AWS Partner Network (APN) Blog
How to Create a Continually Refreshed Amazon S3 Data Lake in Just One Day
By Pradnya Bhandary, Co-Founder at Bryte Systems
By Srinivas Kesanapally, Sr. Partner Solutions Architect, Data & Analytics at AWS
 |
Data management architectures have evolved drastically from the traditional data warehousing model, to today’s more flexible systems that use pay-as-you-go cloud computing models for big data workloads.
With Amazon Web Services (AWS), applications can easily scale up and down based on demand. As requirements change, environments can be resized both horizontally and vertically. This can be done on AWS without having to wait for additional hardware, or being required to over-invest to provision future capacity.
Separation of storage and compute is a key feature of modern data architecture. Legacy data analytics platforms like Hadoop or data warehouses always had compute and storage coupled tightly, making it inflexible for large volumes of data processing or for unanticipated, huge scaling of computing power.
The popularity of the data warehouse eventually led to its demise, though, as it could not scale to meet the demand generated by users.
In this post, we will explain how AWS services like Amazon EMR can be used with the BryteFlow software to deploy an Amazon Simple Storage Service (Amazon S3) data lake in one day, and drastically reduce deployment times. We will also detail how AWS and BryteFlow can automate modern data architecture to significantly accelerate delivery and business insights at scale.
The BryteFlow software was developed by Bryte Systems, an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency. BryteFlow is self-service and orchestrates the various AWS services while using best practices and design principles.
Amazon S3 Data Lakes
Amazon S3 is the core service at the heart of the modern data architecture. Amazon S3 is unlimited, durable, elastic, and cost-effective for storing data or creating data lakes.
A data lake on S3 can be used for reporting, analytics, artificial intelligence (AI), and machine learning (ML), as it can be shared across the entire AWS big data ecosystem.
Once the data is available on S3, various AWS services can be used to consume the data for reporting, analytics, ML, or ad hoc queries.
Amazon Athena allows you to use S3 data for ad hoc queries using SQL, or with visualization tools for dashboards. Amazon Redshift Spectrum allows you to query data as external tables from Amazon Redshift, which is the AWS data warehousing service.
About BryteFlow
BryteFlow automates the modern data architecture by providing real-time data integration to Amazon S3, Amazon Redshift, and Snowflake, an APN Advanced Technology Partner that makes modern data warehousing effective, affordable, and accessible to all data users within the organization.
There are several options for flexible workloads that you can read about in How BryteFlow Works. BryteFlow can be procured through AWS Marketplace, and the data remains in the customer’s virtual private cloud (VPC).
BryteFlow Ingest for Data Ingestion
- Change data capture to Amazon S3 from transactional sources like SAP, Oracle, SQL Server, MySQL, etc.
- Ingestion from any API in a set file format on Amazon S3.
- Ingestion from any flat file in a set file format on S3.
- Automated data merge with SCD type2 history.
- BryteFlow XL-Ingest can scale to bring terabytes of data to S3
BryteFlow Blend for Data Preparation
- Real-time data preparation with a drag and drop GUI interface means users can drag connectors between sources and destinations, and set up a job in minutes.
- Enterprise-grade scale and performance.
BryteFlow TruData for Data Reconciliation
- If ingesting transactional data using CDC, automated data reconciliation between source and destination is provided to make sure the data is trustworthy and complete.
- Reconciliation can be configured to proceed in parallel with replication, so data processing is sped up.
BryteFlow integrates seamlessly with AWS services such as AWS Lake Formation and AWS Glue Data Catalog, to deliver a highly secure, scalable, flexible, and performant analytics environment.
The architecture diagram below shows the modern data architecture implemented with BryteFlow on AWS, and the integration with the various AWS services to provide a complete end-to-end solution.

Figure 1 – Modern data architecture with BryteFlow on AWS.
Continual Refresh vs. Capturing Changed Data Only
Data insights are only as good as the data that drives them. Hence, the need for current, updated data.
