このコンテンツはいかがでしたか?
スタートアップ向けの生成系 AI アプリケーションの構築
最近の生成系 AI の進歩により、スタートアップが迅速に構築、拡大、革新するのに役立つツールの水準が高まっています。特にトランスフォーマーニューラルネットワークアーキテクチャによる機械学習 (ML) の普及と民主化は、テクノロジーにおけるエキサイティングな節目です。適切なツールがあれば、スタートアップは生成系 AI のメリットを顧客にもたらすために、新しいアイデアを構築したり、既存の製品を方向転換したりできます。
スタートアップ向けの生成系 AI アプリケーションを構築する準備はできていますか? まず、生成系 AI アプリケーションを構築するための概念、コアアイデア、一般的なアプローチを確認しましょう。
生成系 AI アプリケーションとは?
生成系 AIアプリケーションは AI の一種をベースにしたプログラムで、会話、ストーリー、画像、動画、コード、音楽など、新しいコンテンツやアイデアを生み出すことができます。すべての AI アプリケーションと同様に、生成系 AI アプリケーションも、大量のデータで事前にトレーニングされた ML モデルを使用しており、一般に基盤モデル (FM) と呼ばれています。
生成系 AI アプリケーションの例としては、Amazon CodeWhisperer があります。これは、デベロッパーが統合開発環境 (IDE) で全行コードやフル機能コードの提案を行うことで、デベロッパーがアプリケーションをより迅速かつ安全に構築できるようにする AI コーディングコンパニオンです。CodeWhisperer は数十億行のコードでトレーニングされており、コメントや既存のコードに基づいて、スニペットからフル機能までのコード候補を瞬時に生成できます。スタートアップは CodeWhisperer Professional Tier で AWS Activate クレジットを使用することも、無料で使用できる Individual Tier から始めることもできます。
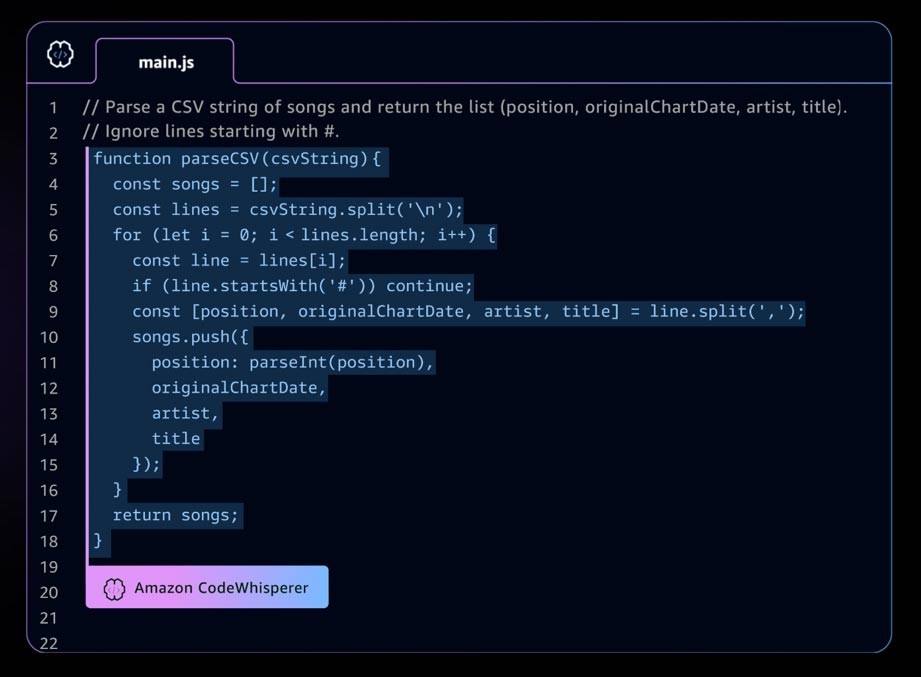
急速に発展する生成系 AI ランドスケープ
生成系 AI のスタートアップや、生成系 AI の導入を簡素化するツールを開発しているスタートアップ企業で急成長が起こっています。言語モデルを利用してアプリケーションを開発するためのオープンソースのフレームワークである LangChain のようなツールにより、生成系 AI をより幅広い組織が利用できるようになり、導入が早まるでしょう。これらのツールには、プロンプトエンジニアリング、拡張サービス (埋め込みツールやベクトルデータベースなど)、モデル監視、モデル品質測定、ガードレール、データ注釈、人間のフィードバックによる強化学習 (RLHF) などが含まれます。
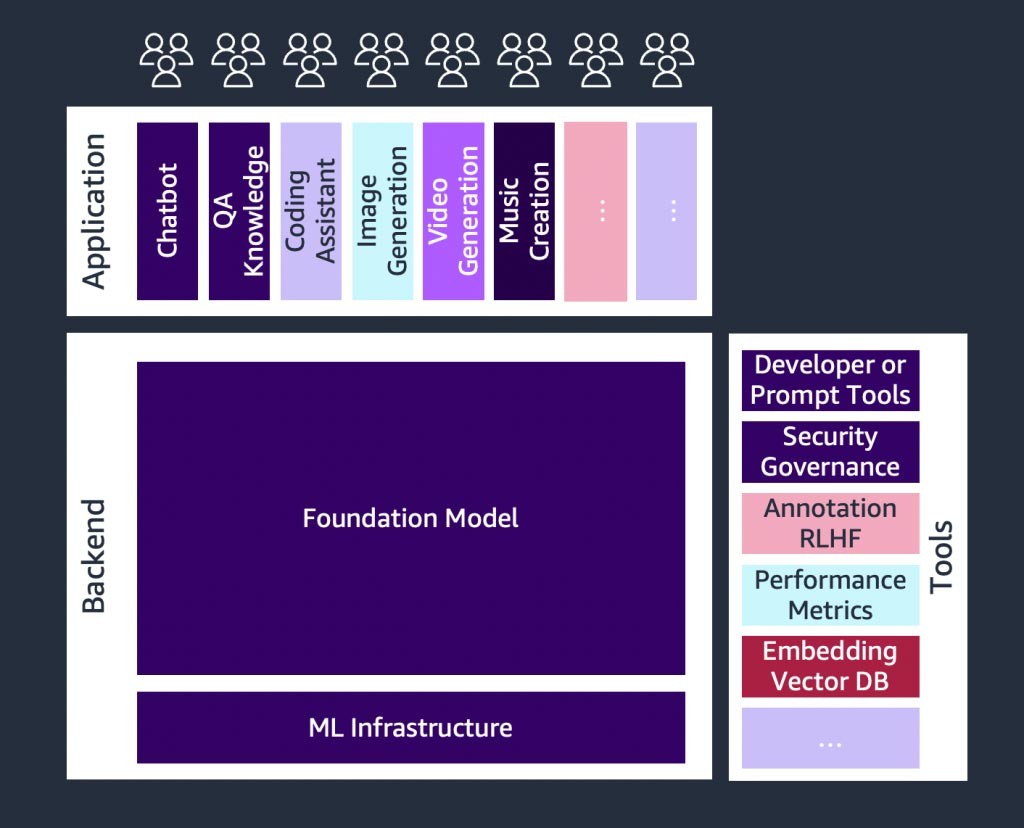
