàng nào và chúng tôi tập trung vào việc đáp ứng nhu cầu của họ thông qua hành trình kỹ thuật số trực quan, tận dụng sức mạnh của AI để liên tục thích ứng với thói quen tiêu dùng của họ. Chúng tôi đã thử nghiệm AWS Trainium và Inferentia trên nhiều nhiệm vụ khác nhau, từ suy luận tiêu chuẩn đến các ứng dụng tinh chỉnh. Hiệu suất của các chip AI này đã tạo điều kiện cho chúng tôi đạt được các cột mốc quan trọng trong nghiên cứu và phát triển của mình. Đối với cả tác vụ suy luận hàng loạt và trực tuyến, chúng tôi đã chứng kiến thông lượng tăng 7 lần so với GPU. Hiệu suất tăng cao này đang thúc đẩy việc mở rộng nhiều trường hợp sử dụng hơn trên khắp tổ chức. Thế hệ chip Trainium2 mới nhất mở ra các tính năng đột phá cho GenAI và mở ra cánh cửa cho sự đổi mới tại Itau. - Vitor Azeka, Trưởng bộ phận Khoa học dữ liệu, Itaú Unibanco
NinjaTech AI
 Ninja là một Tác tử AI đa năng cho năng suất không giới hạn: một gói đăng ký đơn giản, quyền truy cập không giới hạn vào các mô hình AI tốt nhất thế giới cùng với các kỹ năng AI hàng đầu như: viết, mã hóa, động não, tạo hình ảnh, nghiên cứu trực tuyến. Ninja là một nền tảng tác tử và cung cấp “SuperAgent” sử dụng hỗn hợp các tác tử với độ chính xác đẳng cấp thế giới tương đương với (và thậm chí đánh bại trong một số danh mục) các mô hình nền tảng tiên phong. Công nghệ Tác tử của Ninja đòi hỏi các bộ tăng tốc hiệu suất cao nhất, để mang lại trải nghiệm thời gian thực độc đáo mà khách hàng của chúng tôi mong đợi. Chúng tôi vô cùng hào hứng với sự ra mắt của AWS TRN2 vì chúng tôi tin rằng nó sẽ mang lại hiệu suất chi phí tốt nhất cho mỗi token và tốc độ nhanh nhất hiện tại cho mẫu Ninja LLM cốt lõi của chúng tôi dựa trên Llama 3.1 405B. Thật tuyệt vời khi được chứng kiến độ trễ thấp của Trn2 cùng với mức giá cả cạnh tranh và tính khả dụng theo yêu cầu; chúng tôi thật sự hào hứng tột độ về sự xuất hiện của Trn2! - Babak Pahlavan, Nhà sáng lập & Giám đốc điều hành, NinjaTech AI
Ninja là một Tác tử AI đa năng cho năng suất không giới hạn: một gói đăng ký đơn giản, quyền truy cập không giới hạn vào các mô hình AI tốt nhất thế giới cùng với các kỹ năng AI hàng đầu như: viết, mã hóa, động não, tạo hình ảnh, nghiên cứu trực tuyến. Ninja là một nền tảng tác tử và cung cấp “SuperAgent” sử dụng hỗn hợp các tác tử với độ chính xác đẳng cấp thế giới tương đương với (và thậm chí đánh bại trong một số danh mục) các mô hình nền tảng tiên phong. Công nghệ Tác tử của Ninja đòi hỏi các bộ tăng tốc hiệu suất cao nhất, để mang lại trải nghiệm thời gian thực độc đáo mà khách hàng của chúng tôi mong đợi. Chúng tôi vô cùng hào hứng với sự ra mắt của AWS TRN2 vì chúng tôi tin rằng nó sẽ mang lại hiệu suất chi phí tốt nhất cho mỗi token và tốc độ nhanh nhất hiện tại cho mẫu Ninja LLM cốt lõi của chúng tôi dựa trên Llama 3.1 405B. Thật tuyệt vời khi được chứng kiến độ trễ thấp của Trn2 cùng với mức giá cả cạnh tranh và tính khả dụng theo yêu cầu; chúng tôi thật sự hào hứng tột độ về sự xuất hiện của Trn2! - Babak Pahlavan, Nhà sáng lập & Giám đốc điều hành, NinjaTech AI
Ricoh
