AWS Big Data Blog
Category: Amazon Athena

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.
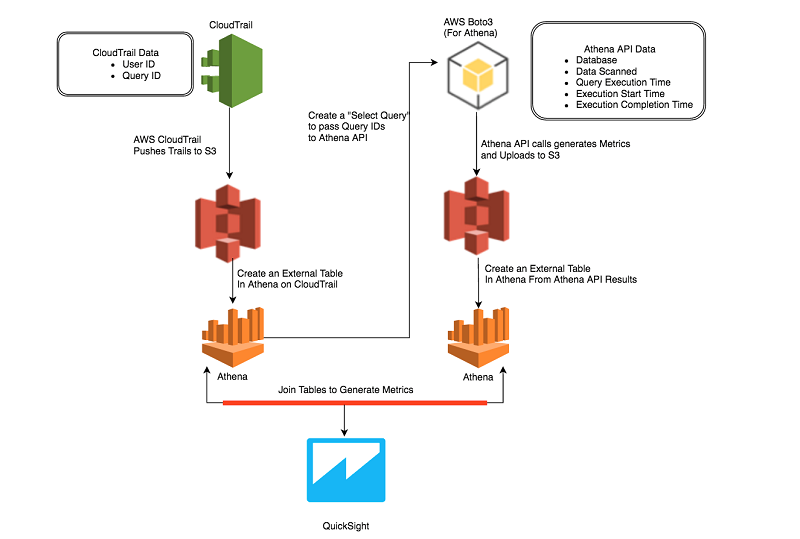
How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight
In this post, I discuss how to build a solution for monitoring Athena usage. To build this solution, you rely on AWS CloudTrail. CloudTrail is a web service that records AWS API calls for your AWS account and delivers log files to an S3 bucket.

Genomic Analysis with Hail on Amazon EMR and Amazon Athena
For this task, we use Hail, an open source framework for exploring and analyzing genomic data that uses the Apache Spark framework. In this post, we use Amazon EMR to run Hail. We walk through the setup, configuration, and data processing. Finally, we generate an Apache Parquet–formatted variant dataset and explore it using Amazon Athena.

Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production
This is a guest post by Rafi Ton, founder and CEO of NUVIAD. The ability to provide fresh, up-to-the-minute data to our customers and partners was always a main goal with our platform. We saw other solutions provide data that was a few hours old, but this was not good enough for us. We insisted on providing the freshest data possible. For us, that meant loading Amazon Redshift in frequent micro batches and allowing our customers to query Amazon Redshift directly to get results in near real time. The benefits were immediately evident. Our customers could see how their campaigns performed faster than with other solutions, and react sooner to the ever-changing media supply pricing and availability. They were very happy.

Visualize AWS Cloudtrail Logs Using AWS Glue and Amazon QuickSight
In this post, I walk through using AWS Glue and AWS Lambda to convert AWS CloudTrail logs from JSON to a query-optimized format dataset in Amazon S3. I then use Amazon Athena and Amazon QuickSight to query and visualize the data.

Build a Data Lake Foundation with AWS Glue and Amazon S3
A data lake is an increasingly popular way to store and analyze data that addresses the challenges of dealing with massive volumes of heterogeneous data. A data lake allows organizations to store all their data—structured and unstructured—in one centralized repository. Because data can be stored as-is, there is no need to convert it to a predefined schema. This post walks you through the process of using AWS Glue to crawl your data on Amazon S3 and build a metadata store that can be used with other AWS offerings.

Predict Billboard Top 10 Hits Using RStudio, H2O and Amazon Athena
In this walkthrough, you leverage H2O.ai, Amazon Athena, and RStudio to make predictions on whether a song might make it to the Top 10 Billboard charts. You explore the GLM, GBM, and deep learning modeling techniques using H2O’s rapid, distributed and easy-to-use open source parallel processing engine.

Build a Schema-On-Read Analytics Pipeline Using Amazon Athena
In this post, I show how to build a schema-on-read analytical pipeline, similar to the one used with relational databases, using Amazon Athena. The approach is completely serverless, which allows the analytical platform to scale as more data is stored and processed via the pipeline.
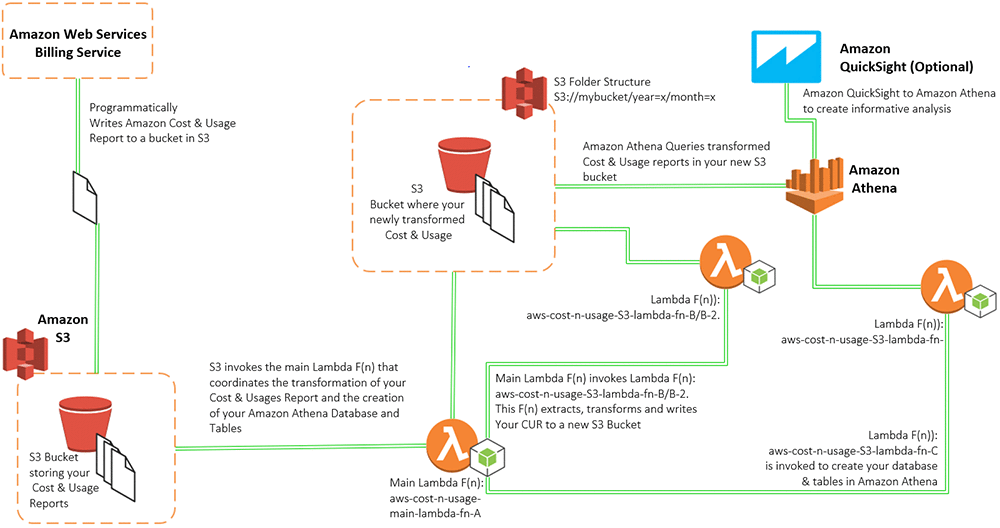
Query and Visualize AWS Cost and Usage Data Using Amazon Athena and Amazon QuickSight
If you’ve ever wondered if a serverless alternative existed for consuming and querying your AWS Cost and Usage report data, then wonder no more. The answer is yes, and this post both introduces you to that solution and illustrates the simplicity and effortlessness of deploying it.

Unite Real-Time and Batch Analytics Using the Big Data Lambda Architecture, Without Servers!
In this post, I show you how you can use AWS services like AWS Glue to build a Lambda Architecture completely without servers. I use a practical demonstration to examine the tight integration between serverless services on AWS and create a robust data processing Lambda Architecture system.