AWS Partner Network (APN) Blog
How Public AI delivers sovereign LLM inference on AWS and Intel
by: Nicolas Jourdan, Sr. Specialist Solutions Architect AI/ML – AWS
by: Diego Bailón Humpert, Global AWS Data & AI/ML GTM Lead – Intel
by: Malte Reimann, Solutions Architect – AWS
by: Joshua Tan, Product Lead – Public AI
 |
| Intel |
 |
When research institutions release open-weight large language models (LLMs), their work is largely done. The weights land on services such as Hugging Face, the paper gets published, and the team moves to the next project. But for the businesses and public institutions that want to actually use these models, the work is only beginning. They need API endpoints, auto scaling infrastructure, and integration paths that no research lab is set up to provide.
This gap is showing up everywhere sovereign AI is being built. National initiatives such as Swiss AI train multilingual models, AI Singapore builds Southeast Asian language models, and the Allen Institute for AI (Ai2) releases models with open weights, training code, and training data. Each publishes weights and research, but none operates production inference services. That isn’t their mission.
The Public AI Inference Utility (IU) has changed that. It deploys sovereign open-weight models on Amazon Elastic Compute Cloud (Amazon EC2) instances powered by Intel processors, exposing public inference endpoints so organizations can test and integrate these models without provisioning their own infrastructure. Amazon Web Services (AWS) provided the managed infrastructure to launch quickly within Swiss jurisdiction; Intel-powered EC2 instances made the architecture cost-effective enough to replicate across other sovereign initiatives.
In this post, we walk through how Public AI built a production inference platform on Amazon Elastic Kubernetes Service (Amazon EKS) and Intel-powered EC2 instances for the Apertus model launch, and why that architecture is replicable for other sovereign LLM initiatives.
“Training the model was our contribution to open AI research. AWS makes our innovation easily accessible to any organization that can now run our model privately on AWS global infrastructure.” — Martin Jaggi, Associate Professor at EPFL and Head of Machine Learning and Optimization Laboratory
What is Public AI?
Public AI is a global initiative to build AI as public infrastructure, open, auditable, and governed in the public interest. It brings together governments, research institutions, and open source communities to deploy sovereign AI systems that are accessible and transparent.
The Public AI Inference Utility is the operational core of this vision: a distributed inference layer that aggregates compute from partners (including national labs, cloud providers, and public institutions) and exposes it through a unified API and chat interface. By pooling infrastructure and demand across jurisdictions, the IU reduces duplication, improves utilization, and provides a viable alternative to closed AI ecosystems. In practice, it allows newly released open-weight models to be served reliably at scale while preserving data privacy and enabling local governance.
Why Public AI chose AWS
Public AI is the international launch partner of the Swiss AI initiative, providing inference access to the Apertus model family, Switzerland’s first large-scale, fully open, multilingual LLM developed by EPFL, ETH Zurich, and the Swiss National Supercomputing Centre (CSCS). A publicly accessible inference endpoint is essential for newly released models: companies, public institutions, and developers want hands-on experience with a model before committing to their own hosting on services such as Amazon SageMaker AI.
As a nonprofit, open-source community with lean engineering resources, Public AI faced a demanding launch. The Apertus release was expected to draw thousands of concurrent users at peak, and popular open source inference stacks such as vLLM didn’t support the Apertus architecture until only weeks before the model release. The goal was clear: deliver a scalable inference interface (both a chat-style UI for broad accessibility and an API for developers) within a narrow timeline.
AWS provided the infrastructure foundation and hands-on expertise to make this possible. Early in the process, AWS solutions architects and specialists worked with the Public AI team on enablement sessions, reference architectures, and guidance on service selection. Together, they built a production stack in the AWS Europe (Zurich) – eu-central-2 Region, which kept inference workloads and user data within Swiss jurisdiction, a key requirement for sovereign AI deployment.
The architecture is a fully containerized stack on Amazon EKS Auto Mode, designed so a single inference request flows cleanly from user to model and back:
- Entry – End users reach a hosted Open WebUI chat interface; developers connect through an API gateway. Both paths are protected by AWS WAF, with Amazon CloudFront fronting the chat interface.
- Authentication – Amazon Cognito handles user identity and access for both interfaces.
- Routing and inference – Requests are routed through a gateway layer to auto scaling vLLM deployments. The Apertus 8B variant runs on Intel-powered Amazon EC2 R8i instances; the larger 70B variant runs on GPU-powered instances. Check the Amazon EKS best practices guide for CPU inference to dive deeper.
- Responsible AI – Amazon Bedrock Guardrails enforces safety policies including blocking of prohibited topics across both model variants inline with each request.
- State and storage – Amazon Aurora Serverless v2 PostgreSQL-Compatible Edition handles persistent data, Amazon ElastiCache for Valkey provides caching, Amazon Simple Storage Service (Amazon S3) stores objects, and Amazon Elastic File System (Amazon EFS) shares files across pods. Container images are managed in Amazon Elastic Container Registry (Amazon ECR).