 Bộ phận máy học của RICOH phát triển các giải pháp không gian làm việc và dịch vụ chuyển đổi kỹ thuật số được thiết kế để quản lý và tối ưu hóa luồng thông tin trên khắp các giải pháp doanh nghiệp của chúng tôi. Việc di chuyển sang các phiên bản Trn1 rất dễ dàng và đơn giản. Chúng tôi có thể đào tạo trước LLM 13 tham số của mình chỉ trong 8 ngày, sử dụng một cụm 4.096 chip Trainium! Sau thành công chúng tôi chứng kiến với mô hình nhỏ hơn của mình, chúng tôi đã tinh chỉnh một LLM mới, lớn hơn dựa trên Llama-3-Swallow-70B và, tận dụng Trainium, chúng tôi có thể giảm 50% chi phí đào tạo và cải thiện hiệu quả năng lượng thêm 25% so với việc sử dụng các máy GPU mới nhất trong AWS. Chúng tôi rất vui mừng được tận dụng thế hệ Chip AI AWS mới nhất, Trainium2, để tiếp tục cung cấp cho khách hàng hiệu năng tốt nhất với chi phí thấp nhất. - Yoshiaki Umetsu, Giám đốc Trung tâm phát triển công nghệ kỹ thuật số, Ricoh
Bộ phận máy học của RICOH phát triển các giải pháp không gian làm việc và dịch vụ chuyển đổi kỹ thuật số được thiết kế để quản lý và tối ưu hóa luồng thông tin trên khắp các giải pháp doanh nghiệp của chúng tôi. Việc di chuyển sang các phiên bản Trn1 rất dễ dàng và đơn giản. Chúng tôi có thể đào tạo trước LLM 13 tham số của mình chỉ trong 8 ngày, sử dụng một cụm 4.096 chip Trainium! Sau thành công chúng tôi chứng kiến với mô hình nhỏ hơn của mình, chúng tôi đã tinh chỉnh một LLM mới, lớn hơn dựa trên Llama-3-Swallow-70B và, tận dụng Trainium, chúng tôi có thể giảm 50% chi phí đào tạo và cải thiện hiệu quả năng lượng thêm 25% so với việc sử dụng các máy GPU mới nhất trong AWS. Chúng tôi rất vui mừng được tận dụng thế hệ Chip AI AWS mới nhất, Trainium2, để tiếp tục cung cấp cho khách hàng hiệu năng tốt nhất với chi phí thấp nhất. - Yoshiaki Umetsu, Giám đốc Trung tâm phát triển công nghệ kỹ thuật số, Ricoh
PyTorch
 Điều tôi thích nhất về thư viện AWS Neuron NxD Inference là sự tích hợp liền mạch của thư viện này với các mô hình PyTorch. Cách tiếp cận của NxD rất đơn giản và thân thiện với người dùng. Nhóm của chúng tôi đã có thể tích hợp các mô hình HuggingFace PyTorch mà chỉ cần thay đổi mã tối thiểu trong khung thời gian ngắn. Việc kích hoạt các tính năng nâng cao như Phân nhóm liên tục và Giải mã suy đoán rất đơn giản. Sự dễ dàng trong sử dụng này giúp nâng cao năng suất của nhà phát triển, cho phép các nhóm tập trung nhiều hơn vào đổi mới và ít hơn vào các thách thức tích hợp. - Hamid Shojanazeri, Trưởng bộ phận Kỹ thuật đối tác PyTorch, Meta
Điều tôi thích nhất về thư viện AWS Neuron NxD Inference là sự tích hợp liền mạch của thư viện này với các mô hình PyTorch. Cách tiếp cận của NxD rất đơn giản và thân thiện với người dùng. Nhóm của chúng tôi đã có thể tích hợp các mô hình HuggingFace PyTorch mà chỉ cần thay đổi mã tối thiểu trong khung thời gian ngắn. Việc kích hoạt các tính năng nâng cao như Phân nhóm liên tục và Giải mã suy đoán rất đơn giản. Sự dễ dàng trong sử dụng này giúp nâng cao năng suất của nhà phát triển, cho phép các nhóm tập trung nhiều hơn vào đổi mới và ít hơn vào các thách thức tích hợp. - Hamid Shojanazeri, Trưởng bộ phận Kỹ thuật đối tác PyTorch, Meta
Refact.ai
 Refact.ai cung cấp các công cụ AI toàn diện như tự động hoàn thành mã được Retrieval-Augmented Generation (RAG) hỗ trợ, cung cấp đề xuất chính xác hơn và trò chuyện có nhận thức đến ngữ cảnh sử dụng cả mô hình độc quyền lẫn mã nguồn mở. Khách hàng đã chứng kiến hiệu năng cao hơn đến 20% và mã thông báo trên mỗi USD cao hơn 1,5 lần với các phiên bản EC2 Inf2 so với phiên bản EC2 G5. Khả năng tinh chỉnh của Refact.ai nâng cao hơn nữa khả năng hiểu và thích ứng với cơ sở mã và môi trường riêng của tổ chức của họ. Chúng tôi cũng rất vui mừng được cung cấp các tính năng của Trainium2, điều này sẽ mang lại quá trình xử lý nhanh hơn, hiệu quả hơn cho quy trình làm việc của chúng tôi. Công nghệ tiên tiến này sẽ cho phép khách hàng của chúng tôi đẩy nhanh quy trình phát triển phần mềm của mình, bằng cách tăng năng suất của nhà phát triển trong khi vẫn duy trì các tiêu chuẩn bảo mật nghiêm ngặt cho cơ sở mã của họ. - Oleg Klimov, Giám đốc điều hành & Nhà sáng lập, Refact.ai
