AWS Partner Network (APN) Blog
Data-driven optimization and AI-powered orchestration for Nextflow with Fovus on AWS
By: Quang Minh Le, Founding Software Engineer
By: Sunny Sharma, Founding PMM, HPC & AI
By: Gokhul Srinivasan, Senior Partner Solutions Architect – AWS
By: Ragib Ahsan, AI Acceleration Architect II – AWS
 |
| Fovus |
 |
If you run Nextflow pipelines on Amazon Web Services (AWS), you’ve probably encountered a persistent inefficiency: static resource configurations that apply the same Amazon Elastic Compute Cloud (Amazon EC2) instance type uniformly across pipeline steps with fundamentally different hardware needs. Memory-bound alignment steps, single-threaded QC tools, I/O-saturating binary alignment/map (BAM) conversion, and embarrassingly parallel variant callers each share the same static resource definition. Lightweight steps are overprovisioned, more demanding steps fail and restart, and most of the Amazon EC2 instance catalog goes unused. In practice, static configurations can overspend by 70–85%. As sequencing costs have dropped from approximately $50,000 per genome in 2010 to under $200–$300 today (NHGRI), the volume of genomic data requiring computational processing has grown correspondingly. NHGRI estimates that genomic research now generates on the order of 2–40 exabytes of data annually, making computational processing the primary operational bottleneck. Pharmaceutical companies, genome centers, and clinical labs processing hundreds to thousands of samples per week feel this directly in research velocity, cost, and reproducibility.
In this post, you will see how Fovus optimizes each Nextflow process individually through per-process benchmarking and data-driven optimization, walk through benchmark results from nf-core/rnaseq and nf-core/sarek pipelines, and find out how to get started with a no cost pilot. Nextflow has emerged as the workflow language of choice for these workloads. Its containerized execution model, native AWS Batch integration, and the nf-core library of curated pipelines make it well-suited for cloud-scale genomics. Fovus, an AWS Software and HPC Competency Partner, addresses this by benchmarking each process individually and using the resulting data to assign each Nextflow process the Amazon EC2 instance type, memory configuration, parallel computing settings, and storage strategy it needs.
The challenge: Heterogeneous steps, static configs, and manual work
Fovus benchmarking of nf-core/rnaseq and nf-core/sarek reveals the spread of performance bottleneck types across their top processes:
nf-core/rnaseq process characteristics:
| Process | Primary bottleneck | Parallel scalability |
| SALMON_INDEX | Compute and memory | High |
| SALMON_QUANT | Compute and memory | High |
| TRIMGALORE | Compute | High |
| PICARD_MARKDUPLICATES | Memory | Low |
| STAR_ALIGN | Memory | Mid |
| QUALIMAP_RNASEQ | Memory | Low |
| DUPRADAR | Compute and I/O | Low |
| RSEQC_READDUPLICATION | Memory | Low |
| RSEQC_READDISTRIBUTION | Compute | Low |
nf-core/sarek (30 times Whole Genomic Sequencing (WGS)) process characteristics:
| Process | Primary bottleneck | Parallel scalability |
| BASERECALIBRATOR | Compute | Low |
| BWAMEM1_MEM | Compute | High |
| CNNSCOREVARIANTS | Compute and I/O | High |
| CNVKIT_BATCH | Memory | Mid |
| CRAM_TO_BAM | I/O | High |
| DEEPVARIANT | Compute and I/O | High |
| ENSEMBLVEP_VEP | Compute | Mid |
| FASTP | Compute and I/O | High |
| FASTQC | Compute | Low |
| FREEBAYES | Compute | Low |
| GATK4_APPLYBQSR | Compute and memory | Low |
| GATK4_MARKDUPLICATES | Memory | Low |
| HAPLOTYPECALLER | I/O and memory | Low |
| MANTA_GERMLINE | Compute | High |
| MERGE_CRAM | Compute | Low |
| SAMTOOLS_REINDEX_BAM | Memory | Low |
| SAMTOOLS_STATS | Compute | Low |
| STRELKA_SINGLE | Compute | Mid |
| TIDDIT_SV | Compute and memory | High |
A single static resource configuration can’t capture this variability. Fovus tackles this with benchmarking-data-driven optimization and AI-powered orchestration.
