AWS Big Data Blog
Build a high-performance, transactional data lake using open-source Delta Lake on Amazon EMR
Data lakes on Amazon Simple Storage Service (Amazon S3) have become the default repository for all enterprise data and serve as a common choice for a large number of users querying from a variety of analytics and machine learning (ML) tools. Oftentimes you want to ingest data continuously into the data lake from multiple sources and query against the data lake from many analytics tools concurrently with transactional capabilities. Features like supporting ACID transactions, schema enforcement, and time travel on an S3 data lake have become an increasingly popular requirement in order to build a high-performance transactional data lake running analytics queries that return consistent and up-to-date results. AWS is designed to provide multiple options for you to implement transactional capabilities on your S3 data lake, including Apache Hudi, Apache Iceberg, AWS Lake Formation governed tables, and open-source Delta Lake.
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and ML applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto.
Delta Lake is an open-source project that helps implement modern data lake architectures commonly built on Amazon S3 or HDFS. Delta Lake offers the following functionalities:
- Ensures ACID transactions (atomic, consistent, isolated, durable) on Spark so that readers continue to see a consistent view of the table during a Spark job
- Scalable metadata handling using Spark’s distributed processing
- Combining streaming and batch uses cases using the same Delta table
- Automatic schema enforcements to avoid bad records during data ingestion
- Time travel using data versioning
- Support for merge, update and delete operations to enable complex use cases like change data capture (CDC), slowly changing dimension (SCD) operations, streaming upserts, and more
In this post, we show how you can run open-source Delta Lake (version 2.0.0) on Amazon EMR. For demonstration purposes, we use Amazon EMR Studio notebooks to walk through its transactional capabilities:
- Read
- Update
- Delete
- Time travel
- Upsert
- Schema evolution
- Optimizations with file management
- Z-ordering (multi-dimensional clustering)
- Data skipping
- Multipart checkpointing
Transactional data lake solutions on AWS
Amazon S3 is the largest and most performant object storage service for structured and unstructured data and the storage service of choice to build a data lake. With Amazon S3, you can cost-effectively build and scale a data lake of any size in a secure environment where data is protected by 99.999999999% (11 9s) of durability.
Traditionally, customers have used Hive or Presto as a SQL engine on top of an S3 data lake to query the data. However, neither SQL engine comes with ACID compliance inherently, which is needed to build a transactional data lake. A transactional data lake requires properties like ACID transactions, concurrency controls, schema evolution, time travel, and concurrent upserts and inserts to build a variety of use cases processing petabyte-scale data. Amazon EMR is designed to provide multiple options to build a transactional data lake:
- Apache Hudi – Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development. Starting with release version 5.28, Amazon EMR installs Hudi components by default when Spark, Hive, or Presto are installed. Since then, several new capabilities and bug fixes have been added to Apache Hudi and incorporated into Amazon EMR. Amazon EMR 6.7.0 contains Hudi version 0.11.0. For the version of components installed with Hudi in different Amazon EMR releases, see the Amazon EMR Release Guide.
- Apache Iceberg – Apache Iceberg is an open table format for huge analytic datasets. Table formats typically indicate the format and location of individual table files. Iceberg adds functionality on top of that to help manage petabyte-scale datasets as well as newer data lake requirements such as transactions, upsert or merge, time travel, and schema and partition evolution. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Starting with Amazon EMR release 6.5.0 (Amazon EMR version 6.7.0 supports Iceberg 0.13.1), you can reliably work with huge tables with full support for ACID transactions in a highly concurrent and performant manner without getting locked into a single file format.
- Open-source Delta Lake – You can also build your transactional data lake by launching Delta Lake from Amazon EMR using Amazon EMR Serverless, Amazon EMR on EKS, or Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) by adding Delta JAR packages to the Spark classpath to run interactive and batch workloads.
- Lake Formation governed tables – We announced the general availability of Lake Formation transactions, row-level security, and acceleration at AWS re:Invent 2021. These capabilities are available via new update and access APIs that extend the governance capabilities of Lake Formation with row-level security, and provide transactions over data lakes. For more information, refer to Effective data lakes using AWS Lake Formation, Part 3: Using ACID transactions on governed tables.
Although all these options have their own merits, this post focuses on Delta Lake to provide more flexibility to our customers to build your transactional data lake platform using your tool of choice. Delta Lake provides many capabilities, including snapshot isolation and efficient DML and rollback. It provides improved performance through features like Z-order partitioning and file optimizations through compaction.
Solution overview
Navigate through the steps provided in this post to implement Delta Lake on Amazon EMR. You can access the sample notebook from the GitHub repo. You can also find this notebook in your EMR Studio workspace under Notebook Examples.
