이 콘텐츠는 어떠셨나요?
Startup을 위한 생성형 AI 애플리케이션 구축
최근 생성형 AI 발전 으로 Startup이 빠르게 구축, 확장 및 혁신하는 데 도움이 되는 도구에 대한 기대치가 높아지고 있습니다. 특히 트랜스포머 신경망 아키텍처를 중심으로 기계 학습(ML)이 널리 도입되고 대중화되면서 기술의 중요한 변곡점이 되고 있습니다. Startup이 올바른 도구 만 갖춘다면 새로운 아이디어를 구상하거나 기존 제품을 혁신하여 고객에게 생성형 AI의 이점을 제공할 수 있습니다.
Startup을 위한 생성형 AI 애플리케이션을 구축할 준비가 되셨나요? 먼저 생성형 AI 애플리케이션을 구축하기 위한 개념, 핵심 아이디어, 일반적인 접근 방식을 살펴보도록 하겠습니다.
생성형 AI 애플리케이션이란 무엇인가요?
생성형 AI 애플리케이션은 대화, 스토리, 이미지, 비디오, 코드, 음악 등 새로운 콘텐츠와 아이디어를 만들어낼 수 있는 AI 유형을 기반으로 하는 프로그램입니다. 여타의 AI 애플리케이션과 마찬가지로 생성형 AI 애플리케이션은 방대한 양의 데이터를 기반으로 사전 훈련된 ML 모델을 기반으로 구동되며, 흔히 파운데이션 모델(FM)이라고 합니다.
생성형 AI 애플리케이션의 예로는 통합 개발 환경(IDE)에서 전체 코드 줄 및 전체 기능 코드 제안을 제공하여 개발자가 애플리케이션을 더 빠르고 안전하게 구축할 수 있도록 지원하는 AI 코딩 도우미인 Amazon CodeWhisperer가 있습니다. CodeWhisperer는 수십억 줄의 코드로 훈련되었으며, 주석 및 기존 코드를 기반으로 코드 조각부터 전체 기능에 이르기까지 다양한 코드 제안을 즉시 생성할 수 있습니다. Startup은 CodeWhisperer 프로페셔널 티어에 AWS Activate 크레딧을 사용하거나, 무료로 사용할 수 있는 개별 티어로 시작할 수 있습니다.
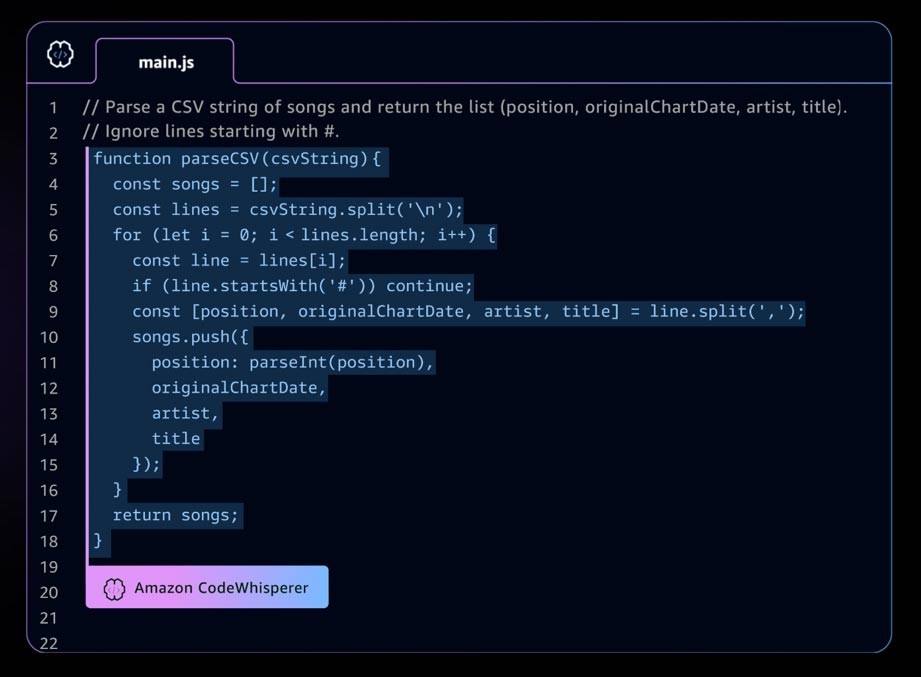
빠르게 발전하는 생성형 AI 환경
생성형 AI Startup과 생성형 AI 도입을 간소화하는 도구를 개발하는 Startup에서도 빠른 성장이 나타나고 있습니다. 언어 모델로 구동되는 애플리케이션을 개발하기 위한 오픈 소스 프레임워크인 LangChain과 같은 도구를 사용하면 더 다양한 조직들이 생성형 AI에 보다 쉽게 접근할 수 있으며 이를 통해 도입이 가속화될 것입니다. 이러한 도구로는 프롬프트 엔지니어링, 보강 서비스(예: 임베딩 도구 또는 벡터 데이터베이스), 모델 모니터링, 모델 품질 측정, 가드레일, 데이터 주석, 인적 피드백을 통한 강화 학습(RLHF) 등이 있습니다.