基盤モデルのご紹介
生成系 AI アプリケーションやツールにとって中核となるのは基盤モデルです。基盤モデルは強力な機械学習モデルの一種で、ダウンストリームのさまざまなタスクを実行するために膨大な量のデータを事前にトレーニングできるという点で差別化されています。これらのタスクには、テキスト生成、要約、情報抽出、Q&A、チャットボットなどがあります。これとは対照的に、従来の ML モデルは、データセットから特定のタスクを実行するようにトレーニングされています。
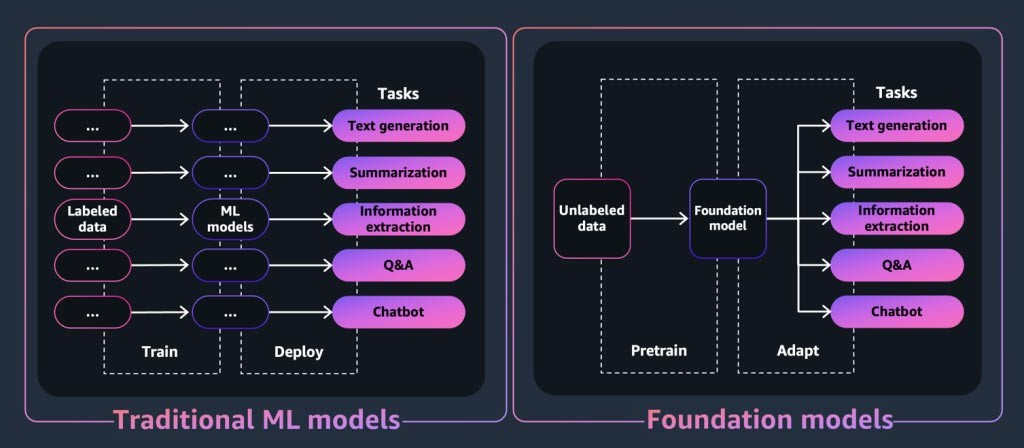
では、基盤モデルはどのようにして生成系 AI アプリケーションの定評のある出力を「生成」するのでしょうか。このような能力は、パターンや関係を学習することで FM がシーケンス内の次の 1 つまたは複数の項目を予測したり、新しい項目を生成したりできるようにすることで実現しています。
- テキスト生成モデルでは、FM は次の単語、次のフレーズ、または質問への回答を出力します。
- 画像生成モデルでは、FM はテキストに基づいて画像を出力します。
- 画像が入力の場合、FM は次の関連するまたはアップスケールされた画像、アニメーション、または 3D 画像を出力します。
いずれの場合も、モデルは「プロンプト」から派生したシードベクトルから始まります。プロンプトは、モデルが実行しなければならないタスクを記述します。プロンプトの質と詳細 (「コンテキスト」とも呼ばれる) によって、出力の質と関連性が決まります。
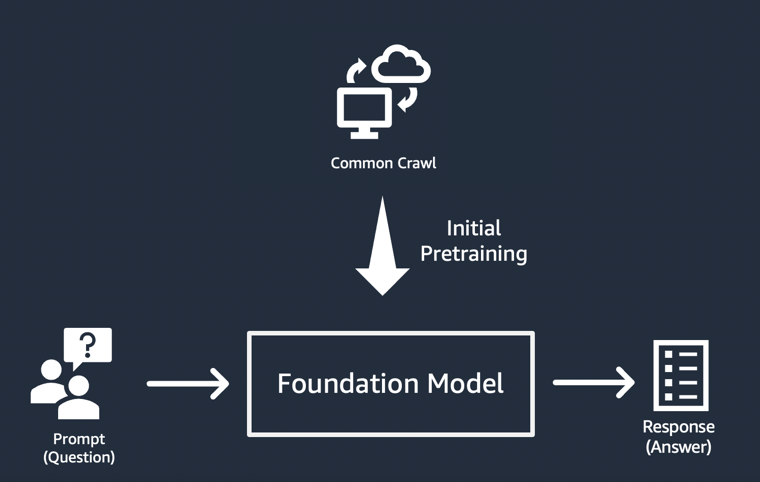
生成系 AI アプリケーションの最も簡素な実装
生成系 AI アプリケーションを構築する最も簡単なアプローチは、命令チューニングされた基盤モデルを使用し、ゼロショット学習または数ショット学習を使用して意味のあるプロンプト (「プロンプトエンジニアリング」) を提供することです。命令チューニングされたモデル (FLAN T5 XXL、Open-Llama、Falcon 40B Instruct など) では、関連するタスクや概念の理解を用いてプロンプトに対する予測を生成します。プロンプトの例をいくつかご紹介します。
ゼロショット学習
Title: \”University has new facility coming up“\\n Given the above title of an imaginary article, imagine the article.\n
数ショット学習
This is awesome! // Positive
This is bad! // Negative
That movie was hopeless! // Negative
What a horrible show! //
RESPONSE: Negative