Getting high quality, current data is a struggle for many organizations, however. Some rely on full nightly extracts to refresh their analytics platform. This simplifies the process and removes complexity around getting deltas or changes, merging changes, and verifying that none of the changes are missed or that data is complete.
This approach is not sustainable for most businesses. As data volumes increase, the potential challenges are:
- Increased load on the operational sources interfere with operational tasks.
- Long running queries on the source system are brittle and susceptible to failing regularly.
- Loading times on target increase and data is not available on time for analytics.
In some instances, due to the large volumes of transactional data, a full refresh may just not be feasible.
A better design pattern is to capture only the deltas or changes. This can be a continual process that happens in real-time, or at a frequency specified by the user. Furthermore, transformations can also be triggered in a timely fashion on the changed data only. Yes, this does add to complexity, but it’s all automated within the BryteFlow software.
Complexity in Processing Changes Only
Other solutions deliver changes to Amazon S3 but need complex coding to make the data in the data lake usable.
This approach also needs ongoing maintenance, and sometimes teams of five or more engineers work on getting the data to the data lake and making it usable for analytics and data science use cases. This can drive up the Total Cost of Ownership (TCO).
The challenges faced by engineers are:
- Multiple change records for the same row within one incremental data file.
- Incremental data file can have an insert followed by update for the same row, or a delete, and there can be several pairs of this.
- False versioning, where a timestamp field gets updated every second. In this case, there are too many changes that are audit-related and then discarded.
- Size, where the incremental data file can be very small or large depending on the table.
- Several thousand tables can be continually updated, and they can be small or large.
- Every change may need to be preserved with SCD Type 2 history on Amazon S3, which makes the data ideal for use for point-in-time analytics.
- Raw data needs to be current and updated continually for it to be used in analytics, machine learning models, and insights.
- Continually updated data reconciliation and data transformations.
Rome Wasn’t Built in a Day, but an Amazon S3 Data Lake Can Be
The infrastructure costs for building an Amazon S3 data lake are modest, and BryteFlow helps by shaving off months on the implementation. It can also cut down on ongoing maintenance, lowering the overall TCO of the solution.
Note that the time to build does not include the time for getting access, connectivity, troubleshooting network issues, or any other infrastructural issues addressed. It assumes that all access is available, and all prerequisites have been completed as listed in the manual. It also assumes that data up to 100GB is being ingested, as the initial refresh depends on the network speeds.
Building a Raw Data Lake in 4 Steps
In this next section, we’ll look at how to build a continually refreshing raw data lake in one day. To get started, you’ll want to procure the Enterprise edition of BryteFlow from AWS Marketplace.
We suggest spinning up an Amazon EMR cluster with the following configuration:
- Master node – m4.large
- Core node – m4.large
- Task nodes – c5.xlarge. The number of task nodes can be increased if required.
Next, use the BryteFlow Ingest software and follow these steps:
- Set up the source connection details, assuming the source is SQL Server.
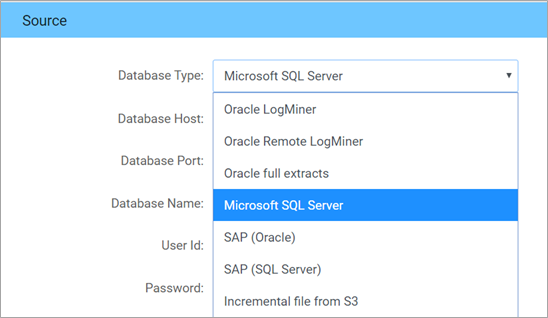
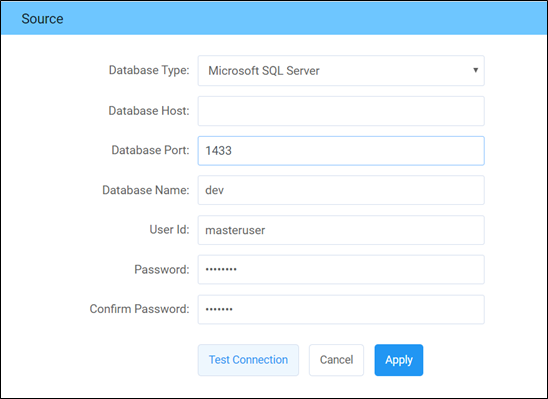
- Set up the source connection details. The source can be on the cloud or on-premises.
