AWS Partner Network (APN) Blog
How APN Premier Partner Infosys Uses AWS to Provide a Boundaryless Architecture Solution
 |
 |
By Karthik Mohan and Rajeev Rangachari, Senior Architects at Infosys
By Jignesh Desai, Partner Solutions Architect at AWS
In an era where always-on connectivity, the Internet of Things (IoT), and unstructured data in the public domain are the new normal, the ability of companies to compete and differentiate rests on their ability to leverage data and analytics.
Winning companies take advantage of the wealth of information available to create valuable insights and act on them. We call these organizations analytics-driven enterprises, and they use actionable insights to deliver on the promise of data monetization.
That said, these enterprises could further move up the value chain by adopting cloud-based technologies. Based on our experience working with different clients, we noticed that more and more enterprises are adopting cloud technologies not just for IT support but also for business functions. In this post, we explore how Infosys is leveraging Amazon Web Services (AWS) to provide clients with a solution based on Boundaryless Architecture.
Infosys is an AWS Partner Network (APN) Premier Consulting Partner with AWS Competencies in both Migration and Financial Services. Infosys is also a member of the APN Managed Service Provider (MSP) Program and Public Sector Partner Program.
Challenges in Traditional Data Warehouses
To deliver on actionable insights, the flow of information needs to be uninterrupted and untangled—unlike traditional information flows we have witnessed. This uninterrupted flow is difficult to achieve because organizations tend to create boundaries in their data landscapes. Based on several of our customer interactions, one of the major pain points that surfaces time and again is that 75-80 percent of the time is spent on integration of the data, and only the remaining effort is available for deriving insights.
Types of boundaries include:
- Infrastructure and Deployment: Every enterprise deploys its solutions to various data centers and cloud-based infrastructures. These are natural physical boundaries where data accumulates.
- Application and Process: Most organizations are designed around a process-oriented paradigm. If the design does not consider enterprise information architecture, it can lead to stovepipes of data.
- Machine-Generated Data: Clickstream data, log data, IoT data, and new age data sources fall into this category. Large volumes of data need to be integrated. For example, clickstream data that encapsulates customers’ online behavior must be combined with data from other interaction channels to present a complete view of the customer to the enterprise.
- Department/Portfolio: Departments and portfolios of an organization can resemble separately governed states. They have their own language (semantics) and data collection systems. It’s at their boundaries that you see operational data store (ODS) and sometimes data warehousing (DW) solutions that standardize the semantics between units.
- Enterprise: At the enterprise level, data must be structured to facilitate agility, easy access, and early indicators for change. The challenge, however, is that this data must be examined through different perspectives to gain valuable insights.
- Industry: At the industry level, business information-sharing typically happens through marketplaces. There is a new trend emerging within data monetization initiatives where individual companies offer industry data that other players can consume. For example, RosettaNet, a nonprofit consortium, enables such information exchange.
In Figure 1, you can see how different data silos are formed in an organization’s data warehouse.

Figure 1 – Informational data silo representation
Native AWS-Based Boundaryless Architecture
Infosys Boundaryless Architecture strives to eliminate physical boundaries to provide seamless and secure access to all data sets. We enable this through metadata-driven physical and virtual integration services and a data catalog-based democratization service.
The diagram in Figure 2 shows the high-level architecture of the Boundaryless Architecture Framework. You see the different modules that form the solution and how they interact with each other.

