AWS Architecture Blog
How Financial Institutions can use AWS to Address Regulatory Reporting
Since the 2008 financial crisis, banking supervisory institutions such as the Basel Committee on Banking Supervision (BCBS) have strengthened regulations. There is now increased oversight over the financial services industry. For banks, making the necessary changes to comply with these rules is a challenging, multi-year effort.
Basel IV, a massive update to existing rules, is due for implementation in January 2023. Basel IV standardizes the approach to calculating credit risk, increases the impact of risk-weighted assets (RWAs) and emphasizes data transparency.
Given the complexity of data, modeling, and numerous assumptions that have to be made, compliance under Basel IV implementation will be challenging. Standardization omits nuances unique to your business, which can drive up costs, but violating guidelines will result in steep penalties.
This post will address these challenges by outlining a mechanism that facilitates a healthy, data-driven dialogue between banks and regulators to better meet regulatory reporting requirements. The reference architecture will focus on enabling fast, iterative releases with the help of serverless AWS services.
There are four key actions to take in order to support this mechanism:
- Automate data management
- Establish a continuous integration/continuous delivery (CI/CD) pipeline
- Enable fast, point-in-time audit replays
- Set up proactive monitoring and notifications
Automate data management
Due to frequent merger activity, banks are typically comprised of a web of integrated systems and siloed business units, making it difficult to consolidate data. Under Basel IV guidelines, auditors want banks to provide detailed data in a presentable way.
You can tackle this first challenge by establishing a data pipeline as shown in Figure 1. Take inventory of each data source as it is incorporated into the pipeline. Identify the critical internal and external data sources that will be used to populate the initial landing area. Amazon Simple Storage Service (S3) is a great choice for this.

Figure 1. Data pipeline that cleans, processes, and segments data
Amazon S3 is a highly available, durable service that is a popular data lake solution. S3 offers WORM storage capabilities like S3 Glacier Vault and S3 Object Lock to protect the integrity of your archived data in accordance with U.S. SEC and FINRA rules.
Basel IV regulations also require banks to use many attributes to develop accurate credit risk models. The attributes can be a mix of datasets such as financial statements, internal balanced scorecards, macro-economic data, and credit ratings. The risk models themselves can also be segmented by portfolio types, industry segments, asset types and much more.
You can split data into different domains and designate data owners with separate S3 buckets. Credit risk model developers, analyst, and data scientists can then use the structure of the S3 buckets to pull together relevant datasets. They can then store the outputs into S3 buckets.
To support fast, automated data retrieval, store object metadata in a highly scalable, and queryable database. You can set up Amazon S3 so that an event can initiate a function to populate Amazon DynamoDB. Developers can use AWS Lambda to write these functions using popular languages like Python.
With AWS Glue, you can automate Extract/Load/Transform (ETL) processes to clean and move data to the different S3 buckets. AWS Glue can also support data operations by automatically cataloging your various data sources.
Taking on a structured approach will simplify data governance and transparency as the business continues to grow and operate.
Establish a CI/CD pipeline
Adopt tools that machine learning teams can use to build a streamlined CI/CD solution as demonstrated in Figure 2.

Figure 2. An end-to-end machine learning development and deployment pipeline
Using tightly integrated AWS services, your teams can minimize time spent managing tools and deployment processes, and instead, focus on tuning the models and analyzing the results.
Amazon SageMaker brings together a powerful set of machine learning capabilities on the AWS Cloud. It helps data scientists and engineers build insightful models. Figure 2 depicts the high-level architecture and shows how Amazon SageMaker Pipelines helps teams orchestrate the automation and deployment processes.
The core of the pipeline uses a set of AWS deployment services so that your teams can collaborate and review effectively. With AWS CodeCommit, your teams can set up git-based repository to store and version models for data processing, training, and evaluation. The repository can also store code and configuration files using AWS CloudFormation for deployment. You can use AWS CodePipeline and AWS CodeBuild to create and update a model endpoint based on the approved/reviewed changes.
Any updates detected in the AWS CodeCommit repository initiate a deployment whenever a new model version is added to the Model Registry. Amazon S3 can be used to store generated model artifacts, historical data, and models.