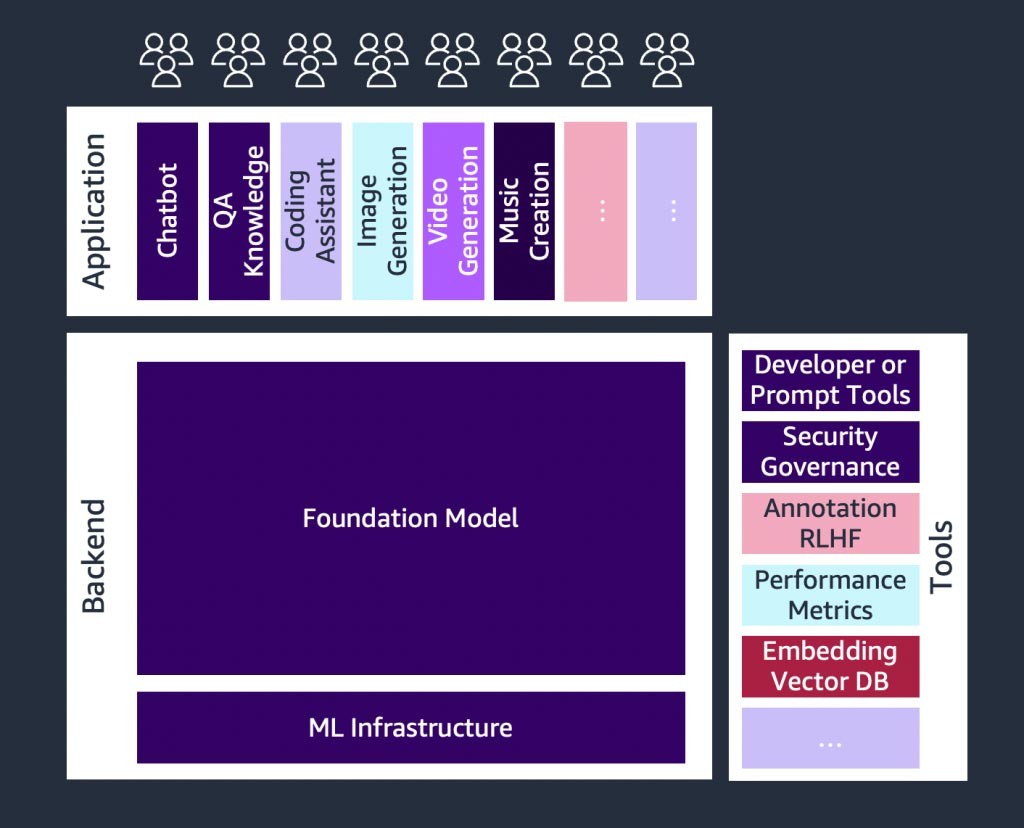
파운데이션 모델 소개
생성형 AI 애플리케이션 또는 도구의 핵심은 파운데이션 모델입니다. 파운데이션 모델은 다양한 다운스트림 작업을 수행하기 위해 방대한 양의 데이터를 기반으로 사전 훈련할 수 있다는 점에서 차별화되는 강력한 기계 학습 모델의 일종입니다. 이러한 작업으로는 텍스트 생성, 요약, 정보 추출, Q&A, 챗봇 등이 있습니다. 반면, 기존 ML 모델은 데이터 세트에서 특정 작업을 수행하도록 훈련됩니다.
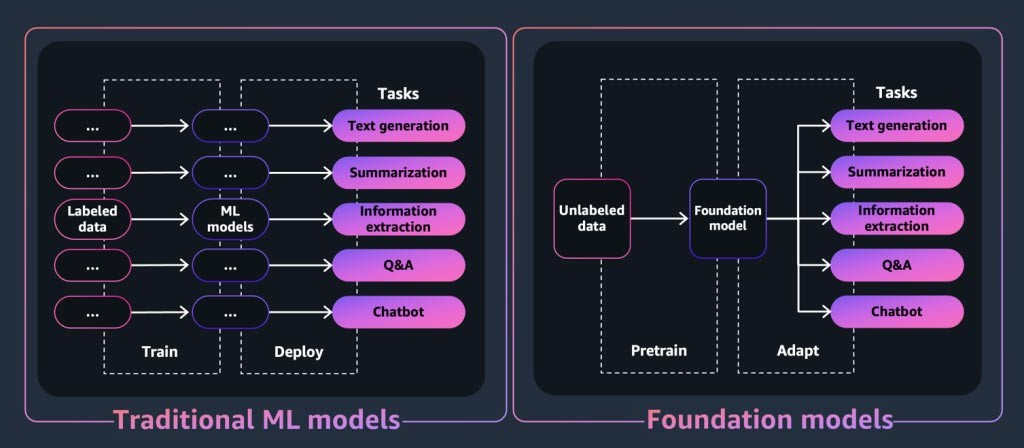
그렇다면 파운데이션 모델은 생성형 AI 애플리케이션의 그 놀라운 출력을 어떻게 ‘생성’할까요? 이러한 기능은 FM이 시퀀스의 다음 항목을 예측하거나 새 항목을 생성할 수 있도록 하는 학습 패턴 및 관계에서 비롯됩니다.
- 텍스트 생성 모델에서 FM은 다음 단어, 다음 문구 또는 질문에 대한 대답을 출력합니다.
- 이미지 생성 모델의 경우 FM은 텍스트를 기반으로 이미지를 출력합니다.
- 이미지가 입력인 경우 FM은 다음으로 연관성이 높거나 업스케일링된 이미지, 애니메이션 또는 3D 이미지를 출력합니다.
각각의 경우 모델은 ‘프롬프트’에서 파생된 시드 벡터로 시작합니다. 프롬프트는 모델이 수행해야 하는 작업을 설명합니다. 프롬프트의 품질 및 세부 정보(‘컨텍스트’라고도 함)에 따라 출력의 품질과 연관성이 결정됩니다.
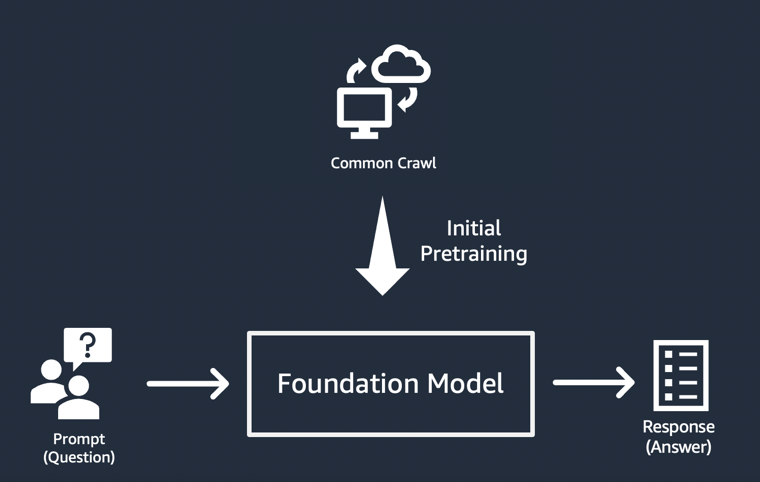
가장 단순한 생성형 AI 애플리케이션 구현 형태
생성형 AI 애플리케이션을 구축하는 가장 간단한 방법은 지시 조정 파운데이션 모델을 사용하고 제로샷 학습 또는 퓨샷 러닝 기법을 사용하여 의미 있는 프롬프트(‘프롬프트 엔지니어링’)를 제공하는 것입니다. 지시 조정 모델(예: FLAN T5 XXL, Open-Llama 또는 Falcon 40B Instruct)은 관련 작업 또는 개념에 대한 이해를 바탕으로 프롬프트에 대한 예측을 생성합니다. 다음은 몇 가지 프롬프트 예입니다.
제로샷 학습
제목:\’대학교에 새 시설 개설 예정‘\\n위의 가상의 기사 제목에서 기사 내용을 떠올려 보세요.\n
퓨샷 러닝
잘 됐다! // 긍정적
이건 너무하잖아! // 부정적
그 영화는 정말 졸작이야! // 부정적
정말 끔찍한 쇼야! //
대답: 부정적
특히 Startup은 지시 조정 모델을 사용함으로써 빠른 배포, 최소한의 데이터 요구 사항, 비용 최적화라는 이점을 누릴 수 있습니다.