How Fovus works: Benchmark, optimize and run, continuously improve
Fovus integrates with Nextflow through nf-fovus, a lightweight Nextflow plugin that requires no code changes to your pipelines or containers. Your pipelines run unchanged – Fovus generates the Nextflow configuration file for nf-fovus and handles AWS orchestration.
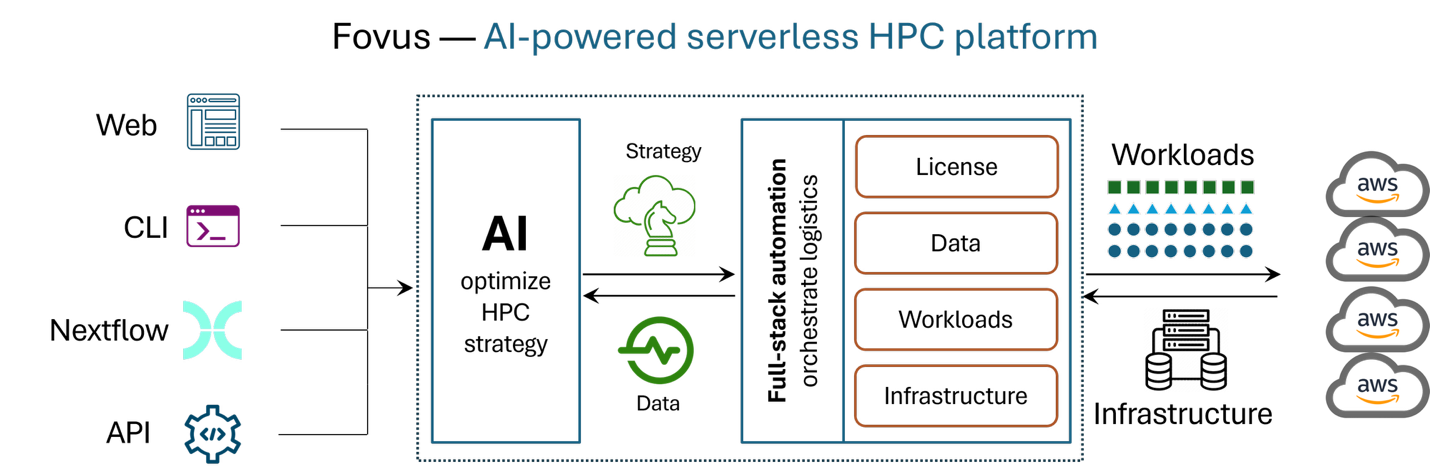
Figure 1: Fovus integration workflow
Fovus uses AWS CloudFormation to deploy a managed HPC cluster within your own virtual private cloud (VPC) with a head node in a public subnet orchestrating compute across private subnets. Fovus dynamically selects the optimal Amazon EC2 instances for each process, sizing, storage, and parallel computing settings tailored per-process. A distributed file system built on Amazon Simple Storage Service (Amazon S3) with local SSD caching provides high-performance POSIX-compatible storage for I/O-intensive steps. Inputs and outputs flow through your Amazon S3 bucket.
