AWS Big Data Blog
Category: Amazon EMR
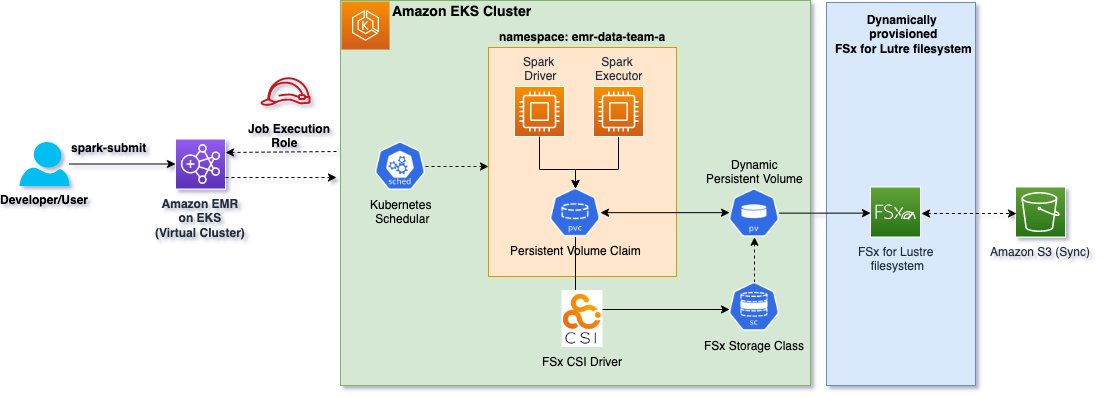
Run Apache Spark with Amazon EMR on EKS backed by Amazon FSx for Lustre storage
September 2023: This post was reviewed and updated for accuracy to reflect recent improvements and changes. Traditionally, Spark workloads have been run on a dedicated setup like a Hadoop stack with YARN or MESOS as a resource manager. Starting from Apache Spark 2.3, Spark added support for Kubernetes as a resource manager. The new Kubernetes […]

Implement a highly available key distribution center for Amazon EMR
High availability (HA) is the property of a system or service to operate continuously without failing for a designated period of time. Implementing HA properties over a system allows you to eliminate single points of failure that usually translate to service disruptions, which can then lead to a business loss or the inability to use […]

Store Amazon EMR in-transit data encryption certificates using AWS Secrets Manager
With Amazon EMR, you can use a security configuration to specify settings for encrypting data in transit. When in-transit encryption is configured, you can enable application-specific encryption features, for example: Hadoop HDFS NameNode or DataNode user interfaces use HTTPS Hadoop MapReduce encrypted shuffle uses Transport Layer Security (TLS) Presto nodes internal communication uses SSL/TLS (Amazon […]

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

Removing complexity to improve business performance: How Bridgewater Associates built a scalable, secure, Spark-based research service on AWS
This is a guest post co-written by Sergei Dubinin, Oleksandr Ierenkov, Illia Popov and Joel Thompson, from Bridgewater. Bridgewater’s core mission is to understand how the world works by analyzing the drivers of markets and turning that understanding into high-quality portfolios and investment advice for our clients. Within Bridgewater Technology, we strive to make our […]

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]

Configure Hadoop YARN CapacityScheduler on Amazon EMR on Amazon EC2 for multi-tenant heterogeneous workloads
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster resource manager responsible for assigning computational resources (CPU, memory, I/O), and scheduling and monitoring jobs submitted to a Hadoop cluster. This generic framework allows for effective management of cluster resources for distributed data processing frameworks, such as Apache Spark, Apache MapReduce, and Apache Hive. When […]
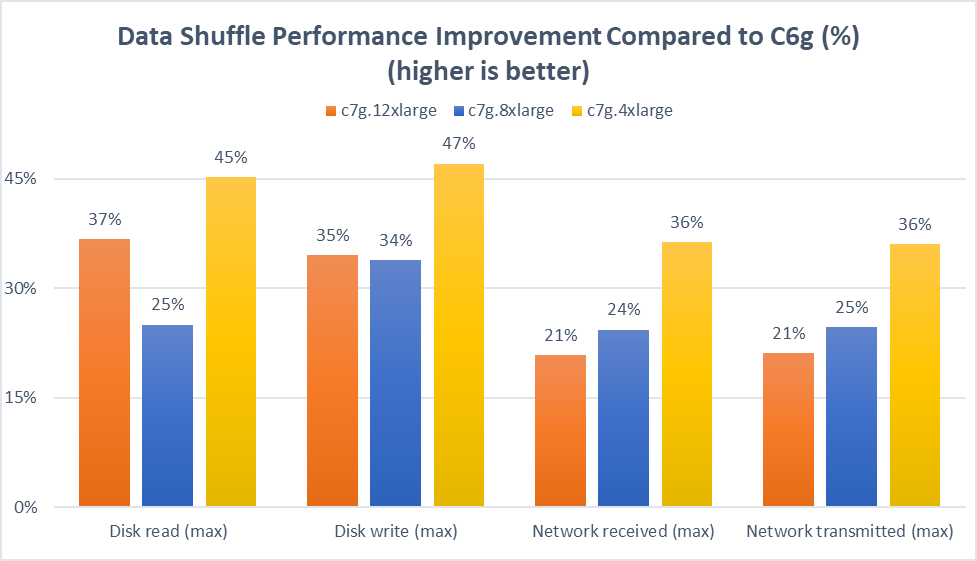
Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2
Amazon EMR on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as […]
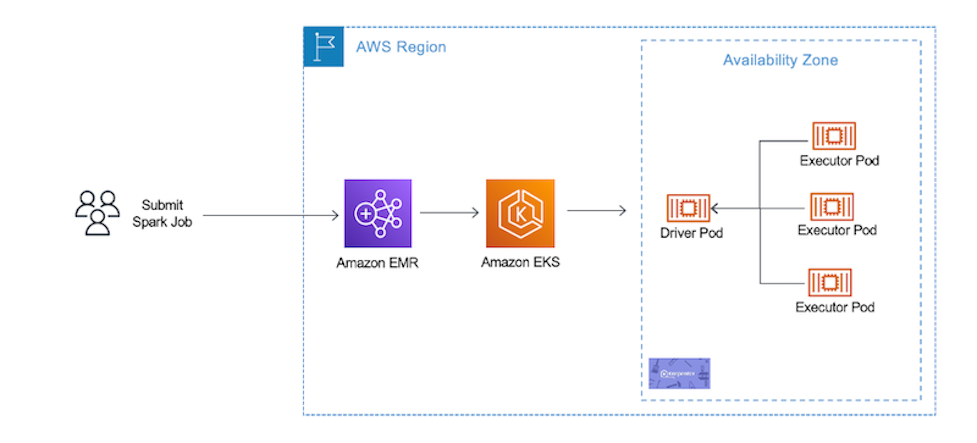
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]