Refact.ai cung cấp các công cụ AI toàn diện như tự động hoàn thành mã được Retrieval-Augmented Generation (RAG) hỗ trợ, cung cấp đề xuất chính xác hơn và trò chuyện có nhận thức đến ngữ cảnh sử dụng cả mô hình độc quyền lẫn mã nguồn mở. Khách hàng đã chứng kiến hiệu năng cao hơn đến 20% và mã thông báo trên mỗi USD cao hơn 1,5 lần với các phiên bản EC2 Inf2 so với phiên bản EC2 G5. Khả năng tinh chỉnh của Refact.ai nâng cao hơn nữa khả năng hiểu và thích ứng với cơ sở mã và môi trường riêng của tổ chức của họ. Chúng tôi cũng rất vui mừng được cung cấp các tính năng của Trainium2, điều này sẽ mang lại quá trình xử lý nhanh hơn, hiệu quả hơn cho quy trình làm việc của chúng tôi. Công nghệ tiên tiến này sẽ cho phép khách hàng của chúng tôi đẩy nhanh quy trình phát triển phần mềm của mình, bằng cách tăng năng suất của nhà phát triển trong khi vẫn duy trì các tiêu chuẩn bảo mật nghiêm ngặt cho cơ sở mã của họ. - Oleg Klimov, Giám đốc điều hành & Nhà sáng lập, Refact.ai
Karakuri Inc.
 KARAKURI xây dựng các công cụ AI để cải thiện hiệu quả hỗ trợ khách hàng dựa trên web và đơn giản hóa trải nghiệm của khách hàng. Các công cụ này bao gồm chatbot AI được trang bị các chức năng AI tạo sinh, công cụ tập trung Câu hỏi thường gặp và công cụ phản hồi email, tất cả đều cải thiện hiệu quả và chất lượng hỗ trợ khách hàng. Sử dụng AWS Trainium, chúng tôi đã thành công trong việc đào tạo KARAKURI LM 8x7B Chat v0.1. Đối với các công ty khởi nghiệp như chúng tôi, chúng tôi cần tối ưu hóa thời gian xây dựng cũng như chi phí cần thiết để đào tạo LLM. Với sự hỗ trợ của AWS Trainium và Đội ngũ AWS, chúng tôi đã có thể phát triển LLM cấp độ thực tế trong một khoảng thời gian ngắn. Ngoài ra, bằng cách áp dụng AWS Inferentia, chúng tôi đã có thể xây dựng một dịch vụ suy luận nhanh chóng và tiết kiệm chi phí. Chúng tôi được tiếp thêm sức mạnh với Trainium2 vì chip này sẽ cách mạng hóa quá trình đào tạo của chúng tôi, giảm gấp đôi thời gian đào tạo và nâng hiệu quả lên một tầm cao mới! - Tomofumi Nakayama, Nhà đồng sáng lập, Karakuri Inc.
KARAKURI xây dựng các công cụ AI để cải thiện hiệu quả hỗ trợ khách hàng dựa trên web và đơn giản hóa trải nghiệm của khách hàng. Các công cụ này bao gồm chatbot AI được trang bị các chức năng AI tạo sinh, công cụ tập trung Câu hỏi thường gặp và công cụ phản hồi email, tất cả đều cải thiện hiệu quả và chất lượng hỗ trợ khách hàng. Sử dụng AWS Trainium, chúng tôi đã thành công trong việc đào tạo KARAKURI LM 8x7B Chat v0.1. Đối với các công ty khởi nghiệp như chúng tôi, chúng tôi cần tối ưu hóa thời gian xây dựng cũng như chi phí cần thiết để đào tạo LLM. Với sự hỗ trợ của AWS Trainium và Đội ngũ AWS, chúng tôi đã có thể phát triển LLM cấp độ thực tế trong một khoảng thời gian ngắn. Ngoài ra, bằng cách áp dụng AWS Inferentia, chúng tôi đã có thể xây dựng một dịch vụ suy luận nhanh chóng và tiết kiệm chi phí. Chúng tôi được tiếp thêm sức mạnh với Trainium2 vì chip này sẽ cách mạng hóa quá trình đào tạo của chúng tôi, giảm gấp đôi thời gian đào tạo và nâng hiệu quả lên một tầm cao mới! - Tomofumi Nakayama, Nhà đồng sáng lập, Karakuri Inc.