파운데이션 모델 선택 시 고려할 사항에 대해 자세히 알아보려면 Selecting the right foundation model for your startup(Startup에 적합한 파운데이션 모델 선택)을 참조하세요.
파운데이션 모델 맞춤화
지시 조정 모델에 프롬프트 엔지니어링을 사용한다고 해서 모든 사용 사례를 충족할 수 있는 것은 아닙니다. Startup을 위한 파운데이션 모델을 맞춤화하는 이유는 다음과 같습니다.
- 특정 작업(예: 코드 생성)을 파운데이션 모델에 추가
- 회사의 독점 데이터 세트를 기반으로 대답 생성
- 모델을 사전 훈련하는 데 사용한 데이터 세트보다 더 높은 품질의 데이터 세트를 기반으로 대답 생성
- 실제로 정확하지 않거나 합리적이지 않은 출력인 ‘할루시네이션’ 줄이기
파운데이션 모델을 맞춤화하는 세 가지 일반적인 기법이 있습니다.
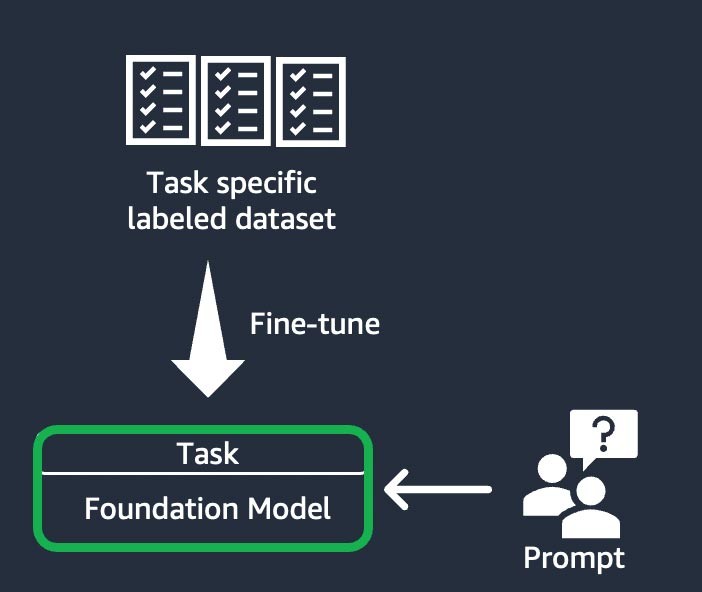
지시 기반 미세 조정
이 기법에서는 작업별 레이블이 지정된 데이터 세트를 기반으로 특정 작업을 완료하도록 파운데이션 모델을 훈련합니다. 레이블이 지정된 데이터 세트는 프롬프트와 대답의 쌍으로 구성됩니다. 이 맞춤화 기법은 최소한의 데이터 세트로 FM을 빠르게 맞춤화하려는 Startup에 유용합니다. 훈련하는 데 필요한 데이터 세트와 단계가 더 적기 때문입니다. 모델 가중치는 미세 조정 중인 작업 또는 계층에 따라 업데이트됩니다.
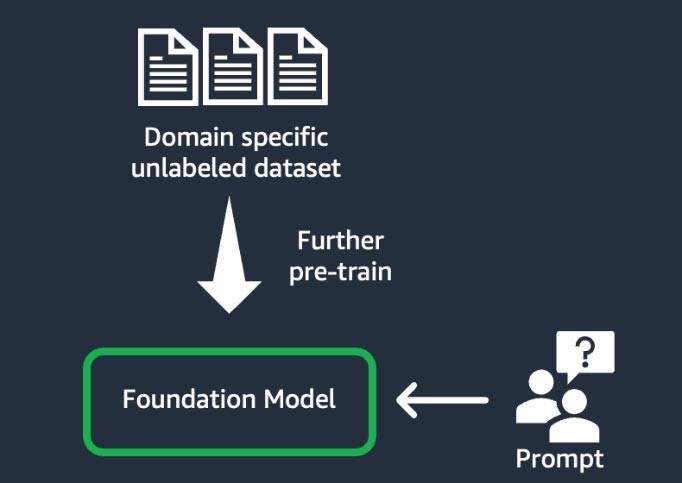
영역 적응(‘추가 사전 훈련’이라고도 함)
이 기법에서는 레이블이 지정되지 않은 영역별 데이터의 대규모 ‘코퍼스’(훈련 자료 모음)를 사용하여 파운데이션 모델을 훈련합니다(‘자체 지도 학습’이라고 함). 이 기법은 기존 파운데이션 모델에서는 볼 수 없었던 영역별 전문 용어와 통계 데이터를 포함하는 사용 사례에 유용합니다. 예를 들어 금융 분야의 독점 데이터를 처리하는 생성형 AI 애플리케이션을 구축하는 Startup은 FM을 통해 사용자 지정 어휘에 대한 추가 사전 훈련, 그리고 텍스트를 토큰이라고 하는 더 작은 단위로 나누는 프로세스인 ‘토큰화’를 통해 이점을 얻을 수 있습니다.
일부 Startup은 품질을 높이기 위해 이 프로세스에서 인적 피드백을 통한 강화 학습(RLHF) 기법을 구현합니다. 또한 특정 작업을 미세 조정하려면 명령 기반 미세 조정이 필요합니다. 이 기법은 다른 기법에 비해 비용과 시간이 많이 소요됩니다. 모델 가중치는 모든 계층에서 업데이트됩니다.
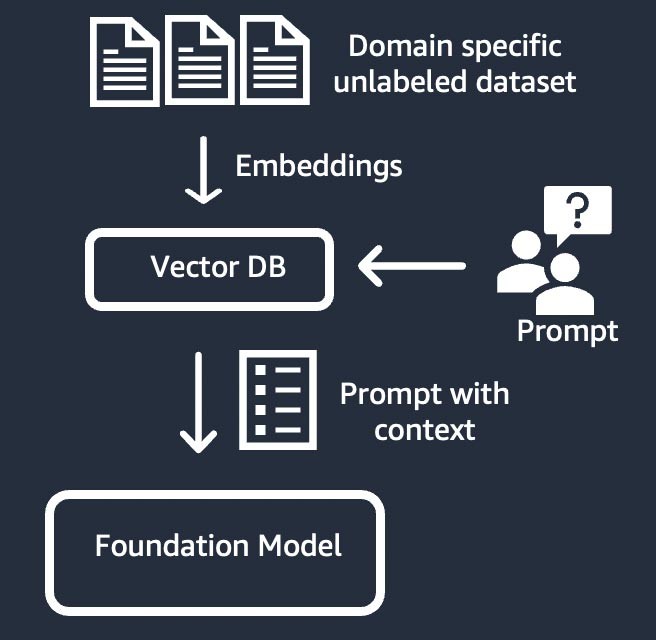
정보 검색(‘검색 증강 생성’ 또는 ‘RAG’라고도 함)
이 기법에서는 고밀도 벡터 표현을 기반으로 하는 정보 검색 시스템으로 파운데이션 모델을 보강합니다. 비공개 영역 지식 또는 독점 데이터는 텍스트 임베딩 프로세스를 거쳐 코퍼스의 벡터 표현을 생성하고 벡터 데이터베이스에 저장됩니다. 사용자 쿼리를 기반으로 하는 시맨틱 검색 결과가 프롬프트의 컨텍스트가 됩니다. 파운데이션 모델은 컨텍스트가 있는 프롬프트를 기반으로 대답을 생성하는 데 사용됩니다. 이 기법에서는 파운데이션 모델의 가중치가 업데이트되지 않습니다.