You can optimize your pipelines in three steps with Fovus:
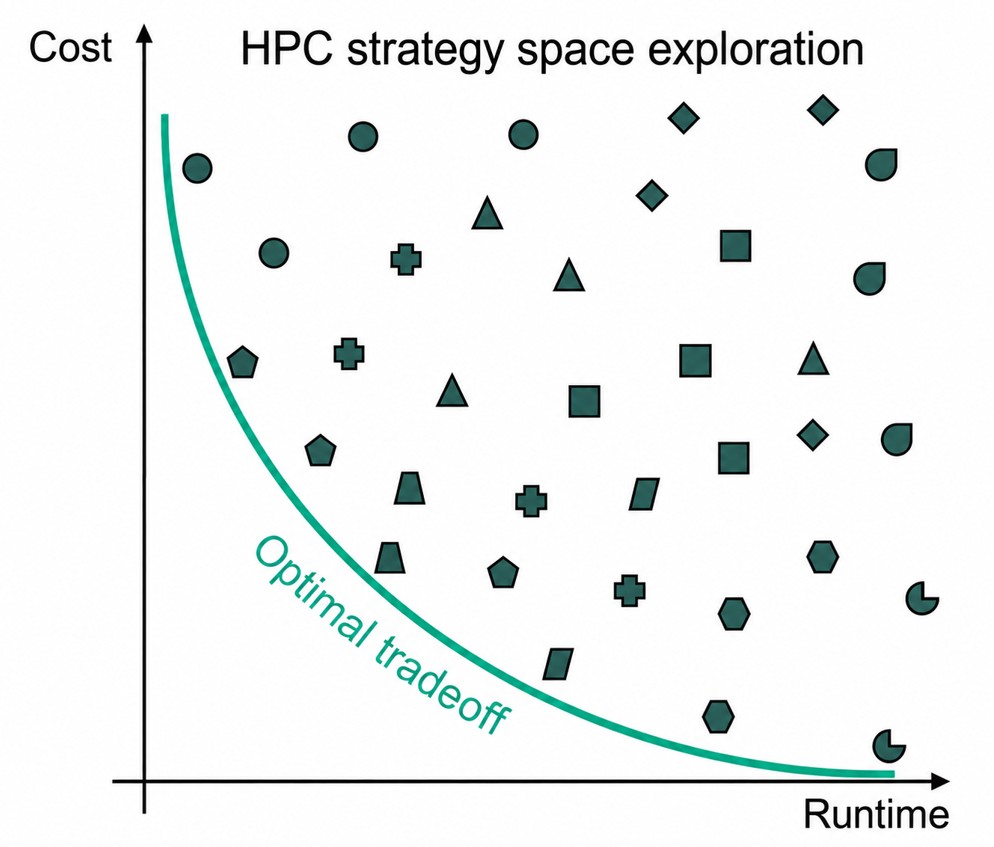
Figure 2: HPC strategy space exploration graph
- Benchmark. Fovus auto-profiles each pipeline process individually against representative inputs—measuring bottlenecks, resource consumption, and the performance impacts of applicable HPC strategies on AWS. Benchmarking runs automatically at no charge with minimal setup.
- Optimize and run. At run time, an AI optimization engine ingests the benchmark profiles and determines the optimal HPC strategy and configurations for minimizing time-cost per process. It selects Amazon EC2 instance types and sizes, Amazon Elastic Block Store (Amazon EBS) storage configurations, parallel computing settings, and Amazon EC2 Spot Instances or on-demand routing based on benchmarking data and real-time AWS instance pricing and availability dynamics. A per-run priority dial lets you balance cost against time. Running your Nextflow pipeline on AWS with Fovus requires a single command using the Fovus command line interface (CLI), or a few clicks in the web UI. There are no AWS Batch or AWS ParallelCluster environments to manage and no configuration to tune by hand.
- Continuously improve. As AWS rolls out new infrastructure, Fovus automatically updates benchmarking profiles so your pipelines use the latest technologies. This requires no workflow changes and sustains time-cost optimality as infrastructure evolves.