特にスタートアップは、命令チューニングされたモデルを使用することで迅速なデプロイ、最小限のデータニーズ、コストの最適化というメリットが得られます。
基盤モデルを選択する際の考慮事項について詳しくは、「スタートアップに最適な基盤モデルを選択する」を参照してください。
基盤モデルのカスタマイズ
命令チューニングされたモデルでプロンプトエンジニアリングを使用しても、すべてのユースケースに対応できるわけではありません。スタートアップ向けに基盤モデルをカスタマイズする理由としては、次のようなものが考えられます。
- 基盤モデルへ特定のタスク (コード生成など) を追加する
- 自社独自のデータセットに基づきレスポンスを生成する
- モデルを事前にトレーニングしたものよりも質の高いデータセットから生成されたレスポンスを求める
- 事実に反する、または合理的でない出力である「ハルシネーション」を軽減する
基盤モデルをカスタマイズする一般的な手法は 3 つあります。
命令ベースの微調整
この手法では、基盤モデルをタスク固有のラベル付きデータセットに基づいて、特定のタスクを完了するようにトレーニングします。ラベル付きデータセットは、プロンプトとレスポンスのペアで構成されます。このカスタマイズ手法は、トレーニングに必要なデータセットや手順が少なくて済むため、最小限のデータセットで FM をすばやくカスタマイズしたいスタートアップにとって有益です。モデルのウェイトは、微調整するタスクまたはレイヤーに基づいて更新されます。
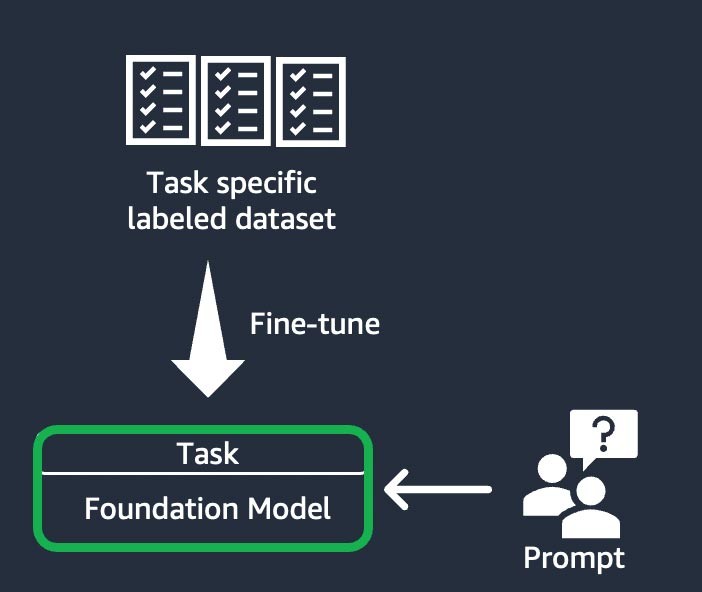
ドメイン適応 (「さらなる事前トレーニング」とも)
この手法では、ドメイン固有のラベル付けされていないデータから成る大きな「コーパス」 (一連のトレーニング資料) を使用して基盤モデルをトレーニングします (「自己教師あり学習」として知られる)。この手法は、既存の基盤モデルでは見られなかったドメイン固有の専門用語や統計データを含むユースケースに役立ちます。例えば、金融分野の独自データを扱う生成系 AI アプリケーションを構築するスタートアップは、カスタム語彙について FM にさらに事前トレーニングを行い、テキストをトークンと呼ばれる小さな単位に分解する「トークン化」を行うことでメリットが得られる可能性があります。
より高い品質を実現するために、このプロセスに人間のフィードバックによる強化学習 (RLHF) 手法を実装しているスタートアップもあります。さらに、特定のタスクを微調整するには、指示ベースの微調整も必要になります。これは他の方法に比べて費用と時間がかかる手法です。モデルのウェイトはすべてのレイヤーで更新されます。
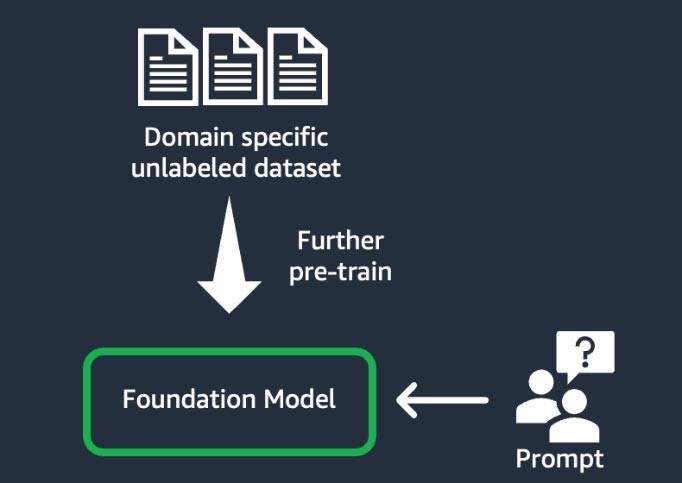
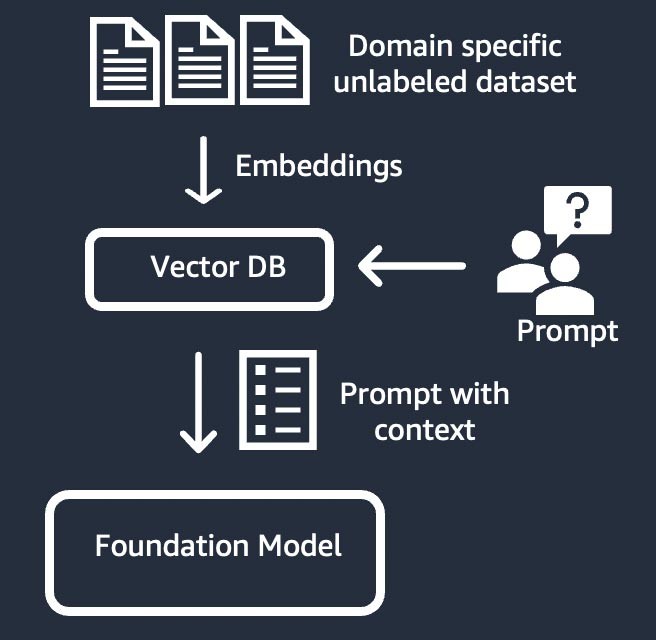
情報検索 (「検索拡張生成」または「RAG」とも)