생성형 AI 애플리케이션의 구성 요소
위의 섹션에서는 Startup이 생성형 AI 애플리케이션을 구축할 때 파운데이션 모델을 사용하여 취할 수 있는 다양한 접근 방식을 배웠습니다. 이제 이러한 파운데이션 모델이 어떻게 생성형 AI 애플리케이션을 구축하는 데 필요한 일반적인 구성 요소로 사용되는지 살펴보겠습니다.
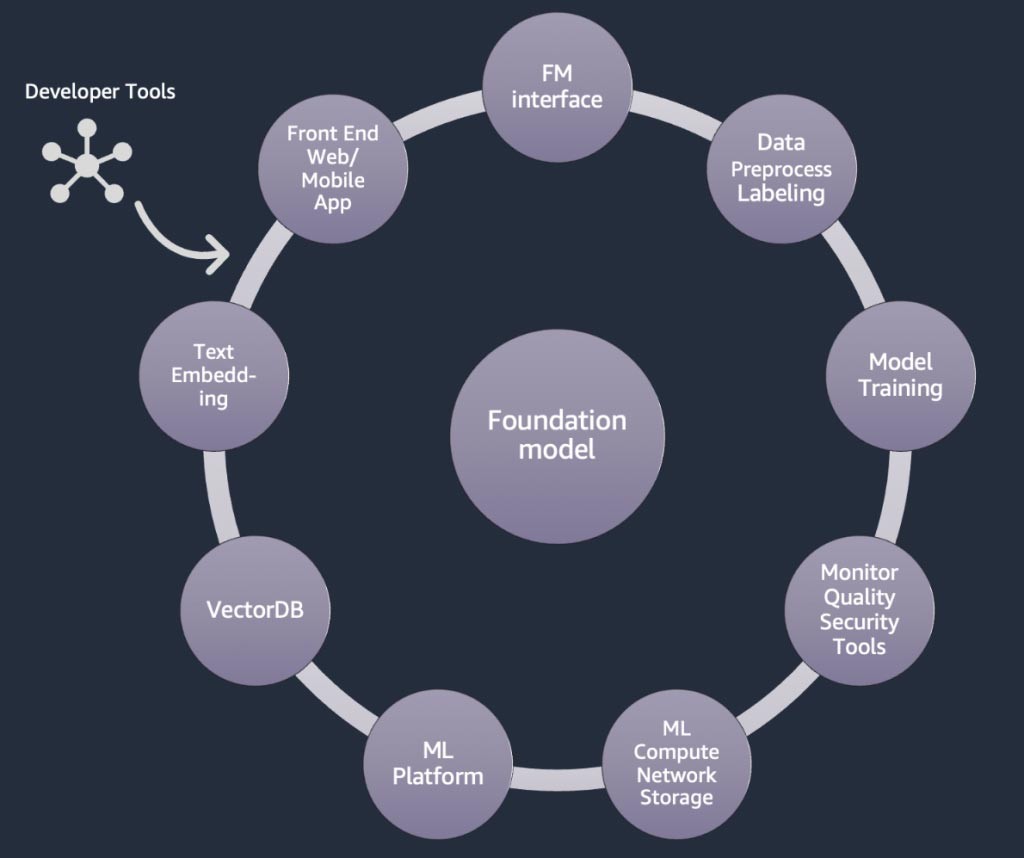
핵심은 파운데이션 모델(가운데)입니다. 이 블로그의 앞부분에서 설명한 가장 간단한 접근 방식에는 API(위쪽)를 통해 파운데이션 모델에 액세스하는 웹 애플리케이션 또는 모바일 앱(왼쪽 위)이 필요합니다. 이 API는 모델 제공업체를 통해 제공되는 관리형 서비스이거나 오픈 소스 또는 독점 모델을 사용하여 자체적으로 호스팅되는 서비스입니다. 자체적으로 호스팅하는 경우 모델을 호스팅하기 위해 가속 컴퓨팅 인스턴스를 기반으로 하는 기계 학습 플랫폼이 필요할 수 있습니다.
RAG 기법에서는 텍스트 임베딩 엔드포인트와 벡터 데이터베이스(왼쪽 및 왼쪽 아래)를 추가해야 합니다. 둘 다 API 서비스로 제공되거나 자체적으로 호스팅됩니다. 텍스트 임베딩 엔드포인트는 파운데이션 모델에 의해 지원되며, 파운데이션 모델은 임베딩 로직 및 토큰화 지원에 따라 선택됩니다. 이러한 모든 구성 요소는 생성형 AI 애플리케이션 개발을 위한 프레임워크를 제공하는 개발자 도구를 사용하여 서로 연결됩니다.
마지막으로, 파운데이션 모델의 미세 조정 또는 추가 사전 훈련(오른쪽)과 같은 맞춤화 기법을 선택할 때는 데이터 전처리 및 주석 달기에 도움이 되는 구성 요소(오른쪽 위)와 특정 가속 컴퓨팅 인스턴스에서 훈련 작업을 실행하기 위한 ML 플랫폼(아래)이 필요합니다. 일부 모델 제공업체는 API 기반 미세 조정을 지원하므로 이러한 경우 ML 플랫폼과 기반 하드웨어에 대해 걱정할 필요가 없습니다.
맞춤화 방식에 관계없이, 모니터링, 품질 지표 및 보안 도구(오른쪽 아래)를 제공하는 구성 요소를 통합할 수도 있습니다.
생성형 AI 애플리케이션을 구축하려면 어떤 AWS 서비스를 사용해야 하나요?