Prerequisites
To walk through this post, we use Delta Lake version 2.0.0, which is supported in Apache Spark 3.2.x. Choose the Delta Lake version compatible with your Spark version by visiting the Delta Lake releases page. We create an EMR cluster using the AWS Command Line Interface (AWS CLI). We use Amazon EMR 6.7.0, which supports Spark version 3.2.1.
Set up Amazon EMR and Delta Lake
We use the bootstrap action to install Delta Lake on the EMR cluster. Create the following script and store it into your S3 bucket (for example, s3://<your bucket>/bootstrap/deltajarinstall.sh) to be used for bootstrap action:
Use the following AWS CLI command to create an EMR cluster with the following applications installed: Hadoop, Spark, Livy, and Jupyter Enterprise Gateway. You can also use the Amazon EMR console to create an EMR cluster with the bootstrap action. Replace <your subnet> with one of the subnets in which your EMR Studio is running. In this example, we use a public subnet because we need internet connectivity to download the required JAR files for the bootstrap action. If you use a private subnet, you may need to configure network address translation (NAT) and VPN gateways to access services or resources located outside of the VPC. Update <your-bucket> with your S3 bucket.
Set up Amazon EMR Studio
We use EMR Studio to launch our notebook environment to test Delta Lake PySpark codes on our EMR cluster. EMR Studio is an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. For setup instructions, refer to Set up an Amazon EMR Studio. Alternatively, you can also set up EMR Notebooks instead of EMR Studio.
- To set up Apache Spark with Delta Lake, use the following configuration in the PySpark notebook cell:
- Import the packages needed for this example:
- Set up a table location environment variable deltaPath:
- Create Delta tables.
Now you can start running some Spark tests on files converted to Delta format. To do that, we read a public dataset (Amazon Product Reviews Dataset) and write the data in Delta Lake format to the S3 bucket that we created in the previous step. - Read the Amazon Product Reviews Parquet file in the DataFrame (we’re loading one partition for the sake of simplicity):
- Check the DataFrame schema:

- Convert the Parquet file and write the data to Amazon S3 in Delta table format:
Check the Amazon S3 location that you specified in
deltaPathfor new objects created in the bucket. Notice the_delta_logfolder that got created in the S3 bucket. This is the metadata directory for the transaction log of a Delta table. This directory contains transaction logs or change logs of all the changes to the state of a Delta table.
- You can also set the table location in Spark config, which allows you to read the data using SQL format:
Query Delta tables with DML operations
Now that we have successfully written data in Amazon S3 in Delta Lake 2.0.0 table format, let’s query the Delta Lake and explore Delta table features.
Read
We start with the following query:
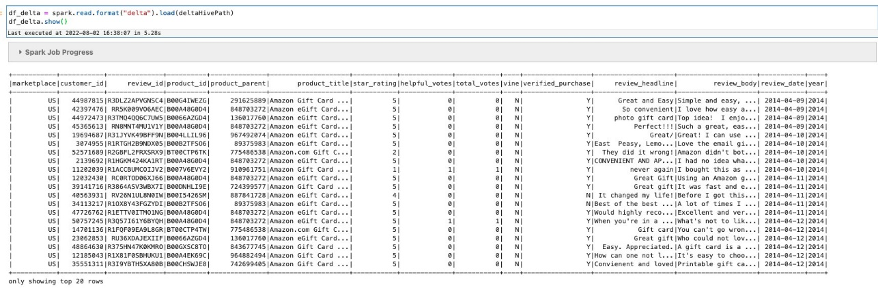
You can also use standard SQL statements, even though the table has not yet been created or registered within a data catalog (such as a Hive metastore or the AWS Glue Data Catalog). In this case, Delta allows the use of a special notation delta.TABLE_PATH to infer the table metadata directly from a specific location. For tables that are registered in a metastore, the LOCATION path parameter is optional. When you create a table with a LOCATION parameter, the table is considered unmanaged by the metastore. When you issue a DROP statement on a managed table without the path option, the corresponding data files are deleted, but for unmanaged tables, the DROP operation doesn’t delete the data files underneath.
Update
Firstly, run the following step to define the Delta table:
Now let’s update a column and observe how the Delta table reacts. We update the marketplace column and replace the value US with USA. There are different syntaxes available to perform the update.
You can use the following code:
Alternatively, use the following code:
The following is a third method:
Test if the update was successful:
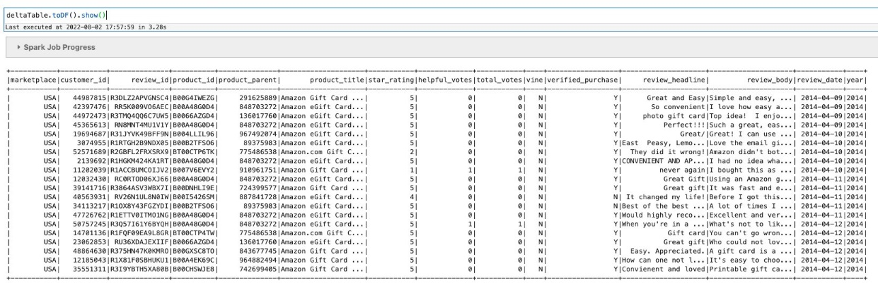
You can see that the marketplace value changed from US to USA.