この手法は、高密度ベクトル表現に基づく情報検索システムで基盤モデルを補強します。クローズドドメインの知識や独自データは、テキスト埋め込みプロセスを経てコーパスのベクトル表現を生成し、ベクトルデータベースに格納されます。ユーザークエリに基づくセマンティック検索の結果がプロンプトのコンテキストになります。基盤モデルを使用して、コンテキストを含むプロンプトに基づいてレスポンスを生成します。この手法では、基盤モデルのウェイトは更新されません。
生成系 AI アプリケーションのコンポーネント
上記のセクションでは、スタートアップが生成系 AIアプリケーションを構築する際に基盤モデルを使って採用できるさまざまなアプローチを学びました。それでは、このような基盤モデルがどのように生成系 AI アプリケーションの構築に必要な一般的な要素やコンポーネントの一部になっているかを確認しましょう。
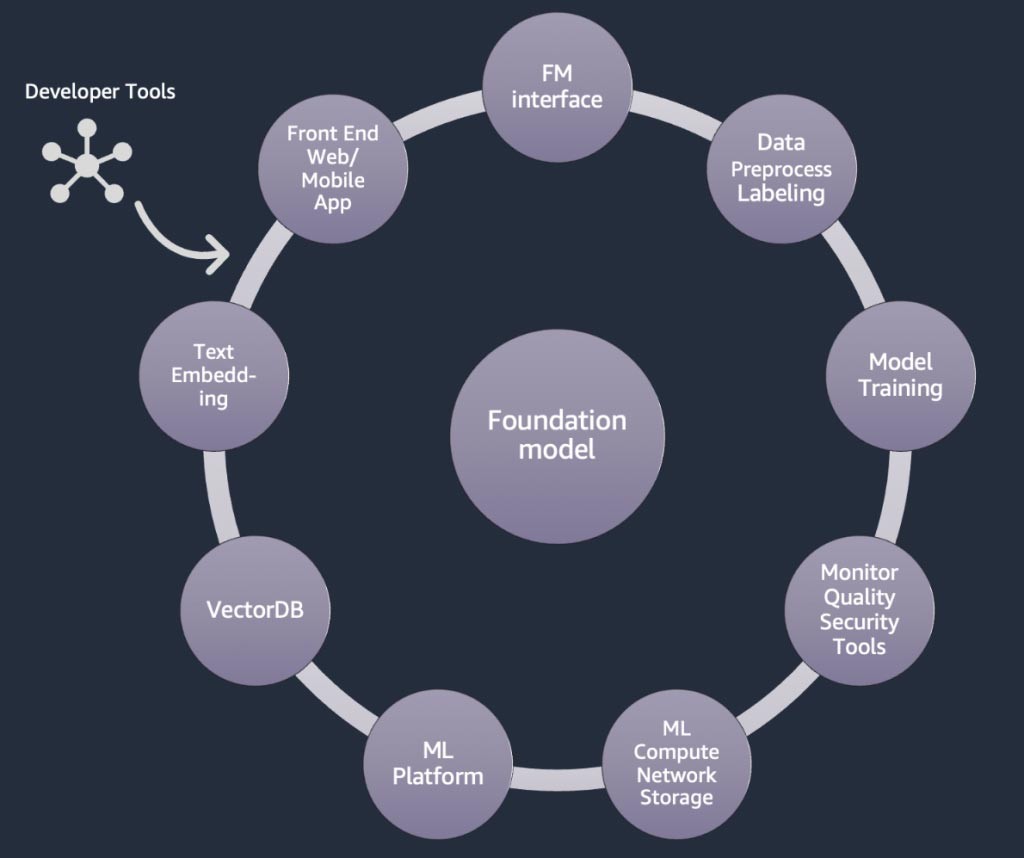
中核となるのは基盤モデル (中央) です。このブログで前述した最も簡単なアプローチでは、API (上) を介して基盤モデルにアクセスするウェブアプリケーションまたはモバイルアプリ (左上) が必要となります。この API は、モデルプロバイダーを介したマネージドサービスか、オープンソースまたは独自モデルによるセルフホスト型のどちらかです。セルフホスティングの場合、モデルをホストするために高速コンピューティングインスタンスで支援される機械学習プラットフォームが必要な場合があります。
RAG 手法では、テキスト埋め込みエンドポイントとベクトルデータベース (左と左下) を追加する必要があります。これらは両方とも API サービスとして提供されているか、セルフホスト型です。テキスト埋め込みエンドポイントは基盤モデルに支えられており、どの基盤モデルを選択するかは埋め込みロジックとトークン化のサポートの有無に左右されます。これらのコンポーネントはすべて、生成系 AI アプリケーションを開発するためのフレームワークを提供するデベロッパーツールを使用して相互に接続されます。
そして最後に、基盤モデルの微調整やさらなる事前トレーニングなどのカスタマイズ手法 (右) を選択する場合、データの前処理と注釈を支援するコンポーネント (右上) と、特定の高速コンピューティングインスタンスでトレーニングジョブを実行するための ML プラットフォーム (下) が必要です。一部のモデルプロバイダーは API ベースの微調整をサポートしているため、そのような場合は ML プラットフォームや基盤となるハードウェアについて心配する必要はありません。
カスタマイズする方法にかかわらず、監視、品質メトリクス、セキュリティツールを提供するコンポーネント (右下) を統合したい場合もあります。
生成系 AI アプリケーションの構築にはどの AWS サービスを使用すればよいですか?
