AWS Big Data Blog

Author: Avijit Goswami
Avijit Goswami is a Principal Specialist Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. When not at work, Avijit likes to travel, hike, watch sports, listen to music, and experiment with cooking.

Reduce time to access your transactional data for analytical processing using the power of Amazon SageMaker Lakehouse and zero-ETL
In this post, we demonstrate how you can bring transactional data from AWS OLTP data stores like Amazon Relational Database Service (Amazon RDS) and Amazon Aurora flowing into Redshift using zero-ETL integrations to SageMaker Lakehouse Federated Catalog (Bring your own Amazon Redshift into SageMaker Lakehouse). With this integration, you can now seamlessly onboard the changed data from OLTP systems to a unified lakehouse and expose the same to analytical applications for consumptions using Apache Iceberg APIs from new SageMaker Unified Studio.

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.

Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational […]

Build a high-performance, transactional data lake using open-source Delta Lake on Amazon EMR
Data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for all enterprise data and serve as a common choice for a large number of users querying from a variety of analytics and machine learning (ML) tools. Oftentimes you want to ingest data continuously into the data lake from multiple sources […]
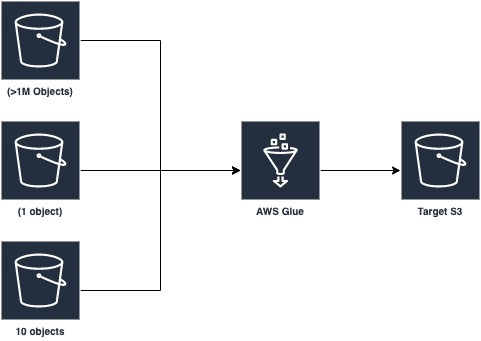
Optimizing Spark applications with workload partitioning in AWS Glue
AWS Glue provides a serverless environment to prepare (extract and transform) and load large amounts of datasets from a variety of sources for analytics and data processing with Apache Spark ETL jobs. This posts discusses a new AWS Glue Spark runtime optimization that helps developers of Apache Spark applications and ETL jobs, big data architects, […]

Enforce column-level authorization with Amazon QuickSight and AWS Lake Formation
Amazon QuickSight is a fast, cloud-powered, business intelligence service that makes it easy to deliver insights and integrates seamlessly with your data lake built on Amazon Simple Storage Service (Amazon S3). QuickSight users in your organization often need access to only a subset of columns for compliance and security reasons. Without having a proper solution […]