Figure 2 – Native Boundaryless Architecture tiers
Walkthrough of Important Modules/Tiers
Intake Tier
The ingestion process uses native libraries of the source system to extract data. This makes extraction fast and scalable. Because it’s metadata driven, any new table/file to be ingested needs minimal configurations to be up and running. The orchestration can be set up through enterprise scheduling tools. The entire ingestion framework, maintained in the form of Java Archive (JAR) files, is easy to “lift and shift” for quick deployment and setup.
Both structured and unstructured data extracted from the source is stored as-is in an Amazon Simple Storage Service (Amazon S3) landing zone.
Data Processing and Data Lake Tier
These tiers form the heart of the framework and are set up to interact with each other. Using Hive, Pig, and Spark components available in Amazon EMR, each data set undergoes a specific cleansing and enrichment process that is defined in business rules. Data is then transformed and aggregated at the required level of granularity for analytics and business intelligence workloads. It is maintained in curated and aggregated data zones. Processed data sets are then stored in Amazon S3 in logical groupings.
Data Democratization and Consumption Tier
Data is no longer a luxury of data scientists alone. Omnichannel data is available even for an average end user or analyst. For example, you can easily run models or R code by setting up R with Amazon EMR. RStudio is a popular integrated development environment (IDE) for such usage.
For data visualization, we can have state-of-the-art tools like Tableau connected to Amazon Redshift for real-time data querying. In addition, the solution supports the REST API, which opens a gateway to ship data to any external apps for consumption.
Sample Implementation: How Each AWS Component Fits In
The architecture diagram in Figure 3 shows how the Boundaryless Architecture Framework was implemented for a client and how various AWS components fit in. The client, a major retailer, had some inherent bottlenecks in its solution.
Some of these bottlenecks included the following:
- No standard ingestion framework. Each IT team was free to ingest data using the tool it preferred.
- The data that was being ingested didn’t go through any enterprise hardening process.
- Results of these isolated processes had an impact on the consumption layer. The client’s data scientists were concerned the processes were undermining the purpose of building a data lake.
These challenges were overcome by deploying a solution leveraging native AWS components that complemented the AWS ecosystem and accelerated development. A metadata-driven ingestion framework was deployed, which drastically reduced development time. The data was then pulled to Amazon S3, and Amazon Redshift was leveraged for the consumption layer. Figure 3 shows how data ingested from different source systems are processed through different layers before it finally reaches the consumption layer.
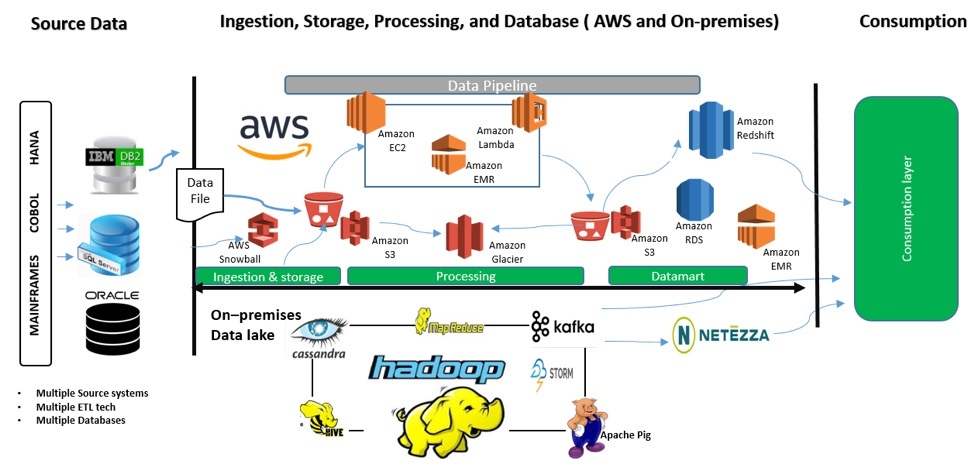
Figure 3 – Sample Boundaryless Architecture implementation
Information Grid – UI (Sample Pages)
Information Grid provides a user interface (UI) for setting up an end-to-end data flow. The details like Metadata Management, New Template Creation, and Orchestration can be set up from the UI. The screenshot in Figure 4 shows the Infosys Information Grid homepage, which showcases different Modules.

Figure 4 – Infosys Information Grid home page
Template Registration
Templates are a representation of a single ingestion process and is mainly classified based on the source and target type of the data flow. For example, files-based ingestion and table-based ingestion will have different templates and ingestion mechanisms. Even within table-based ingestion, you can create a specific template for a type of source and target system, such as a template for Oracle-to-Teradata data ingestion process.
Once a template is registered with details of the systems and connection parameters, developers can reuse the template and just provide details specific to their requirement like table names or column names. The template takes away the need for a developer to keep track of system details every time he or she needs to ingest data.
Connection Management
As the name suggests, this module keeps track of all the connection details used by the different ingestion templates. It’s a single point of control from where connection details can be updated.
Metadata Configuration
The ingestion process is metadata driven. For each ingestion process, details like source/target table name, columns to be fetched, columns to be transformed, incremental columns, and other table specific details can be stored in a metadata table. This page helps in creating and editing the metadata entries.
Scheduler
Any enterprise-level scheduling tool can be used for orchestrating the ingestion jobs. This page helps in creating the scheduling jobs.
Execution History and Audit
Every run of ingestion jobs is tracked here. The developer or support teams can get the details of job status from this page, including failure details. Audit works in relation to the execution history. It provides a mechanism to build an audit report on the general health of the ingestion jobs, or it can be a report on a set of tables grouped logically, such as an audit report that is scheduled every day to track the completion of sales-related tables within the service level agreement (SLA).
The screenshot in Figure 5 shows the Metadata Setup page. Here, details like source/target information, connection details, partition details, ingestion logic, and Amazon S3 Key details (wherever applicable) for a table are set up.

Figure 5 – Infosys Information Grid metadata page
Next Steps
Infosys Boundaryless Architecture, with components like the Information Grid built on AWS, can improve an enterprise’s seamless data lake building capability and achieve data democratization. Boundaryless Architecture-based solutions improve the ability of developers, data scientists, and business stakeholders to gather insights and monetize data with higher efficiency.
For further details and information, please reach out to the Infosys Marketing Team who can set up a demo and give you a detailed walkthrough.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
Infosys – APN Partner Spotlight
Infosys is an APN Premier Consulting Partner. They have AWS Competencies in Migration and Financial Services, and are members of both the MSP and Public Sector Partner Programs. Infosys helps enterprises transform through strategic consulting, operational leadership, and co-creation of breakthrough solutions in mobility, sustainability, big data, and cloud computing.
Contact Infosys | Practice Overview | Customer Success | Buy on Marketplace
*Already worked with Infosys? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.