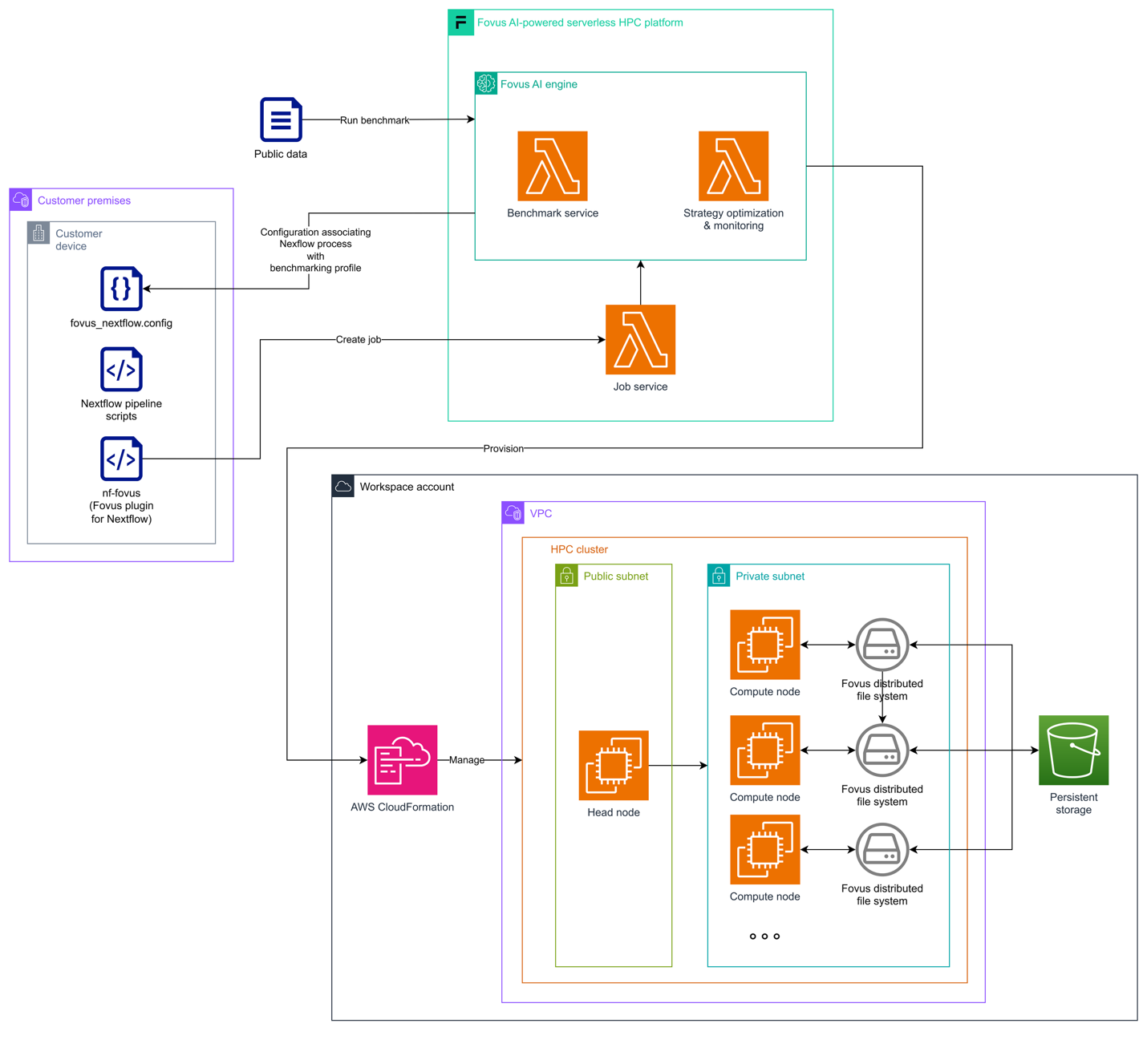
Figure 3: Fovus deployment architecture on AWS
Key capabilities:
- Per-process HPC strategy optimization: Benchmarking-data-driven, not human-guessed
- Memory checkpointing: Fovus Memguard snapshots process state at intervals and upon Spot Instance interruption. Interrupted runs auto-resume from the last checkpoint with Spot-to-Spot failover, making Spot Instances practical for long-running processes that previously required on-demand.
- Intelligent Spot Instance deployment: Automatically uses Spot Instances with Spot-to-Spot failover and availability-aware strategy optimization to improve cost efficiency.
- Hybrid strategy distribution: Ranks strategies by time and cost. Workloads automatically spill from first-optimal to second-optimal choices as capacity fills, with optional multi-Region sweeps for processes with limited I/O footprint.
- Customer guardrails: Configurable constraints on the scope of HPC strategy optimization, AWS Regions, and spend applied at the infrastructure layer.
- Distributed file system: POSIX-compatible distributed file system using local SSD as a transparent Amazon S3 cache, provisioned per-process based on measured I/O demand.
Benchmarking results
We ran nf-core/rnaseq and nf-core/sarek end-to-end on AWS with Fovus, benchmarked using automated profiling and executed with optimized per-process configurations. The following tables compare on-demand and Spot Instance costs.