다음 다이어그램(그림 9)은 각 구성 요소와 해당하는 AWS 서비스를 보여줍니다. 참고로 이들 서비스는 엄선된 AWS 서비스 세트로, 여러 Startup에 이점을 제공하고 있습니다. 단, 다른 AWS 서비스도 많습니다.
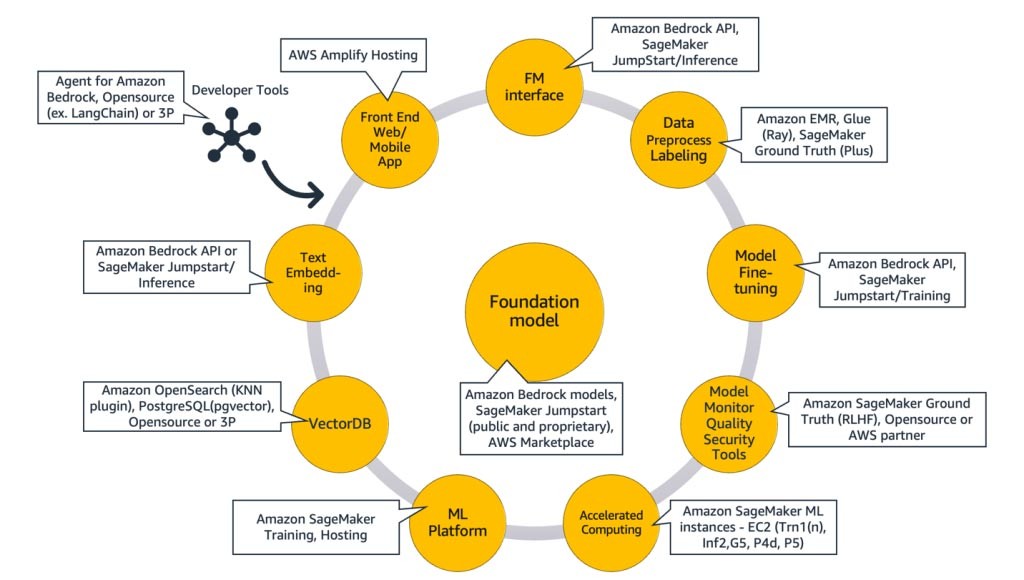
보다 자세한 설명을 위해 먼저 생성형 AI 애플리케이션의 공통적인 구성 요소에 해당하는 AWS 서비스를 살펴보겠습니다. 그런 다음 애플리케이션을 구현하는 데 사용하는 접근 방식에 따라 그림 9의 나머지 구성 요소에 해당하는 AWS 서비스에 대해 설명하겠습니다.
공통 구성 요소
생성형 AI 애플리케이션의 공통 구성 요소는 파운데이션 모델(FM), 인터페이스, 그리고 선택 사항인 기계 학습(ML) 플랫폼 및 가속 컴퓨팅 등입니다. AWS에서 제공하는 관리형 오퍼링을 사용하면 이러한 요건을 충족할 수 있습니다.
Amazon Bedrock(파운데이션 모델 및 인터페이스 구성 요소)
Amazon Bedrock은 API를 통해 주요 AI Startup(AI21의 Jurassic, Anthropic의 Claude, Cohere의 Command and Embedding, Stability의 SDXL 모델) 및 Amazon(Titan Text 및 Embeddings 모델)의 파운데이션 모델을 사용할 수 있는 완전관리형 서비스입니다. 따라서 다양한 FM 중에서 사용 사례에 가장 적합한 모델을 선택할 수 있습니다. Amazon Bedrock은 파운데이션 모델 세트에 대한 API 또는 서버리스 액세스를 제공하여 텍스트 임베딩, 프롬프트/대답, 미세 조정(일부 모델)의 세 가지 기능을 제공합니다.
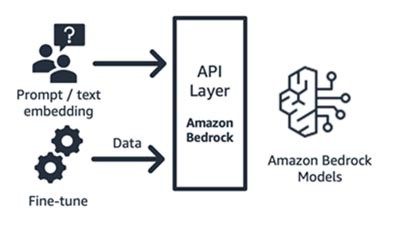
Amazon Bedrock은 선택한 파운데이션 모델을 중심으로 프롬프트 엔지니어링, 검색 증강 생성 등의 부가가치 서비스를 구축하려는 애플리케이션 또는 모델 소비자 Startup에 적합합니다. 사용량에 따른 요금 모델이 적용되며, 일반적으로 처리되는 백만 단위의 토큰을 기준으로 요금이 책정됩니다. Amazon Bedrock은 정식 출시되었지만 이 블로그에서 설명하는 일부 기능은 비공개 평가판으로 제공됩니다. 여기에서 자세히 알아보세요.
Amazon SageMaker JumpStart(파운데이션 모델 및 인터페이스 구성 요소)
AWS는 공개 모델 및 독점 모델, 퀵 스타트 솔루션, 모델 배포 및 미세 조정을 위한 예시 노트북이 모두 포함된 파운데이션 모델 허브인 Amazon SageMaker Jumpstart에 생성형 AI 기능을 제공합니다. 이러한 모델을 배포하면 SageMaker SDK/API를 사용하여 직접 액세스할 수 있는 실시간 추론 엔드포인트가 생성됩니다. 또는 AWS API Gateway 와 AWS Lambda 함수의 경량 컴퓨팅 로직을 사용하여 SageMaker의 파운데이션 모델 엔드포인트를 프런트엔드로 사용할 수 있습니다. 이러한 모델 중 일부를 텍스트 임베딩에 활용할 수도 있습니다.
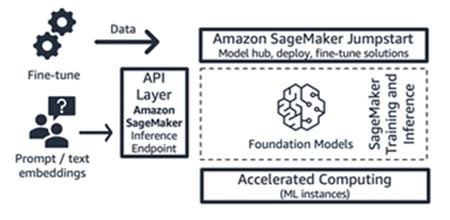
추론 엔드포인트와 미세 조정 훈련 작업은 모두 SageMaker를 ML 플랫폼(그림 9의 ‘ML 플랫폼’ 참조)으로 사용하여 고객의 관리형 ML 인스턴스(그림 9의 ‘가속 컴퓨팅’ 참조)에서 실행됩니다. SageMaker Jumpstart는 인프라를 보다 효과적으로 제어하기를 원하며, ML 기술 역량과 인프라 지식을 어느 정도 갖춘 애플리케이션 또는 모델 소비자 Startup에 적합합니다. 요금 모델은 일반적으로 인스턴스 시간 단위로 사용한 만큼만 지불하는 방식입니다. 이 오퍼링의 모든 모델 및 솔루션은 정식 출시되었습니다.