以下の図 (図 9) は、各コンポーネントを対応する AWS サービスにマッピングしています。これらは、スタートアップがメリットを享受できると思われる AWS サービスを厳選したものですが、利用できる AWS サービスは他にもあります。
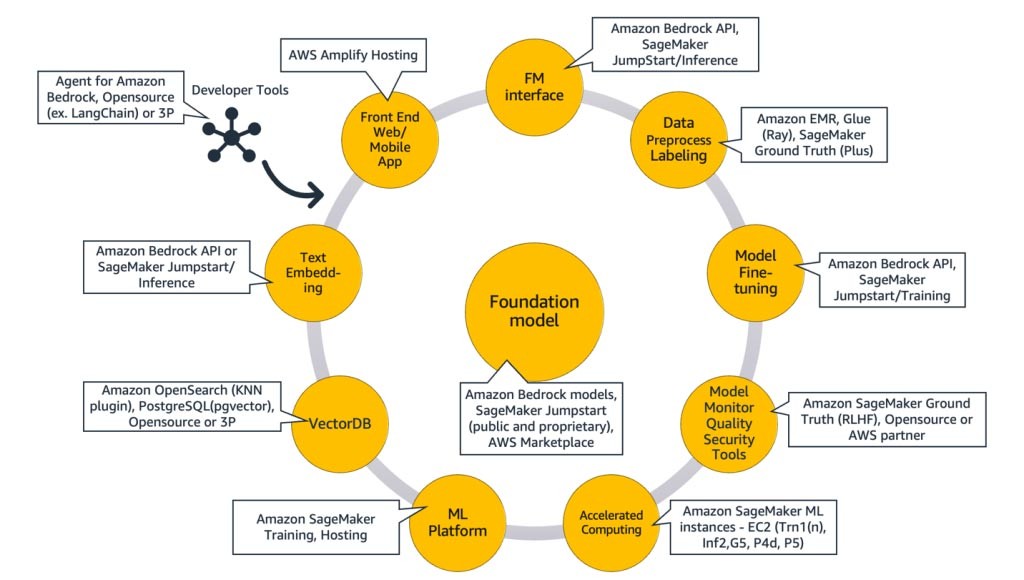
詳しく説明すると、まず AWS サービスを生成系 AI アプリケーションの共通コンポーネントにマッピングすることから始めます。次に、アプリケーションの実装に使用するアプローチに基づいて、図 9 の残りのコンポーネントに対応する AWS サービスについて説明します。
共通コンポーネント
生成系 AI アプリケーションの共通コンポーネントは、基盤モデル (FM) とそのインターフェイス、そしてオプションで機械学習 (ML) プラットフォームと高速コンピューティングです。これらは、AWS が提供するマネージドサービスを利用することで実現できます。
Amazon Bedrock (基盤モデルとそのインターフェイスコンポーネント)
Amazon Bedrock は、主要な AI スタートアップ (AI21 の Jurassic、Anthropic の Claude、Cohere の Command and Embedding、Stability の SDXL モデル) と Amazon (タイタンテキストおよび埋め込みモデル) の基盤モデルを API を介して利用できるフルマネージドサービスです。これにより、さまざまな FM から選択して、ユースケースに最適なモデルを見つけることができます。Amazon Bedrock では、一連の基盤モデルへの API またはサーバーレスアクセスが可能で、テキストの埋め込み、プロンプト/レスポンス、微調整 (一部のモデル) の 3 つの機能を利用できます。
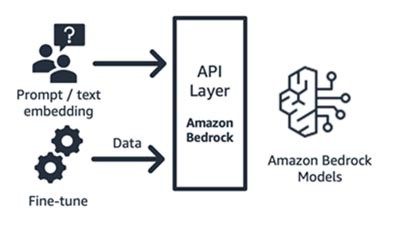
Amazon Bedrock は、選択した基盤モデルを中心に付加価値サービス (プロンプトエンジニアリング、検索拡張生成など) を構築しているアプリケーションやモデルの消費者向けスタートアップに最適です。その料金モデルは従量制で、通常は数百万トークンの処理単位で課金されます。Amazon Bedrock は一般公開されていますが、このブログで説明している機能の一部はプライベートプレビュー段階にあります。こちらから詳細をご覧ください。
Amazon SageMaker JumpStart (基盤モデルとそのインターフェイスコンポーネント)
AWS は Amazon SageMaker Jumpstart で生成系 AI 機能を提供しています。これは、公開されているモデルと独自のモデルの両方、クイックスタートソリューション、モデルをデプロイして微調整するためのサンプルノートブックを含む基盤モデルハブです。これらのモデルをデプロイすると、SageMaker SDK/API を使用して直接アクセスできるリアルタイムの推論エンドポイントが作成されます。または、AWS API Gateway と AWS Lambda 関数内の軽量コンピューティングロジックを使用して SageMaker の基盤モデルエンドポイントをフロントエンドすることもできます。これらのモデルの一部をテキスト埋め込みに活用することもできます。
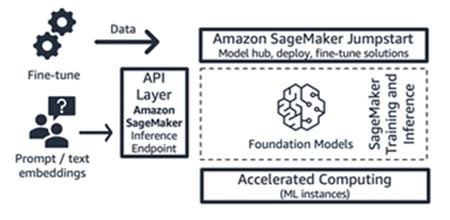
推論エンドポイントと微調整トレーニングジョブはどちらも、SageMaker を ML プラットフォーム (図 9 の「ML プラットフォーム」を参照) として、選択したマネージド ML インスタンス (図 9 の「高速コンピューティング」を参照) で実行されます。SageMaker Jumpstart は、インフラストラクチャをより細かく制御したいと考えており、中程度の ML スキルとインフラストラクチャに関する知識を持っているアプリケーションやモデルコンシューマー向けのスタートアップに最適です。その料金モデルは従量制で、通常はインスタンス時間単位で課金されます。このサービスのすべてのモデルとソリューションは一般提供されています。