Results: nf-core RNA-seq
CPU-only, test_full, eight samples, approximately 100 million paired-end reads for each sample.
| Run configuration | AWS cost with Fovus | Walltime (h) with Fovus |
| On-demand—minimize cost | $14.42 | 9h 12m 36s |
| Spot Instance with memory checkpointing—minimize cost | $5.72 | 8h 15m 36s |
As shown in the preceding table, the cost is approximately $0.70 per sample on Spot Instances—a 70–85% cost savings compared to single-config cloud deployments, providing 3–7 times higher dollar efficiency.
Results: nf-core Sarek – 30x WGS (CPU-Only*)
Test full germline (30 times WGS, single nucleotide/ondel multi-caller/structural variant/copy number variant/annotation):
| Run configuration | AWS cost with Fovus | Walltime (h) with Fovus |
| On-demand—minimize cost | $12.45 | 9h 39m 25s |
| Spot Instance with memory checkpointing—minimize cost | $6.15 | 9h 29m 2s |
Test full normal-tumor pair:
| Run configuration | AWS cost with Fovus | Walltime (h) with Fovus |
| On-demand—minimize cost | $5.30 | 4h 26m 7s |
| Spot Instance with memory checkpointing—minimize cost | $2.22 | 5h 1m 11s |
The Spot Instance run matches on-demand wall time almost exactly (9h 29m compared to. 9h 39m) while cutting cost by more than half. Memory checkpointing makes this possible: interruptions are absorbed invisibly and full Spot Instance savings are captured with no reliability tradeoff.
Note: These results reflect a CPU-only strategy. Fovus supports GPU-accelerated tools, which can deliver further improvements on wall time.
Deployment: Bring your own cloud (BYOC)
Fovus deploys directly within your AWS account: Your data, compute, and pipeline execution remain inside your existing cloud environment. Fovus is designed to support HIPAA compliance requirements and data sovereignty and aligns with your organization’s AWS security and governance policies, with no data leaving your account boundary. Pricing is consumption-based—a fee on the AWS spend managed by Fovus, with no license fees, per-seat charges, or upfront commitments. The result is lower cost or higher efficiency than unoptimized workloads, with savings that offset the Fovus cost.
Getting started: No-cost pilot
Fovus provides a pilot workspace to benchmark your pipelines and generate optimized Nextflow configurations for immediate testing on AWS. For teams already running Nextflow, migration is a single file replacement—swap your existing nextflow.config with the Fovus-generated one. No pipeline modifications, no container changes, no workflow rewrites.
Conclusion
Running a heterogeneous Nextflow pipeline under a single shared resource configuration leaves money and time behind. With Fovus, each process has its own optimized HPC strategy and configurations, determined based on benchmarking data and executed automatically through AI-powered orchestration. The results: Approximately $0.70 per sample for nf-core/rnaseq and $6.15 for a full 30 times germline WGS on Spot Instances (CPUs only). For teams on cloud or on-premises clusters, Fovus demonstrates that you can achieve lower costs and faster results by running HPC workloads on AWS.
Resources
- Fovus – Free benchmarking and pilot workspace
- AWS Marketplace – Fovus listing
- nf-core Pipeline Catalog
- Amazon EC2 Spot Instances
- NHGRI DNA Sequencing Costs Data – Source for sequencing cost figures
- NHGRI Genomic Data Science Fact Sheet –- Source for genomic data volume estimates
Note: Fovus performance and cost figures are from actual runs of nf-core/rnaseq (test_full, 8 samples, approximately 100 million PE reads) and nf-core/sarek (30 times WGS, SN/Indel multi-caller/SV/CNV/annotation). AWS costs reflect Amazon EC2 and Amazon EBS charges at time of execution. Results vary by pipeline, input data, AWS Region, and prevailing Spot Instances pricing. Speed and cost comparisons are based on unoptimized single-config cloud deployments.
.
 .
.
Fovus – AWS Partner Spotlight
Fovus is an AWS Advanced Technology Partner that provides an AI-powered serverless HPC platform that simplifies and optimizes cloud HPC for enterprises. It provides intelligent, scalable, affordable supercomputing power at your fingertips to accelerate scientific discoveries and engineering breakthroughs, helping you achieve more with less.