Delete
GDPR and CCPA regulations mandate the timely removal of individual customer data and other records from datasets. Let’s delete a record from our Delta table.
Check the existence of records in the file with verified_purchase = 'N':
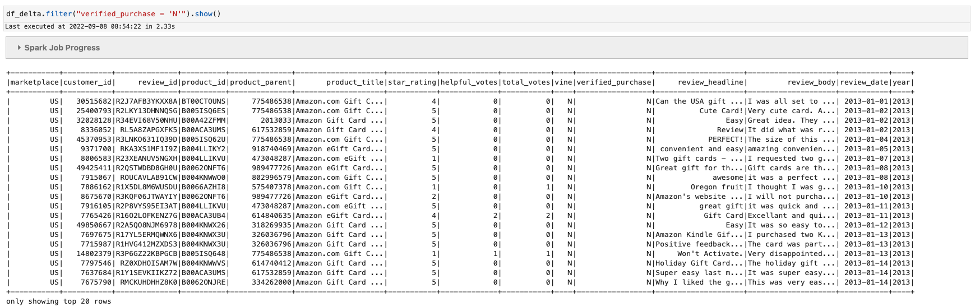
Then delete all records from the table for verified_purchase = 'N':
When you run the same command again to check the existence of records in the file with verified_purchase = 'N', no rows are available.

Note that the delete method removes the data only from the latest version of a table. These records are still present in older snapshots of the data.
To view the previous table snapshots for the deleted records, run the following command:
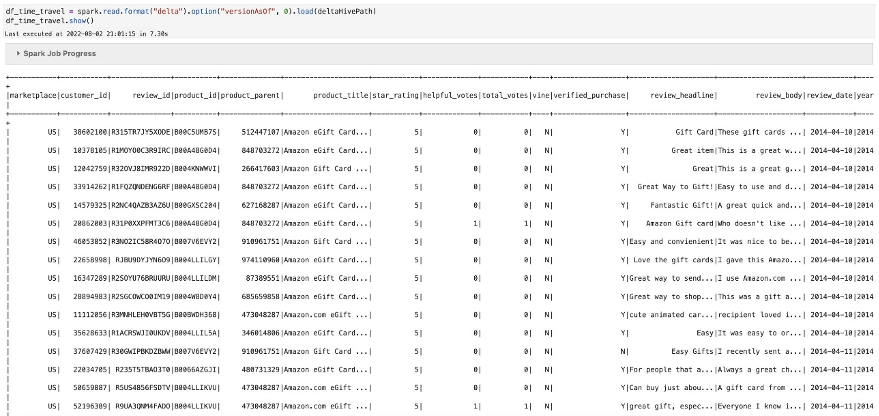
Time travel
To view the Delta table history, run the following command. This command retrieves information on the version, timestamp, operation, and operation parameters for each write to a Delta table.
You can see the history in the output, with the most recent update to the table appearing at the top. You can find the number of versions of this table by checking the version column.
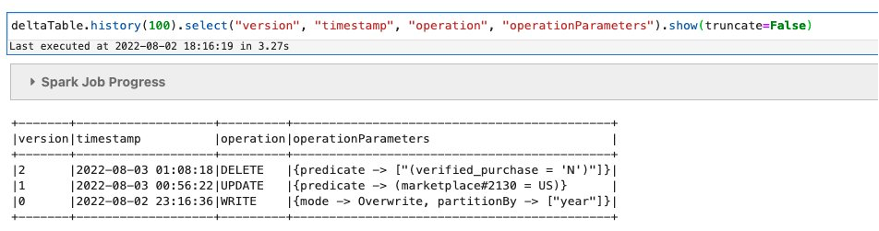
In the previous example, you checked the number of versions available for this table. Now let’s check the oldest version of the table (version 0) to see the previous marketplace value (US) before the update and the records that have been deleted:
marketplace is showing as US, and you can also see the verified_purchase = ‘N’ records.
To erase data history from the physical storage, you need to explicitly vacuum older versions.
Upsert
You can upsert data from an Apache Spark DataFrame into a Delta table using the merge operation. This operation is similar to the SQL MERGE command but has additional support for deletes and extra conditions in updates, inserts, and deletes. For more information, refer to Upsert into a table using merge.