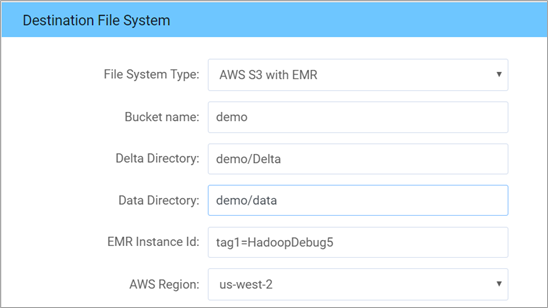
- Set up the destination connection details. The destination can be S3, Amazon Redshift, both, or Snowflake.
- Set up the table(s) to be replicated.

- Schedule your data replication time and data lake build.
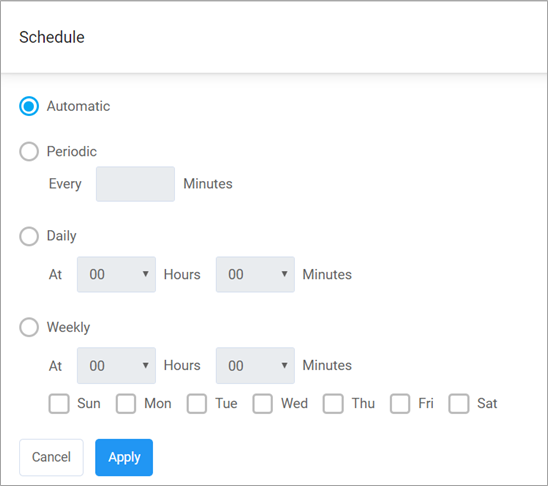
Please follow the manual for additional configuration options as per your environment. To test this out, choose smaller tables and then build up.
This should set up your raw data lake that is ready to use. There is no coding required, and the data lake can be configured with automatic SCD Type 2 history as well.
Building a Transformed Data Lake in 2 Steps
A prerequisite for this is a raw data lake set up as per the instructions in the previous section of this post. It’s assumed the raw data lake is being refreshed continuously.
Use the BryteFlow Blend software for the steps below. The software uses the configurations from BryteFlow Ingest, so the setup will be minimal.
- Create a transformation job by selecting Add New Job and editing it. Enable the job to run on Ingest Load, which triggers the transformation every time data is landed into the raw data lake. Write the transformed data to the transformed data lake.
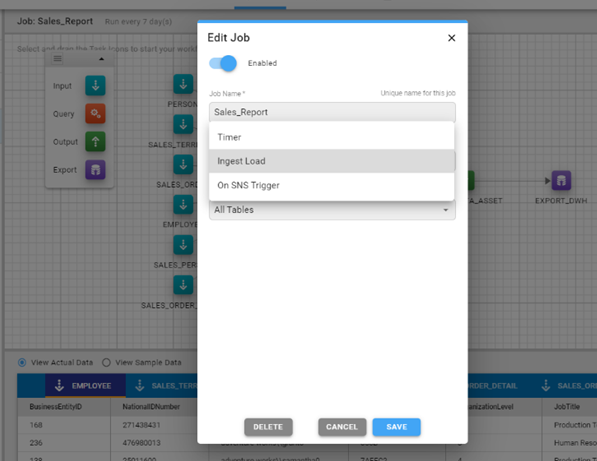
- Build your transformations using the Query icon. Land the data back to S3 and optionally export it to Amazon Redshift, Snowflake, or Amazon Aurora.