Amazon SageMaker トレーニングと推論 (ML プラットフォーム)
スタートアップは、Amazon SageMaker のトレーニングおよび推論機能を活用して、分散型トレーニング、分散型推論、マルチモデルエンドポイントなどの高度な機能を実現できます。SageMaker JumpStart、Hugging Face、AWS Marketplace など、任意のモデルハブから基盤モデルを持ち込むことも、独自の基盤モデルをゼロから構築することもできます。
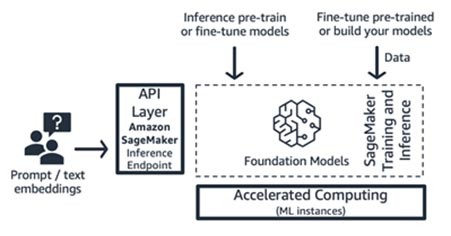
SageMaker は、フルスタックの生成系 AI アプリケーションビルダー (モデルプロバイダーからモデルコンシューマーまで) や、高度な ML およびデータ前処理スキルを持つチームを持つモデルプロバイダーに最適です。SageMaker は、従量制料金モデルも提供していて、通常はインスタンス時間単位で課金されます。
AWS Trainium と AWS Inferentia (高速コンピューティング)
2023 年 4 月、AWS は AWS Trainium を搭載した Amazon EC2 TRN1n インスタンスと、AWS Inferentia2 を搭載した Amazon EC2 Inf2 インスタンスの一般提供を発表しました。SageMaker を ML プラットフォームとして使用することで、AWS 専用アクセラレーター (AWS Trainium と AWS Inferentia) を活用できます。
推論ワークロードのベンチマークテストでは、Inf2 インスタンスは、推論に最適化された同等の Amazon EC2 インスタンスと比較してコストが 52% 低減することが報告されています。AWS Neuron SDK の迅速な開発サイクルにご期待ください。AWS はほぼ毎月、トレーニングと推論の両方のために新しいモデルアーキテクチャをサポートマトリックスに追加しています。
生成系 AI アプリケーションを構築するためのアプローチ
では、図 9 の各コンポーネントを実装の観点から説明しましょう。
ゼロショットまたは数ショットの学習推論アプローチ
前に説明したように、ゼロショットまたは数ショット学習は、生成系 AIアプリケーションを構築するための最も簡単なアプローチです。このアプローチに基づいてアプリケーションを構築するために必要なのは、4 つの共通コンポーネント (基盤モデル、インターフェイス、ML プラットフォーム、コンピューティング) のサービス、プロンプトを生成するカスタムコード、フロントエンドウェブ/モバイルアプリケーションだけです。
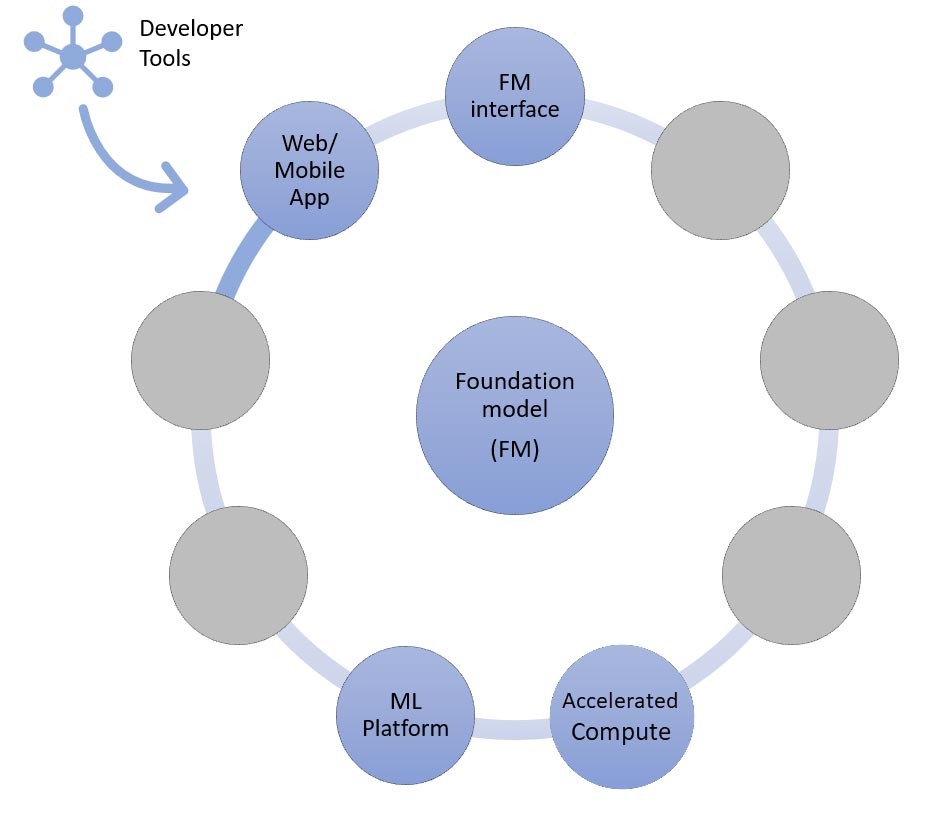
Amazon Bedrock または Amazon SageMaker JumpStart で基盤モデルをどのように選択するかの詳細については、こちらのモデル選択ガイドラインを参照してください。
カスタムコードでは、LangChain などのデベロッパーツールを活用してプロンプトのテンプレート作成や生成を行うことができます。LangChain コミュニティは既に Amazon Bedrock、Amazon API Gateway、および SageMaker エンドポイントのサポートを提供しています。なお、コーディングコンパニオンツールである AWS Amazon CodeWhisperer を活用して、デベロッパーの効率向上に役立てるのもいいかもしれません。
フロントエンドのウェブアプリやモバイルアプリケーションを構築しているスタートアップは、AWS Amplify を使用して簡単に開始して拡張できます。また、AWS Amplify ホスティングを使用してこれらのウェブアプリケーションを高速、安全、信頼性の高い方法でホストできます。
SageMaker Jumpstart を使って構築するゼロショット学習の例をご覧ください。
情報検索アプローチ