Amazon SageMaker 훈련 및 추론(ML 플랫폼)
Startup은 분산 훈련, 분산 추론, 다중 모델 엔드포인트 등의 고급 기능에 Amazon SageMaker의 훈련 및 추론 기능을 활용할 수 있습니다. SageMaker JumpStart, Hugging Face , AWS Marketplace 등 원하는 모델 허브에서 파운데이션 모델을 가져오거나 자체 파운데이션 모델을 새로 구축할 수 있습니다.
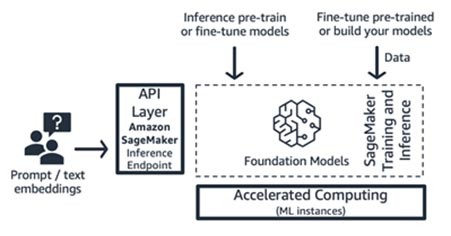
SageMaker는 모델 제공업체부터 모델 소비자에 이르기까지 풀 스택 생성형 AI 애플리케이션 빌더, 또는 고급 ML 및 데이터 전처리 기술을 갖춘 팀을 보유한 모델 제공업체에 적합합니다. 또한 SageMaker는 일반적으로 인스턴스 시간 단위로 사용한 만큼 요금을 지불하는 요금 모델을 제공합니다.
AWS Trainium 및 AWS Inferentia(가속 컴퓨팅)
2023년 4월, AWS는 AWS Trainium 기반 Amazon EC2 Trn1n 인스턴스 와 AWS Inferentia2 기반 Amazon EC2 Inf2 인스턴스 의 정식 출시를 발표했습니다 . SageMaker를 ML 플랫폼으로 사용하면 AWS 전용 액셀러레이터(AWS Trainium 및 AWS Inferentia)를 활용할 수 있습니다.
추론 워크로드에 대한 벤치마크 테스트 결과에 따르면 Inf2 인스턴스는 동급의 추론 최적화 Amazon EC2 인스턴스에 비해 비용이 52% 더 저렴한 것으로 나타났습니다. AWS가 지원 매트릭스 에 훈련 및 추론을 위한 새 모델 아키텍처를 추가하는 AWS Neuron SDK의 빠른 개발 주기를 계속 주시할 필요가 있습니다.
생성형 AI 애플리케이션 구축을 위한 접근 방식
이제 구현의 관점에서 그림 9의 각 구성 요소를 살펴보겠습니다.
제로샷 또는 퓨샷 러닝 추론 방식
앞서 설명했듯이 제로샷 또는 퓨샷 러닝은 생성형 AI 애플리케이션을 구축하는 가장 간단한 접근 방식입니다. 이 방식을 기반으로 애플리케이션을 구축하려면 네 가지 공통 구성 요소(파운데이션 모델, 인터페이스, ML 플랫폼, 컴퓨팅)를 지원하는 서비스, 프롬프트를 생성하는 맞춤형 코드, 프런트엔드 웹/모바일 앱만 있으면 됩니다.
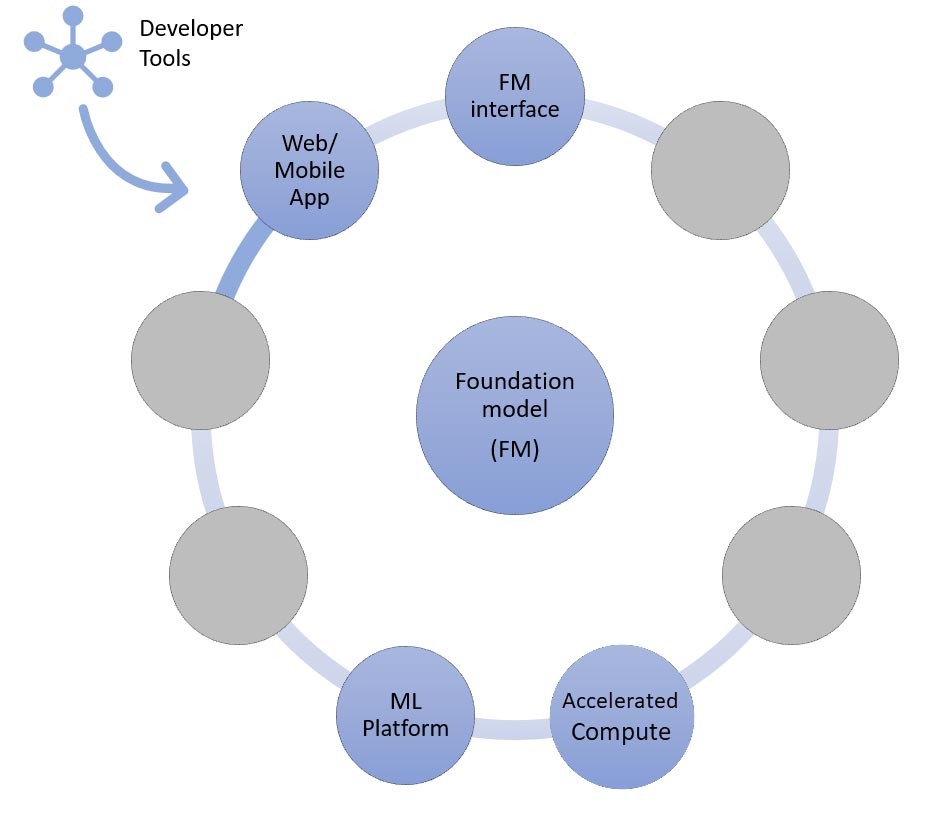
Amazon Bedrock 또는 Amazon SageMaker JumpStart를 통해 파운데이션 모델을 선택하는 방법에 대해 자세히 알아보려면 여기에서 모델 선택 지침을 참조하세요.
맞춤형 코드에서는 프롬프트 템플릿과 생성에 LangChain 과 같은 개발자 도구를 활용할 수 있습니다. LangChain 커뮤니티는 이미 Amazon Bedrock, Amazon API Gateway, SageMaker 엔드포인트에 대한 지원 을 추가했습니다. 다시 말씀드리지만, 코딩 보조 도구인 AWS Amazon CodeWhisperer를 활용하여 개발자의 효율성을 개선하는 것도 좋은 방법이 될 수 있습니다.
프런트엔드 웹 앱 또는 모바일 앱을 구축하는 Startup은 AWS Amplify를 사용하여 손쉽게 시작하고 확장할 수 있으며, AWS Amplify Hosting을 사용하여 빠르고 안전하며 안정적인 방식으로 이러한 웹 앱을 호스팅할 수 있습니다.
SageMaker Jumpstart로 빌드되는 제로샷 학습의 예 를 살펴보세요.