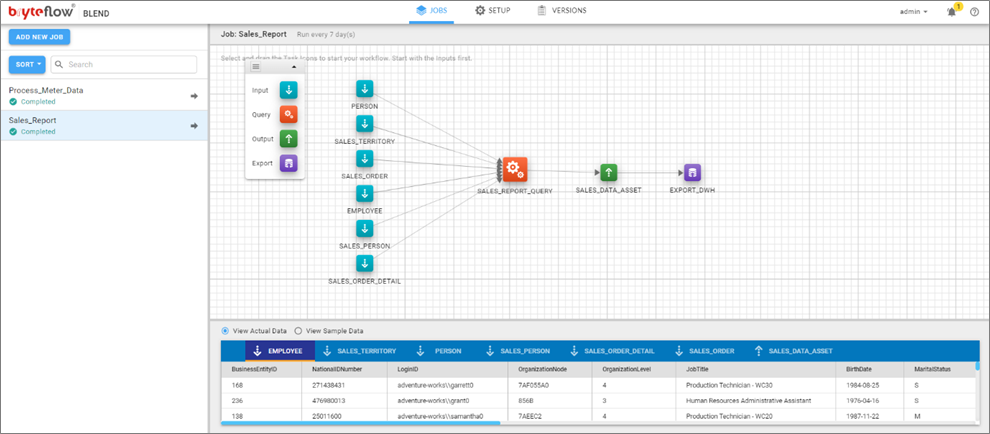
Please follow the manual for additional configuration options as per your environment. To test this out, choose smaller tables and then build up.
Building a Reconciled Data Lake in 2 Steps
Any table can be reconciled against the source, to ensure the data is accurate and hasn’t been missed in the data lake.
This process can be configured in the BryteFlowTruData software, so that data is reconciled continually while ensuring no data is missed in the replication or processing. This uses the configuration details from BryteFlow Ingest, and requires minimal set up.
- Select the tables, partial tables, or specific columns from tables that need to be reconciled. Configure the table details.
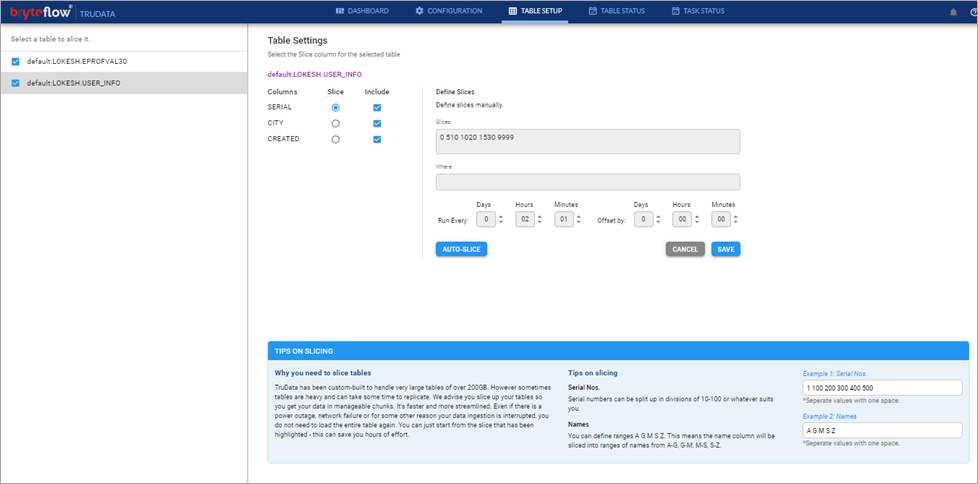
- Monitor the tasks and table status.