上述のように、スタートアップが基盤モデルをカスタマイズできる方法の 1 つは、最も一般的に検索拡張生成 (RAG) として知られる情報検索システムで拡張することです。このアプローチには、テキスト埋め込みエンドポイントとベクトルデータベースだけでなく、ゼロショット学習や数ショット学習で説明されているすべてのコンポーネントが含まれます。
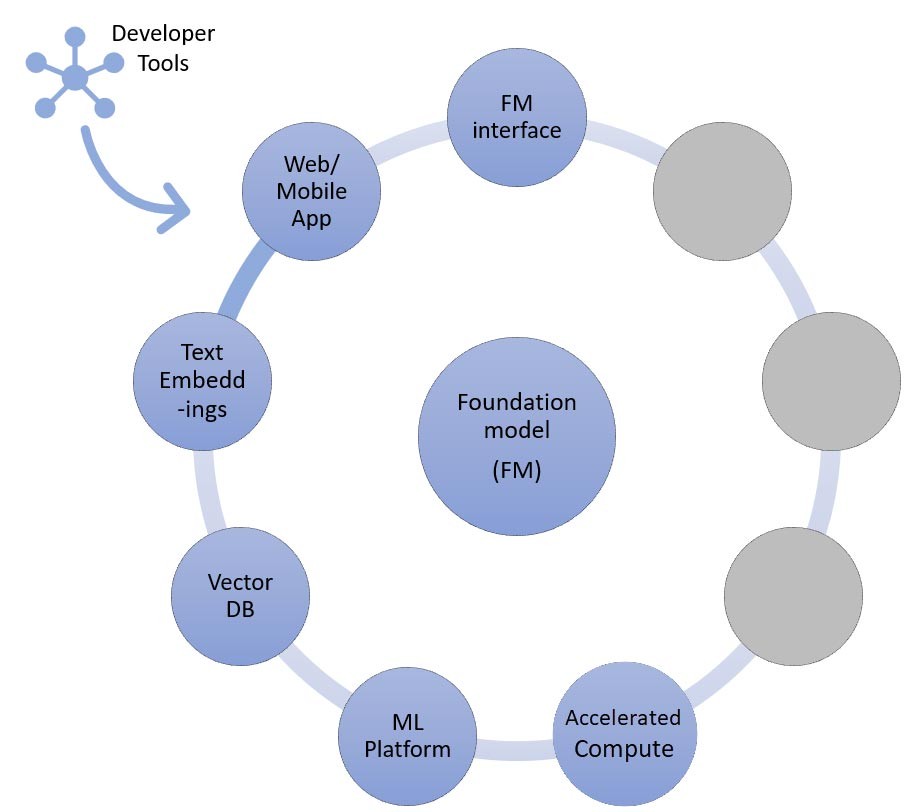
テキスト埋め込みエンドポイントのオプションは、選択した以下の AWS マネージドサービスによって異なります。
- Amazon Bedrock では、テキスト入力 (語句、場合によってはより大きなテキスト単位) を、テキストのセマンティックな意味を含む数値表現 (埋め込み表現と呼ばれる) に変換する埋め込み大規模言語モデル (LLM) が用意されています。
- SageMaker JumpStart を使用している場合は、GPT-J 6B などの埋め込みモデルや、モデルハブから選択したその他の LLM をホストできます。SageMaker エンドポイントは SageMaker SDK や Boto3 によって呼び出し、テキスト入力を埋め込みに変換できます。
その後、埋め込みをベクトルデータストアに保存し、Amazon RDS for PostgreSQL の pgvector 拡張または Amazon OpenSearch Service の k-NN プラグインを使用してセマンティック検索を行うことができます。スタートアップは、通常どのサービスを最も使い慣れているかによって、どちらか一方を選びます。スタートアップは AWS パートナーやオープンソースの AI ネイティブベクトルデータベースを使用する場合もあります。ベクトルデータストアの選択に関するガイダンスについては、「生成系 AI アプリケーションにおけるベクトルデータストアの役割」を参照することをおすすめします。
このアプローチでも、デベロッパーツールは極めて重要な役割を果たし、簡単なプラグアンドプレイフレームワーク、プロンプト型のテンプレート、幅広い統合サポートを提供します。
今後は、Amazon Bedrock のエージェントを活用することもできます。これは、企業システムへの API 呼び出しを管理できるデベロッパー向けの新機能です。
Amazon SageMaker Jumpstart の基盤モデルで検索拡張生成を使用するこちらの例をご覧ください。
微調整またはさらなる事前トレーニングアプローチ
それでは、生成系 AI アプリケーションを実装する最後のアプローチ (基盤モデルの微調整または事前トレーニング) に必要な AWS サービスにコンポーネントをマッピングしてみましょう。このアプローチには、データの前処理やモデルトレーニングだけでなく、ゼロショット学習または数ショット学習で説明したすべてのコンポーネントが含まれます。
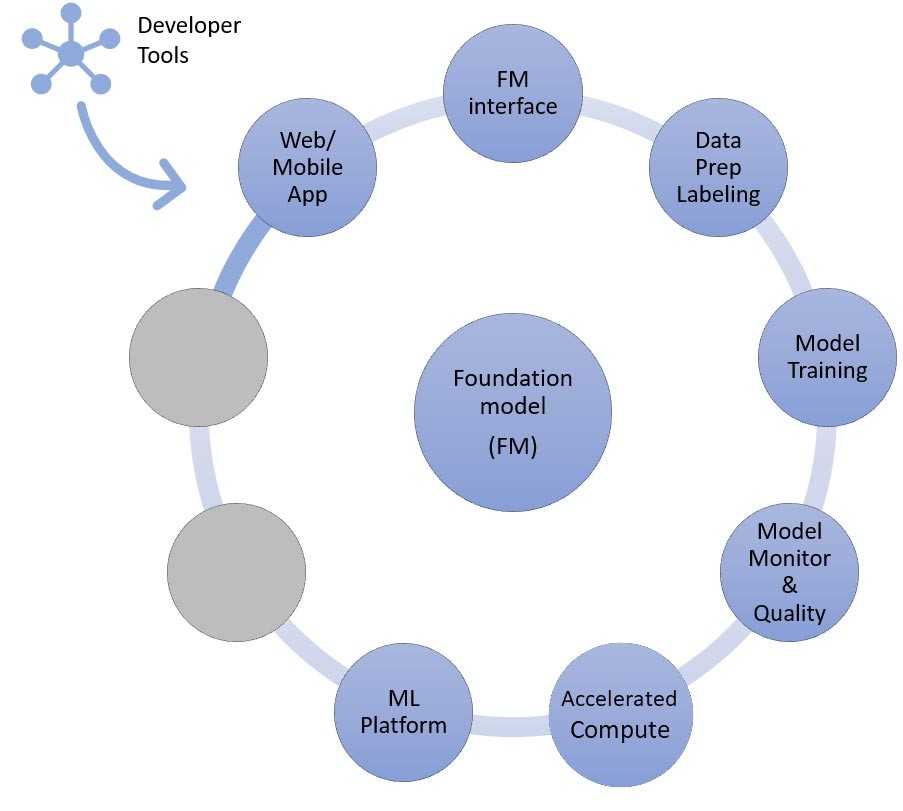
データの準備 (前処理またはアノテーションとも呼ばれる) は、小規模でラベル付けされたデータセットが必要な微調整を行う際には特に重要です。スタートアップは Amazon SageMaker Data Wrangler を簡単に使用し始めることができます。このサービスにより、機械学習用の表形式データと画像データを集約して準備するのにかかる時間を数週間から数分に短縮できます。また、このサービスの推論パイプライン機能を活用して、前処理ワークフローをトレーニングや微調整ジョブに連動させることもできます。
スタートアップが Amazon S3 のデータレイクにある大量の非構造化データセットやラベル付けされていないデータセットを前処理する必要がある場合、次に示すいくつかの選択肢があります。
- Python や一般的な Python ライブラリを使用している場合は、 AWS Glue for Ray を活用すると便利です。AWS Glue は、Python ワークロードのスケーリングに使用されるオープンソースの統合コンピューティングフレームワークである Ray を使用しています。
- あるいは、Amazon EMR は、Apache Spark、Apache Hive、Apache HBase、Apache Flink、Apache Hudi、Presto などのオープンソースツールを使用して膨大な量のデータを処理するのに役立ちます。