This architecture, shown in the following diagram, gives Public AI what a sovereign, nonprofit inference provider needs most: the ability to go from zero to production scale quickly within a specific jurisdiction, scale with demand, and operate reliably, without building or managing physical infrastructure.
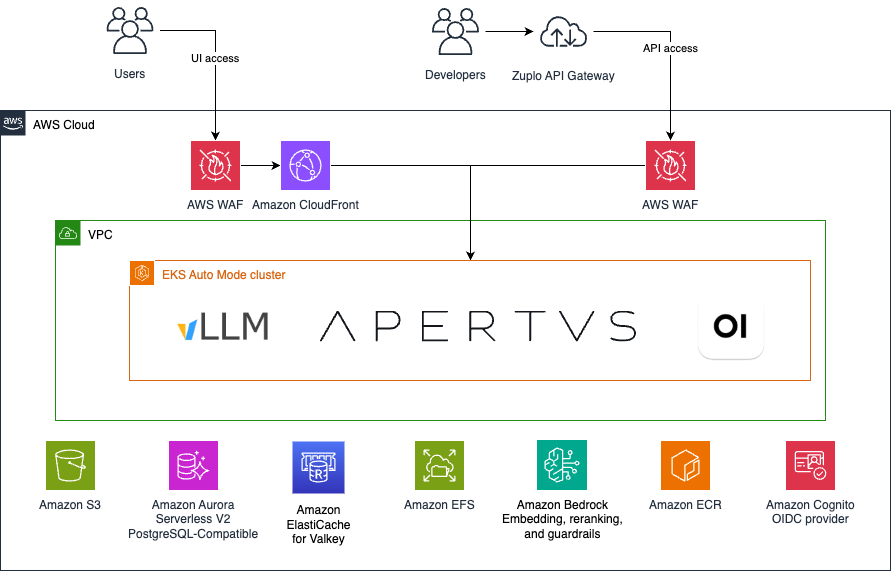
Figure 1: Solution Architecture
How Intel provides choice for sovereign inference
With the Apertus deployment running, Public AI turned to the next challenge: how to scale from one model in one country to many sovereign LLMs across many jurisdictions. That requires an inference platform that is cost-effective for budget-conscious research institutes, built on open source software to provide transparency, and available in every region where sovereign models need to run.
Intel-powered EC2 instances meet all three requirements. Intel Xeon processors are available across the full spectrum of AWS deployment options: AWS Regions worldwide, AWS Local Zones for low-latency metropolitan deployments, and AWS Outposts for on-premises workloads that must remain within national boundaries. This broad availability means Public AI can replicate its inference architecture in new jurisdictions without re-engineering the stack. Each European research institute can select the deployment model that fits its sovereignty, latency, and regulatory requirements while running the same Intel Xeon-based infrastructure underneath.
For smaller language models—the 8B-parameter class that many sovereign initiatives produce—Intel-powered EC2 R8i instances offer a cost-effective alternative to specialized AI accelerators. R8i instances deliver up to 40% higher performance on deep learning inference workloads compared to the previous R7i generation, reducing total cost of ownership while providing ample compute for production inference. The open source ecosystem around Intel architecture, including optimized LLM serving with vLLM on Intel, lets research institutes deploy standardized inference frameworks without licensing fees or proprietary dependencies.
Conclusion
Since its launch, the Public AI Inference Utility has served thousands of active users daily and sustained thousands of concurrent users at peak—researchers, developers, public institutions, and enterprises exploring what a sovereign, multilingual LLM can do for their use cases. That sustained demand confirms that the architecture built on Amazon EKS, Intel-powered EC2 instances, and other AWS services can handle real-world production traffic while maintaining performance, security, and data residency.More importantly, the Apertus deployment established a repeatable blueprint. As governments and research institutes continue to train open-weight models—each with their own language coverage, compliance requirements, and sovereignty constraints—the need for a turnkey inference layer grows. Public AI, powered by AWS infrastructure and Intel’s broadly available Xeon-based compute, is positioned to onboard new models quickly, deploy them within the required jurisdictions, and give organizations an immediate path from published weights to usable API endpoints.Organizations evaluating sovereign LLM deployment can get started in three places:
- Try the live Apertus endpoint at Public AI to see what the model can do.
- Review the Intel Xeon for small language model inference guide and Amazon EC2 R8i instance documentation to evaluate the compute layer for your own model.
- Contact your AWS account team to discuss reference architectures for your jurisdiction.
The blueprint Public AI established for Apertus is ready to onboard the next sovereign LLM, whichever country, language, or research institute it comes from.

Intel – AWS Partner Spotlight
Intel and Amazon Web Services (AWS) have collaborated for over 20 years to develop flexible technologies and software optimizations tailored for critical enterprise workloads. This collaboration allows our AWS Partners to help their customers migrate and modernize their applications and infrastructure to manage cost and complexity, accelerate business outcomes, and scale to meet current and future computing requirements.