Stockmark Inc.
 Với sứ mệnh “đổi mới cơ chế tạo giá trị và thúc đẩy nhân loại”, Stockmark giúp nhiều công ty tạo ra và xây dựng các doanh nghiệp sáng tạo bằng cách cung cấp công nghệ xử lý ngôn ngữ tự nhiên tiên tiến. Dịch vụ phân tích và thu thập dữ liệu mới của Stockmark có tên Anews và SAT, một dịch vụ cấu trúc dữ liệu giúp cải thiện đáng kể việc sử dụng AI tạo sinh bằng cách tổ chức tất cả các dạng thông tin được lưu trữ trong một tổ chức, khiến chúng tôi phải suy nghĩ lại về cách chúng tôi xây dựng và triển khai các mô hình để hỗ trợ các sản phẩm này. Với 256 bộ tăng tốc Trainium, chúng tôi đã phát triển và phát hành stockmark-13b, một mô hình ngôn ngữ lớn với 13 tỷ tham số, được đào tạo trước từ đầu trên một tập dữ liệu kho dữ liệu Nhật Bản gồm 220 tỷ mã thông báo. Các phiên bản Trn1 đã giúp chúng tôi giảm 20% chi phí đào tạo. Tận dụng Trainium, chúng tôi đã phát triển thành công một LLM có thể trả lời các câu hỏi kinh doanh quan trọng cho các chuyên gia với độ chính xác và tốc độ chưa từng có. Thành tựu này đặc biệt đáng chú ý vì thách thức to lớn mà các công ty phải đối mặt trong việc đảm bảo nguồn lực tính toán tương xứng để phát triển mô hình. Với tốc độ ấn tượng và giảm chi phí của phiên bản Trn1, chúng tôi rất vui mừng khi thấy những lợi ích bổ sung mà Trainium2 sẽ mang lại cho quy trình làm việc và khách hàng của chúng tôi. - Kosuke Arima, CTO và Nhà đồng sáng lập, Stockmark Inc.
Với sứ mệnh “đổi mới cơ chế tạo giá trị và thúc đẩy nhân loại”, Stockmark giúp nhiều công ty tạo ra và xây dựng các doanh nghiệp sáng tạo bằng cách cung cấp công nghệ xử lý ngôn ngữ tự nhiên tiên tiến. Dịch vụ phân tích và thu thập dữ liệu mới của Stockmark có tên Anews và SAT, một dịch vụ cấu trúc dữ liệu giúp cải thiện đáng kể việc sử dụng AI tạo sinh bằng cách tổ chức tất cả các dạng thông tin được lưu trữ trong một tổ chức, khiến chúng tôi phải suy nghĩ lại về cách chúng tôi xây dựng và triển khai các mô hình để hỗ trợ các sản phẩm này. Với 256 bộ tăng tốc Trainium, chúng tôi đã phát triển và phát hành stockmark-13b, một mô hình ngôn ngữ lớn với 13 tỷ tham số, được đào tạo trước từ đầu trên một tập dữ liệu kho dữ liệu Nhật Bản gồm 220 tỷ mã thông báo. Các phiên bản Trn1 đã giúp chúng tôi giảm 20% chi phí đào tạo. Tận dụng Trainium, chúng tôi đã phát triển thành công một LLM có thể trả lời các câu hỏi kinh doanh quan trọng cho các chuyên gia với độ chính xác và tốc độ chưa từng có. Thành tựu này đặc biệt đáng chú ý vì thách thức to lớn mà các công ty phải đối mặt trong việc đảm bảo nguồn lực tính toán tương xứng để phát triển mô hình. Với tốc độ ấn tượng và giảm chi phí của phiên bản Trn1, chúng tôi rất vui mừng khi thấy những lợi ích bổ sung mà Trainium2 sẽ mang lại cho quy trình làm việc và khách hàng của chúng tôi. - Kosuke Arima, CTO và Nhà đồng sáng lập, Stockmark Inc.