Create some records to prepare for the upsert operation we perform in a later stage. We create a dataset that we use to update the record in the main table for "review_id":'R315TR7JY5XODE' and add a new record for "review_id":'R315TR7JY5XOA1':
Create a Spark DataFrame for data_upsert:
Now let’s perform the upsert with the Delta Lake merge operation. In this example, we update the record in the main table for "review_id":'R315TR7JY5XODE' and add a new record for "review_id":'R315TR7JY5XOA1' using the data_upsert DataFrame we created:
(deltaTable
.alias('t')
.merge(df_data_upsert.alias('u'), 't.review_id = u.review_id')
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute())
Query the merged table:

Now compare the previous output with the oldest version of the table by using the time travel DataFrame:

Notice that for "review_id":'R315TR7JY5XODE', many column values like product_id, product_parent, helpful_votes, review_headline, and review_body got updated.
Schema evolution
By default, updateAll and insertAll assign all the columns in the target Delta table with columns of the same name from the source dataset. Any columns in the source dataset that don’t match columns in the target table are ignored.
However, in some use cases, it’s desirable to automatically add source columns to the target Delta table. To automatically update the table schema during a merge operation with updateAll and insertAll (at least one of them), you can set the Spark session configuration spark.databricks.delta.schema.autoMerge.enabled to true before running the merge operation.
Schema evolution occurs only when there is either an updateAll (UPDATE SET *) or an insertAll (INSERT *) action, or both.
Optimization with file management
Delta Lake provides multiple optimization options to accelerate the performance of your data lake operations. In this post, we show how you can implement Delta Lake optimization with file management.
With Delta Lake, you can optimize the layout of data storage to improve query performance. You can use the following command to optimize the storage layout of the whole table:
To reduce the scope of optimization for very large tables, you can include a where clause condition:
Z-ordering
Delta Lake uses Z-ordering to reduce the amount of data scanned by Spark jobs. To perform the Z-order of data, you specify the columns to order in the ZORDER BY clause. In the following example, we’re Z-ordering the table based on a low cardinality column verified_purchase:
Data skipping
Delta Lake automatically collects data skipping information during the Delta Lake write operations. Delta Lake refers to the minimum and maximum values for each column at runtime to accelerate the query performance. This feature is automatically activated and there is no need to make any changes in the application.
Multipart checkpointing
Delta Lake automatically compacts all the incremental updates to the Delta logs into a Parquet file. This checkpointing allows faster reconstruction of the current state. With the SQL configuration spark.databricks.delta.checkpoint.partSize=<n>, (where n is the limit of number of actions, such as AddFile), Delta Lake can parallelize the checkpoint operation and write each checkpoint in a single Parquet file.
Clean up
To avoid ongoing charges, delete the S3 buckets and EMR Studio, and stop the EMR cluster used for experimentation of this post.
Conclusion
In this post, we discussed how to configure open-source Delta Lake with Amazon EMR, which helps you create a transactional data lake platform to support multiple analytical use cases. We demonstrated how you can use different kinds of DML operations on a Delta table. Check out the sample Jupyter notebook used in the walkthrough. We also shared some new features offered by Delta Lake, such as file compaction and Z-ordering. You can implement these new features to optimize the performance of the large-scale data scan on a data lake environment. Because Amazon EMR supports two ACID file formats (Apache Hudi and Apache Iceberg) out of the box, you can easily build a transactional data lake to enhance your analytics capabilities. With the flexibility provided by Amazon EMR, you can install the open-source Delta Lake framework on Amazon EMR in order to support a wider range of transactional data lake needs based on various use cases.
Now, you can use the latest open-source version of Delta Lake using the bootstrap actions shown in this post to run on Amazon EMR to build your transactional data lake.
About the Authors
 Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
 Ajit Tandale is a Big Data Solutions Architect at Amazon Web Services. He helps AWS strategic customers accelerate their business outcomes by providing expertise in big data using AWS managed services and open-source solutions. Outside of work, he enjoys reading, biking, and watching sci-fi movies.
Ajit Tandale is a Big Data Solutions Architect at Amazon Web Services. He helps AWS strategic customers accelerate their business outcomes by providing expertise in big data using AWS managed services and open-source solutions. Outside of work, he enjoys reading, biking, and watching sci-fi movies.
 Thippana Vamsi Kalyan is a Software Development Engineer at AWS. He is passionate about learning and building highly scalable and reliable data analytics services and solutions on AWS. In his free time, he enjoys reading, being outdoors with his wife and kid, walking, and watching sports and movies.
Thippana Vamsi Kalyan is a Software Development Engineer at AWS. He is passionate about learning and building highly scalable and reliable data analytics services and solutions on AWS. In his free time, he enjoys reading, being outdoors with his wife and kid, walking, and watching sports and movies.