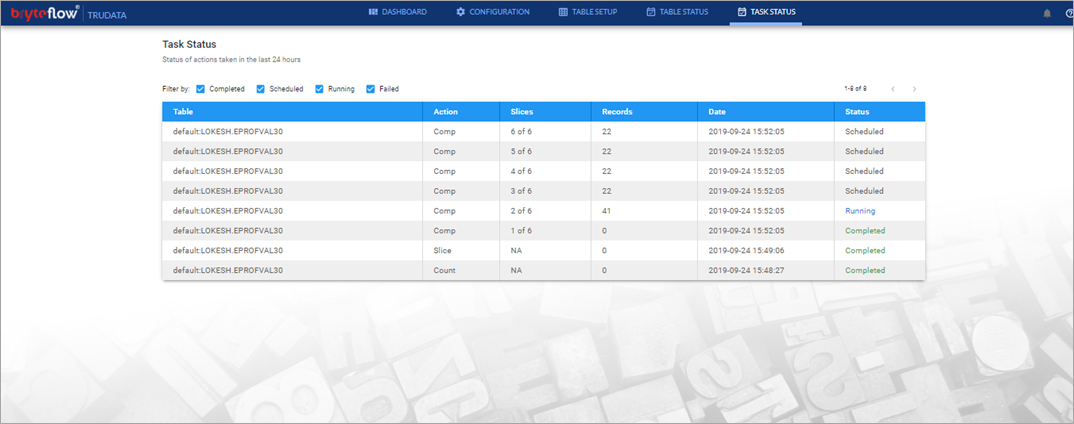
- Monitor the overall progress with the dashboard.
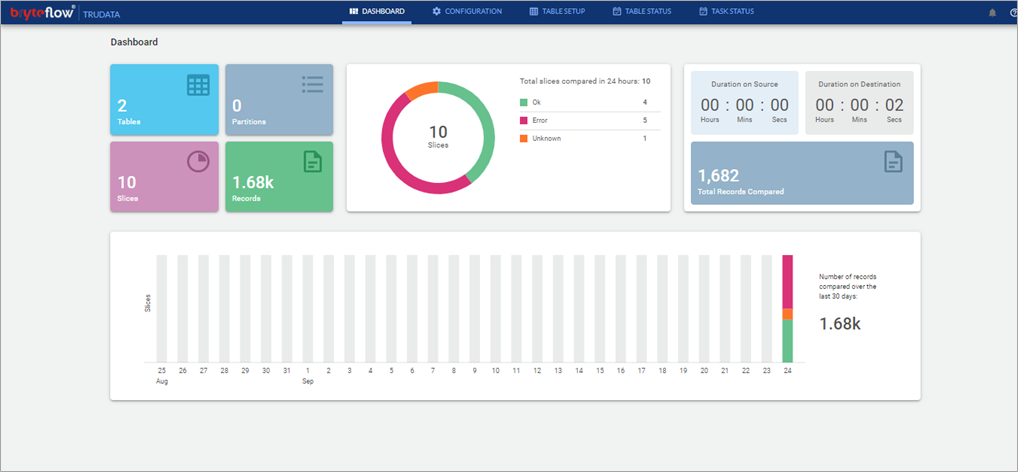
Please follow the manual for additional configuration options as per your environment. To test this out, choose smaller tables and then build up.
Building a Data Lake at Scale in 2 Steps
Choose a large table (>30GB) to build a data lake at scale using the BryteFlow XL-Ingest software, and then have it refreshing continuously as per the raw data lake using BryteFlow Ingest.
The tables can be any size, as terabytes of data can be brought across efficiently. For this exercise, however, let’s keep the table size to 100GB. Also, you can get partial data across; for example, if only the data for the last two years is needed.
- Configure the large table to be brought across.