Enable fast, point-in-time audit replays
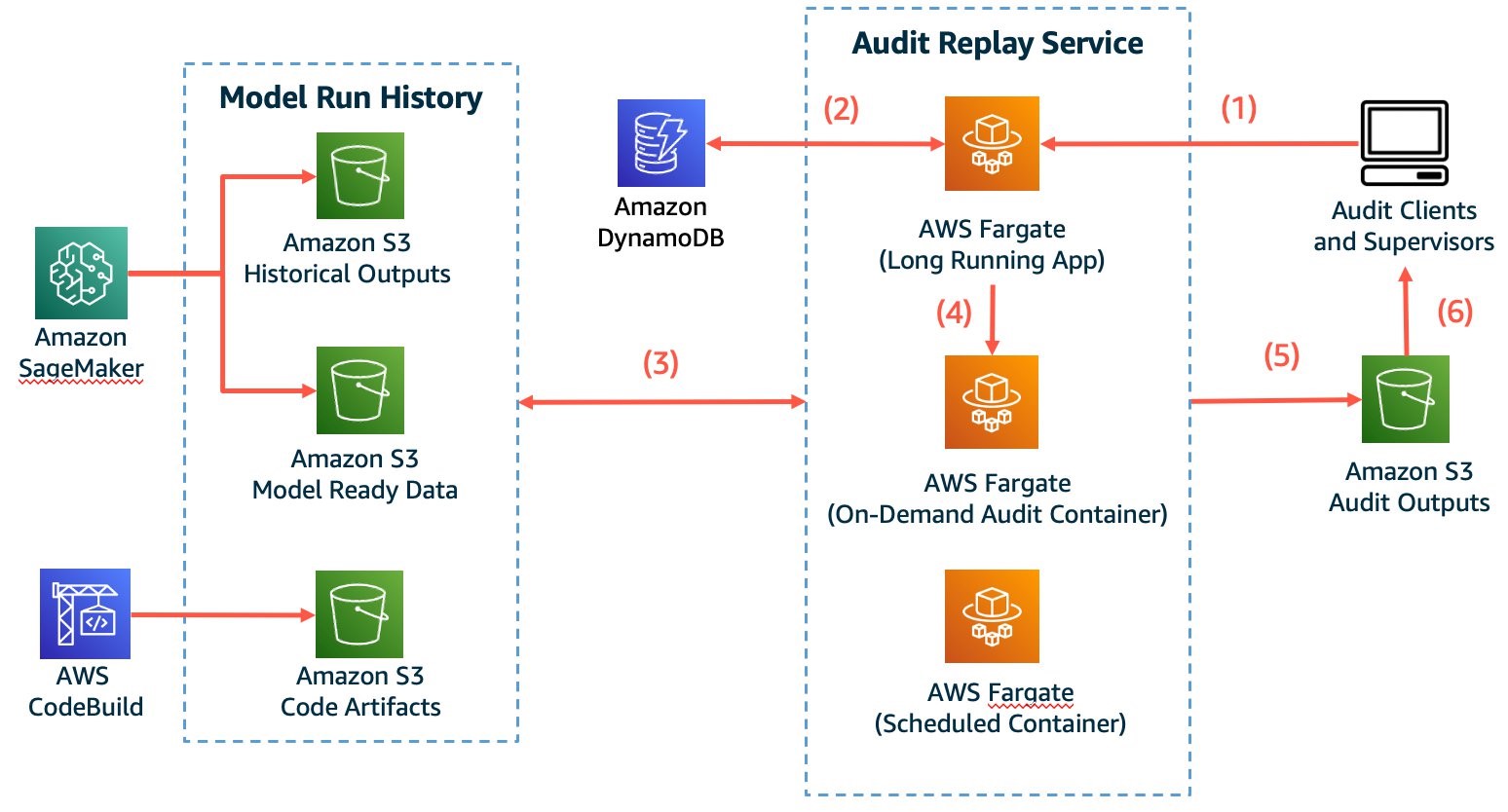
Figure 3. Containers offer a lightweight, powerful solution to run audits using historical assets
One of the main themes of Basel IV is transparency. Figure 3 illustrates a solution to build trust with regulators by allowing them to verify and understand modeling activity.
A lightweight application is hosted in AWS Fargate and enables auditors to re-run Basel credit risk models under specified conditions. With AWS Fargate, you don’t need to manually manage instances or container orchestration. Configure the CPU or memory specifications at the task level and set guidelines around scalability for your service. Your tasks then scale up and down automatically, based on demand, and will optimize cost efficiency and availability.
Figure 3 shows the following:
- The application takes inputs such as date, release version, and model type.
- It then queries DynamoDB with this information.
- The query will return the data necessary to retrieve model artifacts from previous CI/CD deployments and relevant datasets from historical S3 buckets.
- Using this information, it can spin up as many containers as needed to run the model.
- It then stores the outputs in a separate S3 bucket.
- Auditors will have a detailed trace of all the attributes, assumptions, and data that went into the modeling effort. To streamline this process, the app can also compare the outputs of the historical runs to the recent replay and highlight any significant deviations.
Though internal models will be de-emphasized under Basel IV, banks will continue to run internal models as a benchmark against the broader standards. Schedule AWS Fargate tasks to run these models regularly to capitalize on highly performant compute services while minimizing costs.
Set up proactive monitoring and notifications
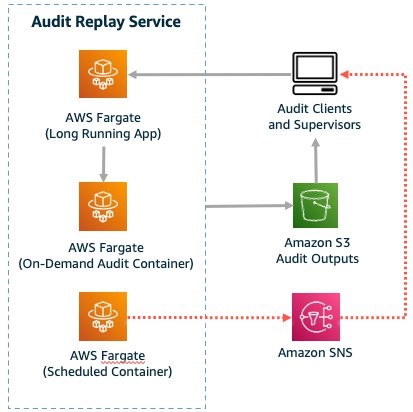
Figure 4. Scheduled jobs can send out notifications using Amazon SNS when certain thresholds are breached
The last principle is based around establishing an early warning system, enabling financial institutions to proactively stay within acceptable thresholds.
With automated monitoring and notifications, banks will be able to respond quickly to potential concerns. For instance, there can be a daily scheduled job that launches containers and runs the models against the latest data. If any thresholds are breached, alerts can be sent out via SMS or email. Operational teams can be subscribed to certain message topics using Amazon Simple Notification Service (SNS). They can then respond before actual compliance issues emerge.
Conclusion
With a Well-Architected approach, AWS helps you control your data, deploy new features, and embrace a serverless approach. This frees you to innovate quickly and address regulatory challenges.
You can iterate with new AWS services and bring machine learning to bear on various streams of data to identify high impact pools of value. You can get a clearer picture of the data to make it easier to identify areas where you can reduce RWAs. Using Amazon S3, you can turn on AWS analytics services such as Amazon QuickSight and Amazon Athena to visualize the data. This will help address some of the reporting requirements found in regulatory studies like CCAR, DFAST, CECL, and IFRS9.
For more information about establishing a data pipeline, read Lake House Formation Architecture. It is a powerful pattern that combines a few concepts that will help bring your data together cohesively. To set up a robust CI/CD pipeline, explore the AWS Serverless CI/CD Reference Architecture.