Brave
 Brave là một trình duyệt và công cụ tìm kiếm độc lập dành riêng cho việc ưu tiên quyền riêng tư và bảo mật của người dùng. Với hơn 70 triệu người dùng, chúng tôi cung cấp các biện pháp bảo vệ hàng đầu trong ngành làm cho Web an toàn hơn và thân thiện hơn. Không giống như các nền tảng khác đã không còn áp dụng cách tiếp cận lấy người dùng làm trung tâm, Brave vẫn cam kết đặt quyền riêng tư, bảo mật và tiện lợi lên hàng đầu. Các tính năng chính bao gồm chặn các tập lệnh và trình theo dõi có hại, tóm tắt trang hỗ trợ AI được cung cấp bởi LLM, dịch vụ VPN tích hợp và hơn thế nữa. Chúng tôi liên tục nỗ lực nâng cao tốc độ và hiệu quả chi phí cho các dịch vụ tìm kiếm và mô hình AI của mình. Để hỗ trợ mục tiêu này, chúng tôi rất phấn khích được tận dụng các khả năng mới nhất của chip AI AWS, bao gồm Trainium2, để cải thiện trải nghiệm người dùng trong quá trình chúng tôi điều chỉnh quy mô để xử lý hàng tỷ truy vấn tìm kiếm hàng tháng. - Subu Sathyanarayana, Phó Giám đốc kỹ thuật, Brave Software
Brave là một trình duyệt và công cụ tìm kiếm độc lập dành riêng cho việc ưu tiên quyền riêng tư và bảo mật của người dùng. Với hơn 70 triệu người dùng, chúng tôi cung cấp các biện pháp bảo vệ hàng đầu trong ngành làm cho Web an toàn hơn và thân thiện hơn. Không giống như các nền tảng khác đã không còn áp dụng cách tiếp cận lấy người dùng làm trung tâm, Brave vẫn cam kết đặt quyền riêng tư, bảo mật và tiện lợi lên hàng đầu. Các tính năng chính bao gồm chặn các tập lệnh và trình theo dõi có hại, tóm tắt trang hỗ trợ AI được cung cấp bởi LLM, dịch vụ VPN tích hợp và hơn thế nữa. Chúng tôi liên tục nỗ lực nâng cao tốc độ và hiệu quả chi phí cho các dịch vụ tìm kiếm và mô hình AI của mình. Để hỗ trợ mục tiêu này, chúng tôi rất phấn khích được tận dụng các khả năng mới nhất của chip AI AWS, bao gồm Trainium2, để cải thiện trải nghiệm người dùng trong quá trình chúng tôi điều chỉnh quy mô để xử lý hàng tỷ truy vấn tìm kiếm hàng tháng. - Subu Sathyanarayana, Phó Giám đốc kỹ thuật, Brave Software
Anyscale
 Anyscale là công ty đứng sau Ray, một Công cụ điện toán AI cung cấp năng lượng cho ML và các sáng kiến AI tạo sinh cho Doanh nghiệp. Với nền tảng AI hợp nhất của Anyscale được điều khiển bởi RayTurbo, khách hàng nhận thấy khả năng xử lý dữ liệu nhanh hơn đến 4,5 lần, chi phí suy luận hàng loạt thấp hơn 10 lần với LLM, khả năng điều chỉnh quy mô nhanh hơn 5 lần, khả năng lặp lại nhanh hơn 12 lần và tiết kiệm 50% chi phí cho suy luận mô hình trực tuyến bằng cách tối ưu hóa việc sử dụng tài nguyên. Tại Anyscale, chúng tôi cam kết trao quyền cho các doanh nghiệp những công cụ tốt nhất để điều chỉnh quy mô khối lượng công việc AI một cách hiệu quả và tiết kiệm chi phí. Với khả năng hỗ trợ thuần cho các chip AWS Trainium và Inferentia, được hỗ trợ bởi thời gian hoạt động RayTurbo của chúng tôi, khách hàng có quyền truy cập vào các tùy chọn hiệu suất cao, tiết kiệm chi phí để phục vụ và đào tạo mô hình. Giờ đây, chúng tôi rất vui mừng được hợp tác với AWS trên Trainium2, mở ra cơ hội mới cho khách hàng đổi mới nhanh chóng và cung cấp trải nghiệm AI chuyển đổi hiệu suất cao trên quy mô lớn. - Robert Nishihara, Nhà đồng sáng lập, Anyscale