정보 검색 접근 방식
앞서 언급한 바와 같이, Startup이 파운데이션 모델을 맞춤화하는 방법 중 하나는 정보 검색 시스템을 통해 보강하는 것입니다. 이 시스템은 흔히 검색 증강 생성(RAG)이라고 불립니다. 이 접근 방식에는 제로샷 및 퓨샷 러닝에서 언급한 모든 구성 요소에 더해, 텍스트 임베딩 엔드포인트 및 벡터 데이터베이스가 포함됩니다.
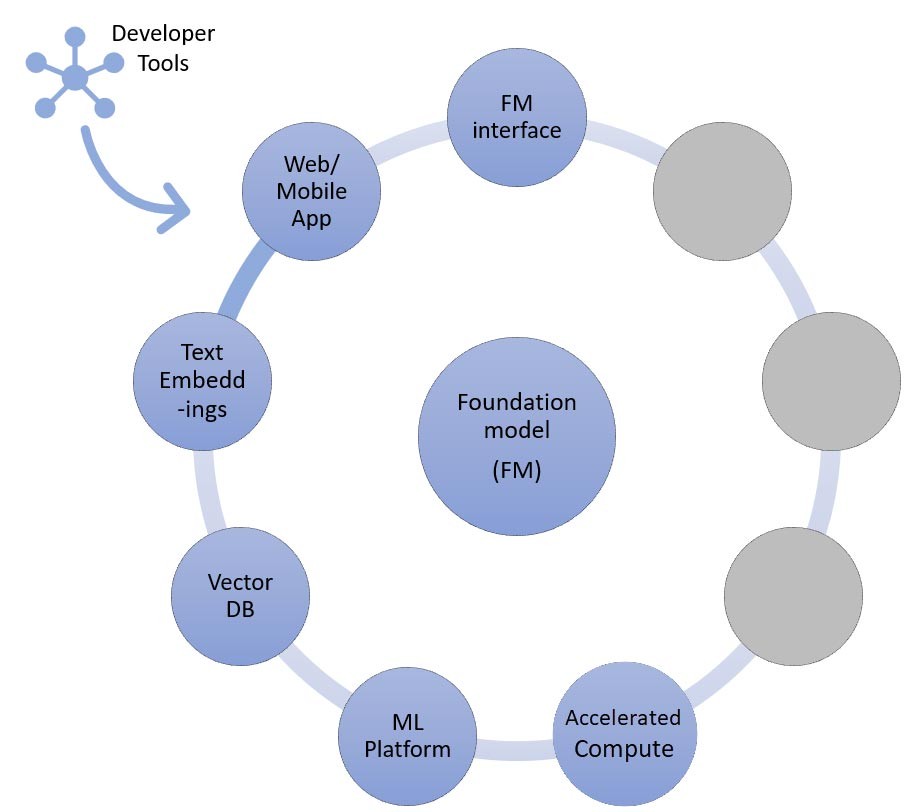
텍스트 임베딩 엔드포인트의 옵션은 선택한 AWS 관리형 서비스에 따라 다릅니다.
- Amazon Bedrock은 텍스트 입력(단어, 구 또는 큰 텍스트 단위)을 텍스트의 의미론적 의미를 포함하는 숫자 표현(임베딩이라고 함)으로 변환하는 임베딩 대규모 언어 모델(LLM)을 제공합니다.
- SageMaker JumpStart를 사용하는 경우 GPT-J 6B와 같은 임베딩 모델이나 모델 허브에서 선택한 다른 LLM을 호스팅할 수 있습니다. SageMaker SDK 또는 Boto3에서 SageMaker 엔드포인트를 간접적으로 호출하여 텍스트 입력을 임베딩으로 변환할 수 있습니다.
그런 다음 임베딩을 벡터 데이터 스토어에 저장하여 Amazon RDS for PostgreSQL 의 pgvector 확장 기능 또는 Amazon OpenSearch Service 의 k-NN 플러그인을 통해 시맨틱 검색을 수행할 수 있습니다. Startup은 일반적으로 가장 사용하기 편한 서비스가 무엇인지에 따라 이 두 가지 서비스 중 하나를 많이 사용합니다. AWS 파트너나 오픈 소스의 AI 네이티브 벡터 데이터베이스를 사용하는 Startup도 있습니다. 벡터 데이터 스토어 선택에 대한 지침은 The role of vector datastores in generative AI applications(생성형 AI 애플리케이션에서 벡터 데이터 스토어의 역할)를 참조하시기 바랍니다.
이 접근 방식에서도 개발자 도구는 중추적인 역할을 하며, 간편한 플러그 앤 플레이 프레임워크, 프롬프트 템플릿, 광범위한 통합 지원을 제공합니다.
앞으로는 회사 시스템에 대한 API 호출을 관리할 수 있는, 개발자를 위한 새로운 기능인 Amazon Bedrock용 에이전트를 활용할 수도 있습니다.
Amazon SageMaker JumpStart에서 파운데이션 모델과 함께 검색 증강 생성을 사용하는 이 예 를 참조하세요.
미세 조정 또는 추가 사전 훈련 접근 방식
이제 생성형 AI 애플리케이션을 구현하는 마지막 접근 방식인 파운데이션 모델의 미세 조정 또는 추가 사전 훈련에 필요한 구성 요소에 해당하는 AWS 서비스를 살펴보겠습니다. 이 접근 방식에는 제로샷 또는 퓨샷 러닝에서 설명하는 모든 구성 요소에 더해 데이터 전처리 및 모델 훈련이 포함됩니다.