このアプローチのモデルトレーニングコンポーネントとして、Amazon Bedrock では、独自のデータを使用して FM を非公開でカスタマイズできます。インフラストラクチャを一切管理しなくても FM を大規模に管理できます (これは API による微調整方法です)。あるいは、SageMaker Jumpstart アプローチでは、独自のデータを使用して (一部のモデルで) 指示やドメインアダプテーションを非公開で微調整できるクイックスタートソリューションを利用できます。SageMaker JumpStart に付属するトレーニングスクリプトを必要に応じて変更することも、オープンソースモデル用の独自のトレーニングスクリプトを持ち込んで SageMaker のトレーニングジョブとして利用することもできます。モデルをさらに事前トレーニングする必要がある場合 (通常はオープンソースモデル用)、SageMaker の分散型トレーニングライブラリを活用して ML インスタンスのすべての GPU を高速化し、効率的に活用できます。
さらに、Amazon SageMaker Ground Truth Plus を使って、人間のフィードバックによる強化学習技術によるフルマネージド型のデータ生成、データアノテーションサービス、およびモデル開発を検討することもできます。
アーキテクチャの例
では、生成系 AI のユースケースを実現するとき、これらすべてのコンポーネントはどのように見えるのでしょうか。スタートアップはそれぞれユースケースが異なり、現実世界の問題を解決するための独自のアプローチもありますが、生成系 AI アプリケーションの構築において私が見てきた共通のテーマや出発点の 1 つは、検索拡張生成アプローチです。上記で説明した AWS のサービスをすべてつなげると、アーキテクチャは次のようになります。
取り込みパイプライン – ドメイン固有データまたは独自データは、テキストデータとして前処理されます。埋め込みプロセスを通じて作成または更新されると、バッチ処理 (Amazon S3 に保存) されるか、ストリーミング (Amazon Kinesis を使用) され、高密度のベクトル表現で保存されます。

検索パイプライン – ユーザーがベクトル表現で保存された独自のデータをクエリすると、k 最近傍検索 (kNN) またはセマンティック検索を使用して関連ドキュメントを取得します。関連ドキュメントはその後、デコードしてクリアテキストに戻されます。出力は、プロンプトの豊富で密度の高いコンテキストとして機能します。

要約生成パイプライン – 元のユーザークエリとともにコンテキストがプロンプトに追加され、取得した文書からインサイトや要約を取得します。

これらのレイヤーはすべて、LangChain などの開発ツールを使用することにより、数行のコードで構築できます。
まとめ
これは、AWS のサービスを利用してエンドツーエンドの生成系 AI アプリケーションを構築する方法の 1 つです。どの AWS サービスを選択するかは、ユースケースや採用するカスタマイズアプローチによって異なります。このリンクをブックマークして、生成系 AI に関する最新の AWS リリース、ソリューション、ブログをチェックしましょう。
AWS で生成系 AI アプリケーションを構築しましょう。AWS Activate で生成系 AI ジャーニーを始めましょう。これは、スタートアップや初期段階の起業家向けに特別に設計された無料のプログラムで、AWS を使い始めるのに必要なリソースが用意されています。

Hrushikesh Gangur
Hrushikesh Gangur は、AWS 機械学習とネットワーキングサービスの両方の専門知識を備えた、AI/ML スタートアップのための Principal Solutions Architect です。生成系 AI、自律走行車、ML プラットフォームを構築するスタートアップが AWS 上で効率的かつ効果的にビジネスを運営できるようサポートしています。
このコンテンツはいかがでしたか?