Anyscale là công ty đứng sau Ray, một Công cụ điện toán AI cung cấp năng lượng cho ML và các sáng kiến AI tạo sinh cho Doanh nghiệp. Với nền tảng AI hợp nhất của Anyscale được điều khiển bởi RayTurbo, khách hàng nhận thấy khả năng xử lý dữ liệu nhanh hơn đến 4,5 lần, chi phí suy luận hàng loạt thấp hơn 10 lần với LLM, khả năng điều chỉnh quy mô nhanh hơn 5 lần, khả năng lặp lại nhanh hơn 12 lần và tiết kiệm 50% chi phí cho suy luận mô hình trực tuyến bằng cách tối ưu hóa việc sử dụng tài nguyên. Tại Anyscale, chúng tôi cam kết trao quyền cho các doanh nghiệp những công cụ tốt nhất để điều chỉnh quy mô khối lượng công việc AI một cách hiệu quả và tiết kiệm chi phí. Với khả năng hỗ trợ thuần cho các chip AWS Trainium và Inferentia, được hỗ trợ bởi thời gian hoạt động RayTurbo của chúng tôi, khách hàng có quyền truy cập vào các tùy chọn hiệu suất cao, tiết kiệm chi phí để phục vụ và đào tạo mô hình. Giờ đây, chúng tôi rất vui mừng được hợp tác với AWS trên Trainium2, mở ra cơ hội mới cho khách hàng đổi mới nhanh chóng và cung cấp trải nghiệm AI chuyển đổi hiệu suất cao trên quy mô lớn. - Robert Nishihara, Nhà đồng sáng lập, Anyscale
Datadog
 Datadog, nền tảng bảo mật và khả năng quan sát cho các ứng dụng đám mây, cung cấp tính năng Giám sát AWS Trainium và Inferentia cho khách hàng để tối ưu hóa hiệu suất mô hình, cải thiện hiệu quả và giảm chi phí. Khả năng tích hợp của Datadog cung cấp khả năng hiển thị đầy đủ các hoạt động ML và hiệu suất chip cơ sở, tạo điều kiện giải quyết vấn đề chủ động và điều chỉnh quy mô cơ sở hạ tầng liền mạch. Chúng tôi rất vui mừng được mở rộng quan hệ đối tác với AWS để ra mắt AWS Trainium2, giúp người dùng cắt giảm lên đến 50% chi phí cơ sở hạ tầng AI cũng như tăng hiệu suất đào tạo và triển khai mô hình. - Yrieix Garnier, Phó chủ tịch phụ trách Sản phẩm, Datadog
Datadog, nền tảng bảo mật và khả năng quan sát cho các ứng dụng đám mây, cung cấp tính năng Giám sát AWS Trainium và Inferentia cho khách hàng để tối ưu hóa hiệu suất mô hình, cải thiện hiệu quả và giảm chi phí. Khả năng tích hợp của Datadog cung cấp khả năng hiển thị đầy đủ các hoạt động ML và hiệu suất chip cơ sở, tạo điều kiện giải quyết vấn đề chủ động và điều chỉnh quy mô cơ sở hạ tầng liền mạch. Chúng tôi rất vui mừng được mở rộng quan hệ đối tác với AWS để ra mắt AWS Trainium2, giúp người dùng cắt giảm lên đến 50% chi phí cơ sở hạ tầng AI cũng như tăng hiệu suất đào tạo và triển khai mô hình. - Yrieix Garnier, Phó chủ tịch phụ trách Sản phẩm, Datadog
Hugging Face
 Hugging Face là nền tảng mở hàng đầu dành cho các nhà xây dựng AI, với hơn 2 triệu mô hình, tập dữ liệu và ứng dụng AI được chia sẻ bởi một cộng đồng gồm hơn 5 triệu nhà nghiên cứu, nhà khoa học dữ liệu, kỹ sư máy học và nhà phát triển phần mềm. Chúng tôi đã hợp tác với AWS trong vài năm qua, giúp các nhà phát triển dễ dàng trải nghiệm hiệu suất và lợi ích chi phí của AWS Inferentia và Trainium thông qua thư viện mã nguồn mở Optimum Neuron, được tích hợp trong Điểm cuối suy luận Hugging Face và hiện được tối ưu hóa trong dịch vụ tự triển khai HUGS mới của chúng tôi, có sẵn trên AWS Marketplace. Với sự ra mắt của Trainium2, người dùng của chúng tôi sẽ được tiếp cận hiệu suất cao hơn nữa để phát triển và triển khai các mô hình nhanh hơn. - Jeff Boudier, Giám đốc sản phẩm, Hugging Face