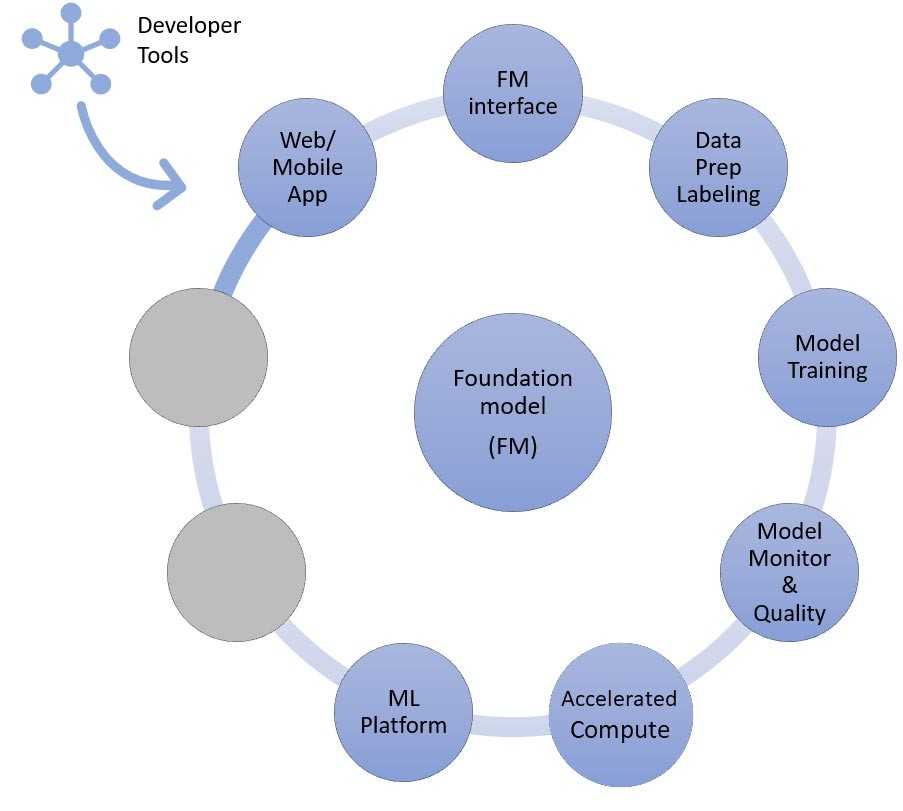
데이터 준비(전처리 또는 주석 달기라고도 함)는 더 작고 레이블이 지정된 데이터 세트가 필요한 미세 조정 시에는 특히 중요합니다. Startup은 Amazon SageMaker Data Wrangler를 사용하여 쉽게 시작할 수 있습니다. 이 서비스를 사용하면 기계 학습용 표 및 이미지 데이터를 집계하고 준비하는 데 걸리는 시간을 몇 주에서 몇 분으로 단축할 수 있습니다. 또한 전처리 워크플로를 훈련 또는 미세 조정 작업과 결합하는 데 이 서비스의 추론 파이프라인 기능을 활용할 수 있습니다.
Amazon S3의 데이터 레이크에 있는 레이블이 지정되지 않은 대량의 비정형 데이터 세트를 전처리해야 하는 Startup에게는 다음과 같은 몇 가지 옵션이 있습니다.
- Python과 인기 있는 Python 라이브러리를 사용하는 경우 AWS Glue for Ray가 유용합니다. AWS Glue는 Python 워크로드를 확장하는 데 사용되는 오픈 소스 통합 컴퓨팅 프레임워크인 Ray를 사용합니다.
- 또는 Amazon EMR 에서 Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, Presto 등의 오픈 소스 도구를 사용하여 방대한 양의 데이터를 처리할 수 있습니다.
이 접근 방식의 모델 훈련 구성 요소의 경우, Amazon Bedrock을 사용하면 자체 데이터로 FM을 전용으로 맞춤화할 수 있습니다. 이 서비스를 통해 인프라를 관리할 필요 없이 FM을 대규모로 관리할 수 있습니다(미세 조정을 위한 API 방식). 또한 SageMaker Jumpstart 접근 방식에서는 자체 데이터를 사용하여 지시 또는 영역 적응 을 위해 전용으로 미세 조정(일부 모델에서)할 수 있는 빠른 시작 솔루션을 제공합니다. SageMaker JumpStart 번들로 제공되는 훈련 스크립트를 필요에 맞게 수정하거나 오픈 소스 모델용 훈련 스크립트를 직접 가져와서 SageMaker의 훈련 작업으로 제출할 수 있습니다. 모델을 추가로 사전 훈련해야 하는 경우(일반적으로 오픈 소스 모델의 경우) SageMaker의 분산 훈련 라이브러리를 활용하여 ML 인스턴스의 모든 GPU를 가속화하고 사용 효율성을 높일 수 있습니다.
또한 Amazon SageMaker Ground Truth Plus에서 제공되는 완전관리형 데이터 생성, 데이터 주석 서비스, 인적 피드백 기법의 강화 학습 기술을 활용한 모델 개발 기능을 고려할 수도 있습니다.
아키텍처 예
그렇다면 생성형 AI 사용 사례를 구현할 때 이 모든 구성 요소는 어떤 모습일까요? Startup마다 사용 사례가 다르고 실제 문제를 해결하기 위한 고유한 접근 방식이 있기는 하지만, 생성형 AI 애플리케이션을 구축하는 과정에서 공통적으로 나타나는 주제 또는 출발점 중 하나는 검색 증강 생성 접근 방식입니다. 위에서 설명한 모든 AWS 서비스를 적용한 아키텍처는 다음과 같습니다.
데이터 모으기 파이프라인 - 영역별 데이터 또는 독점 데이터는 텍스트 데이터로 전처리됩니다. 임베딩 프로세스를 통해 생성되거나 업데이트될 때 배치 처리(Amazon S3에 저장)되거나 스트리밍( Amazon Kinesis 사용)되며 고밀도 벡터 표현으로 저장됩니다.

검색 파이프라인 - 사용자가 벡터 표현에 저장된 독점 데이터를 쿼리하면, k 최근접 이웃(kNN) 또는 시맨틱 검색을 사용하여 관련 문서를 검색합니다. 그런 다음 일반 텍스트로 다시 디코딩합니다. 출력은 프롬프트의 풍부한 고밀도 컨텍스트 역할을 합니다.

요약 생성 파이프라인 - 검색된 문서에서 인사이트 또는 요약을 도출하기 위해 프롬프트에 원래 사용자 쿼리와 함께 컨텍스트가 추가됩니다.

LangChain과 같은 개발자 도구를 사용하여 단 몇 줄의 코드로 이러한 모든 계층을 구축할 수 있습니다.
결론
이 접근 방식은 AWS 서비스를 사용하여 엔드-투-엔드 생성형 AI 애플리케이션을 구축하는 방법 중 하나입니다. 선택하는 AWS 서비스는 해당하는 사용 사례 또는 맞춤형 접근 방식에 따라 달라집니다. 이 링크를 즐겨찾기에 추가하여 생성형 AI의 최신 AWS 릴리스, 솔루션 및 블로그에 계속 관심을 가져 주시기 바랍니다.
AWS에서 생성형 AI 애플리케이션을 구축해보세요. AWS에서 시작하는 데 필요한 리소스를 제공하는 Startup 및 초기 단계 기업가를 위해 특별히 마련된 무료 프로그램인 AWS Activate를 통해 생성형 AI 여정을 시작하세요.

Hrushikesh Gangur
Hrushikesh Gangur는 AWS 기계 학습과 네트워킹 서비스 모두에 대한 전문 지식을 갖춘, AI/ML Startups를 위한 수석 솔루션스 아키텍트입니다. 그는 생성형 AI, 자율 주행 자동차 및 ML 플랫폼을 구축하는 Startups가 AWS에서 효율적이고 효과적으로 비즈니스를 운영할 수 있도록 지원합니다.
이 콘텐츠는 어떠셨나요?