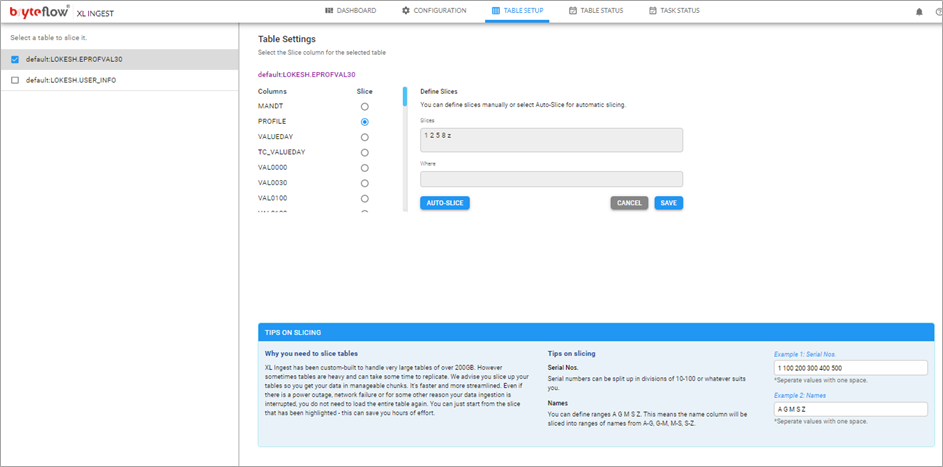
- Monitor the process, as the table is brought across. The table is optimized on Amazon S3 with compression and partitioning and is ready to use. Overall status is displayed on the dashboard.
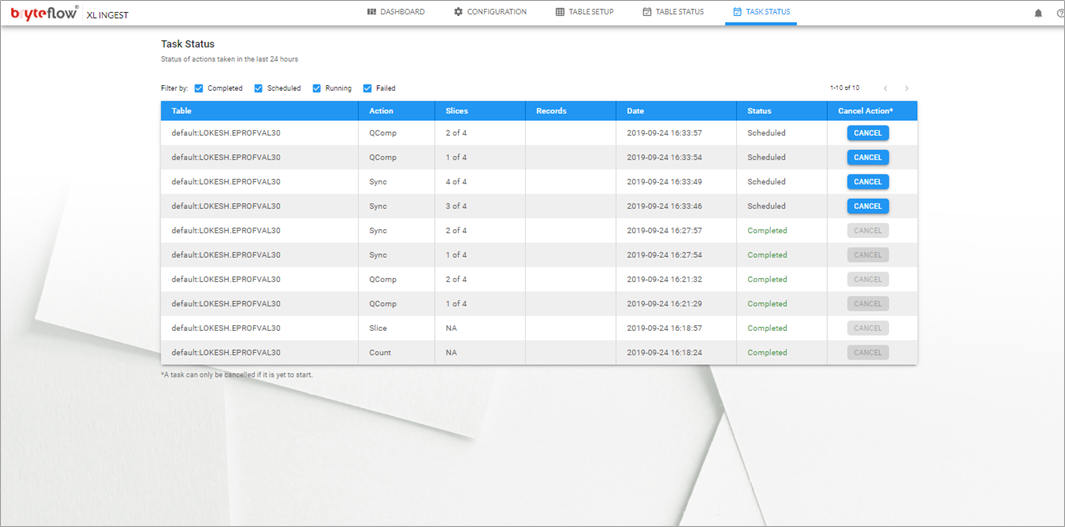
Please follow the manual for additional configuration options as per your environment. To test this out, choose smaller tables and then build up.
Summary
In this post, you have learned how to use the BryteFlow software to create a data lake on Amazon S3 with data that is continually refreshed, reconciled, and transformed. We explored how to create curated data assets with the data, and explored support for large data sets.
We also have our data on Amazon S3 and either on Amazon Redshift or Snowflake, which is ready to use for data insights, analytics, machine learning, and other use cases. The data is future proof as it’s available on S3 and can be shared across the organization and deployed across various use cases.
To experience the BryteFlow created data lake on Amazon S3, start with the free trial. Contact support@bryteflow.com for a free training course, or if you need a hand setting it up.
.

.
Bryte Systems – APN Partner Spotlight
Bryte Systems is an AWS Competency Partner. Its BryteFlow solution automates modern data architecture to significantly accelerate delivery and business insights at scale, while driving real-time data replication and integration for Amazon S3, Amazon Redshift and Snowflake.
Contact Bryte Systems | Solution Overview | AWS Marketplace
*Already worked with Bryte Systems? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.