Hugging Face là nền tảng mở hàng đầu dành cho các nhà xây dựng AI, với hơn 2 triệu mô hình, tập dữ liệu và ứng dụng AI được chia sẻ bởi một cộng đồng gồm hơn 5 triệu nhà nghiên cứu, nhà khoa học dữ liệu, kỹ sư máy học và nhà phát triển phần mềm. Chúng tôi đã hợp tác với AWS trong vài năm qua, giúp các nhà phát triển dễ dàng trải nghiệm hiệu suất và lợi ích chi phí của AWS Inferentia và Trainium thông qua thư viện mã nguồn mở Optimum Neuron, được tích hợp trong Điểm cuối suy luận Hugging Face và hiện được tối ưu hóa trong dịch vụ tự triển khai HUGS mới của chúng tôi, có sẵn trên AWS Marketplace. Với sự ra mắt của Trainium2, người dùng của chúng tôi sẽ được tiếp cận hiệu suất cao hơn nữa để phát triển và triển khai các mô hình nhanh hơn. - Jeff Boudier, Giám đốc sản phẩm, Hugging Face
Lightning AI
 Lightning AI, đơn vị tạo ra PyTorch Lightning và Lightning Studios cung cấp nền tảng phát triển AI toàn diện trực quan nhất cho AI cấp doanh nghiệp. Lightning cung cấp các công cụ mã đầy đủ, ít cần viết mã và không cần viết mã để xây dựng các tác tử, ứng dụng AI và giải pháp AI tạo sinh, nhanh như chớp. Được thiết kế linh hoạt, chạy liền mạch trên đám mây của bạn hoặc của chúng tôi, tận dụng chuyên môn và hỗ trợ của cộng đồng hùng mạnh hơn 3 triệu nhà phát triển. Lightning hiện hỗ trợ thuần cho Trainium và Inferentia, các Chip AI của AWS, được tích hợp trên cả Lightning Studios lẫn các công cụ mã nguồn mở của chúng tôi như PyTorch Lightning, Fabric và LitServe. Điều này mang lại cho người dùng khả năng liền mạch trong việc đào tạo trước, tinh chỉnh và triển khai ở quy mô lớn – tối ưu hóa chi phí, tính khả dụng và hiệu suất mà không tốn chi phí chuyển đổi, cũng như lợi ích về hiệu suất và chi phí từ Chip AI của AWS, bao gồm thế hệ chip Trainium2 mới nhất, mang lại hiệu suất cao hơn với chi phí thấp hơn. - Luca Antiga, CTO, Lightning AI
Lightning AI, đơn vị tạo ra PyTorch Lightning và Lightning Studios cung cấp nền tảng phát triển AI toàn diện trực quan nhất cho AI cấp doanh nghiệp. Lightning cung cấp các công cụ mã đầy đủ, ít cần viết mã và không cần viết mã để xây dựng các tác tử, ứng dụng AI và giải pháp AI tạo sinh, nhanh như chớp. Được thiết kế linh hoạt, chạy liền mạch trên đám mây của bạn hoặc của chúng tôi, tận dụng chuyên môn và hỗ trợ của cộng đồng hùng mạnh hơn 3 triệu nhà phát triển. Lightning hiện hỗ trợ thuần cho Trainium và Inferentia, các Chip AI của AWS, được tích hợp trên cả Lightning Studios lẫn các công cụ mã nguồn mở của chúng tôi như PyTorch Lightning, Fabric và LitServe. Điều này mang lại cho người dùng khả năng liền mạch trong việc đào tạo trước, tinh chỉnh và triển khai ở quy mô lớn – tối ưu hóa chi phí, tính khả dụng và hiệu suất mà không tốn chi phí chuyển đổi, cũng như lợi ích về hiệu suất và chi phí từ Chip AI của AWS, bao gồm thế hệ chip Trainium2 mới nhất, mang lại hiệu suất cao hơn với chi phí thấp hơn. - Luca Antiga, CTO, Lightning AI
Domino Data Lab
