AWS Big Data Blog
Category: Amazon EMR

Improve reliability and reduce costs of your Apache Spark workloads with vertical autoscaling on Amazon EMR on EKS
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. Apache Spark allows […]

Build, deploy, and run Spark jobs on Amazon EMR with the open-source EMR CLI tool
Today, we’re pleased to introduce the Amazon EMR CLI, a new command line tool to package and deploy PySpark projects across different Amazon EMR environments. With the introduction of the EMR CLI, you now have a simple way to not only deploy a wide range of PySpark projects to remote EMR environments, but also integrate […]

Accelerate HiveQL with Oozie to Spark SQL migration on Amazon EMR
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by […]

How CyberSolutions built a scalable data pipeline using Amazon EMR Serverless and the AWS Data Lab
This post is co-written by Constantin Scoarță and Horațiu Măiereanu from CyberSolutions Tech. CyberSolutions is one of the leading ecommerce enablers in Germany. We design, implement, maintain, and optimize award-winning ecommerce platforms end to end. Our solutions are based on best-in-class software like SAP Hybris and Adobe Experience Manager, and complemented by unique services that […]

Amazon EMR on EKS widens the performance gap: Run Apache Spark workloads 5.37 times faster and at 4.3 times lower cost
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

Push Amazon EMR step logs from Amazon EC2 instances to Amazon CloudWatch logs
Amazon EMR is a big data service offered by AWS to run Apache Spark and other open-source applications on AWS to build scalable data pipelines in a cost-effective manner. Monitoring the logs generated from the jobs deployed on EMR clusters is essential to help detect critical issues in real time and identify root causes quickly. […]

Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. […]
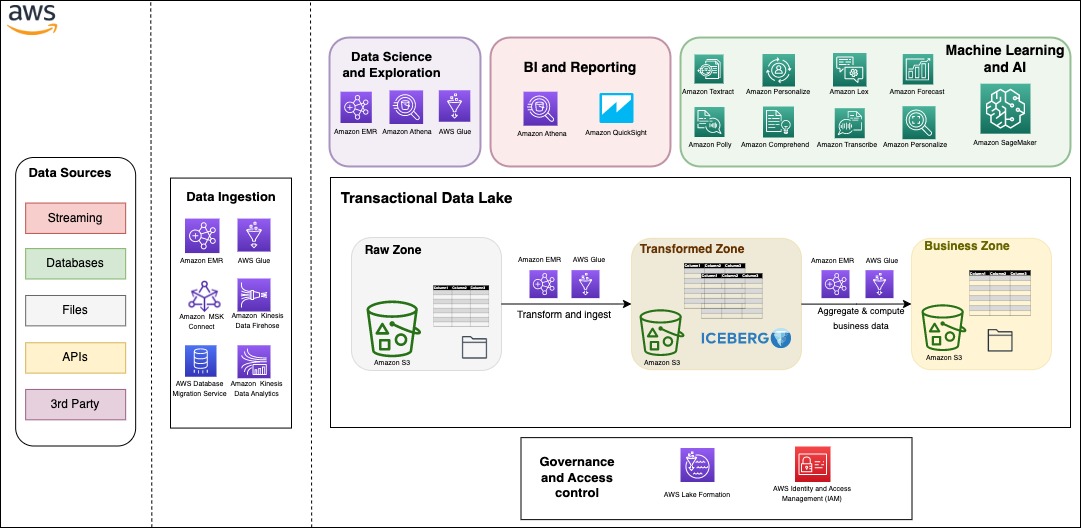
Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Data lakes have served as a central repository to store structured and unstructured data at any scale and in various formats. However, as data processing at scale solutions grow, organizations need […]

Build incremental data pipelines to load transactional data changes using AWS DMS, Delta 2.0, and Amazon EMR Serverless
Building data lakes from continuously changing transactional data of databases and keeping data lakes up to date is a complex task and can be an operational challenge. A solution to this problem is to use AWS Database Migration Service (AWS DMS) for migrating historical and real-time transactional data into the data lake. You can then […]

Use Apache Iceberg in a data lake to support incremental data processing
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. It adds tables to compute engines including Spark, Trino, PrestoDB, Flink, and Hive using a high-performance table format that works just like a SQL table. Iceberg has […]