 Domino điều phối tất cả các tạo tác khoa học dữ liệu, bao gồm cơ sở hạ tầng, dữ liệu và dịch vụ trên AWS trên nhiều môi trường – bổ sung cho Amazon SageMaker các tính năng quản trị và cộng tác để hỗ trợ các đội ngũ khoa học dữ liệu trong doanh nghiệp. Domino được cung cấp thông qua AWS Marketplace dưới dạng SaaS hoặc tự quản lý. Các doanh nghiệp hàng đầu phải cân bằng giữa sự phức tạp kỹ thuật, chi phí và quản trị, nắm vững các tùy chọn AI mở rộng để đạt được lợi thế cạnh tranh. Tại Domino, chúng tôi cam kết cung cấp cho khách hàng khả năng tiếp cận các công nghệ tiên tiến. Vì điện toán là một rào cản cho rất nhiều sự đổi mới mang tính đột phá, chúng tôi tự hào cung cấp cho khách hàng khả năng tiếp cận Trainium2 để họ có thể đào tạo và triển khai các mô hình với hiệu năng cao hơn, chi phí thấp hơn và khả năng tiết kiệm năng lượng tốt hơn. - Nick Elprin, Giám đốc điều hành kiêm Người đồng sáng lập, Domino Data Lab
Domino điều phối tất cả các tạo tác khoa học dữ liệu, bao gồm cơ sở hạ tầng, dữ liệu và dịch vụ trên AWS trên nhiều môi trường – bổ sung cho Amazon SageMaker các tính năng quản trị và cộng tác để hỗ trợ các đội ngũ khoa học dữ liệu trong doanh nghiệp. Domino được cung cấp thông qua AWS Marketplace dưới dạng SaaS hoặc tự quản lý. Các doanh nghiệp hàng đầu phải cân bằng giữa sự phức tạp kỹ thuật, chi phí và quản trị, nắm vững các tùy chọn AI mở rộng để đạt được lợi thế cạnh tranh. Tại Domino, chúng tôi cam kết cung cấp cho khách hàng khả năng tiếp cận các công nghệ tiên tiến. Vì điện toán là một rào cản cho rất nhiều sự đổi mới mang tính đột phá, chúng tôi tự hào cung cấp cho khách hàng khả năng tiếp cận Trainium2 để họ có thể đào tạo và triển khai các mô hình với hiệu năng cao hơn, chi phí thấp hơn và khả năng tiết kiệm năng lượng tốt hơn. - Nick Elprin, Giám đốc điều hành kiêm Người đồng sáng lập, Domino Data Lab
Bắt đầu
Hỗ trợ SageMaker cho các phiên bản Trn2 sắp ra mắt. Bạn sẽ có thể dễ dàng đào tạo các mô hình trên phiên bản Trn2 bằng cách sử dụng Amazon SageMaker HyperPod, tính năng này cung cấp cụm tính toán bền bỉ, hiệu suất đào tạo được tối ưu hóa và sử dụng hiệu quả các tài nguyên điện toán, mạng và bộ nhớ cơ sở. Bạn cũng có thể điều chỉnh quy mô triển khai mô hình của mình trên phiên bản Trn2 bằng cách sử dụng SageMaker để quản lý mô hình hiệu quả hơn trong sản xuất và giảm gánh nặng hoạt động.
AMI học sâu của AWS (DLAMI) cung cấp cơ sở hạ tầng và công cụ cho người thực hành và nghiên cứu học sâu (DL) để tăng tốc học sâu trên AWS ở mọi quy mô. Trình điều khiển AWS Neuron được cấu hình sẵn trong DLAMI để đào tạo các mô hình DL của bạn một cách tối ưu trên các phiên bản Trn2.
Hỗ trợ Bộ chứa học sâu cho các phiên bản Trn2 sắp ra mắt. Giờ đây, bạn có thể triển khai phiên bản Trn2 trong Amazon Elastic Kubernetes Service (Amazon EKS), một dịch vụ Kubernetes được quản lý hoàn toàn, cũng như trong Amazon Elastic Container Service (Amazon ECS), một dịch vụ điều phối bộ chứa được quản lý hoàn toàn. Neuron cũng được cài đặt sẵn trong Bộ chứa học sâu của AWS. Để tìm hiểu thêm về việc chạy các bộ chứa trên phiên bản Trn2, hãy xem Hướng dẫn về bộ chứa Neuron.
Chi tiết sản phẩm
|
Kích thước phiên bản
|
Được cung cấp trong EC2 UltraServers
|
Chip Trainium2
|
Bộ nhớ của trình tăng tốc
|
vCPU
|
Bộ nhớ (TB)
|
Dung lượng lưu trữ của phiên bản (TB)
|
Băng thông mạng (Tbps)
|
Băng thông EBS (Gbps)
|
|---|---|---|---|---|---|---|---|---|
|
Trn2.3xlarge
|
Không |
1 |
96 GB |
12 |
128 GB |
1x ổ SSD NVMe 470 GB
|
0,2 |
5 |
|
trn2.48xlarge
|
Không
|
16
|
1,5 TB
|
192
|
2 TB
|
4 x 1.92 SSD NVMe
|
3,2
|
80
|
|
trn2u.48xlarge
|
Có |
16
|
1,5 TB
|
192
|
2 TB
|
4 x 1.92 SSD NVMe
|
3,2
|
80
|