AWS Big Data Blog
Category: Amazon EMR

Enable federated governance using Trino and Apache Ranger on Amazon EMR
Managing data through a central data platform simplifies staffing and training challenges and reduces the costs. However, it can create scaling, ownership, and accountability challenges, because central teams may not understand the specific needs of a data domain, whether it’s because of data types and storage, security, data catalog requirements, or specific technologies needed for […]

Disaster recovery considerations with Amazon EMR on Amazon EC2 for Spark workloads
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR launches all nodes for a given cluster in the same Amazon Elastic Compute Cloud (Amazon EC2) Availability Zone […]

Build a high-performance, ACID compliant, evolving data lake using Apache Iceberg on Amazon EMR
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Apache Iceberg is an open table format for huge analytic datasets. Table formats typically indicate the format and location of […]

Build an Apache Iceberg data lake using Amazon Athena, Amazon EMR, and AWS Glue
March 2024: This post was reviewed and updated for accuracy. Most businesses store their critical data in a data lake, where you can bring data from various sources to a centralized storage. The data is processed by specialized big data compute engines, such as Amazon Athena for interactive queries, Amazon EMR for Apache Spark applications, […]
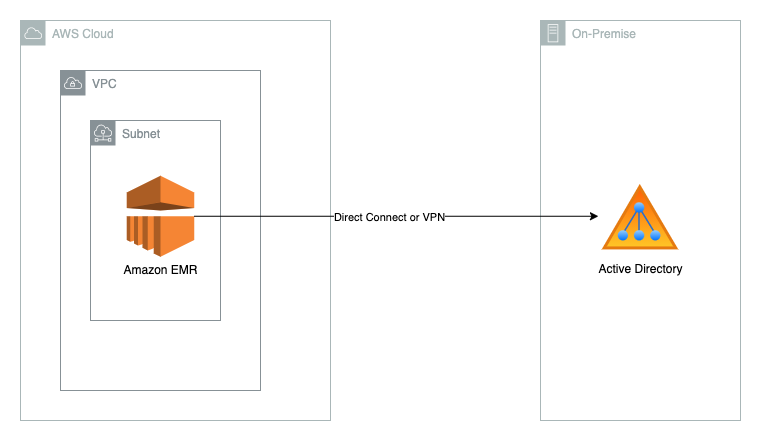
Deep dive into Amazon EMR Kerberos authentication integrated with Microsoft Active Directory
Many of our customers that use Amazon EMR as their big data platform need to integrate with their existing Microsoft Active Directory (AD) for user authentication. This integration requires the Kerberos daemon of Amazon EMR to establish a trusted connection with an AD domain, which involves a lot of moving pieces and can be difficult […]

How Paytm modernized their data pipeline using Amazon EMR
This post was co-written by Rajat Bhardwaj, Senior Technical Account Manager at AWS and Kunal Upadhyay, General Manager at Paytm. Paytm is India’s leading payment platform, pioneering the digital payment era in India with 130 million active users. Paytm operates multiple lines of business, including banking, digital payments, bill recharges, e-wallet, stocks, insurance, lending and […]

Access Apache Livy using a Network Load Balancer on a Kerberos-enabled Amazon EMR cluster
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR supports Kerberos for authentication; you can enable Kerberos on Amazon EMR and put the cluster in a private […]

Amazon EMR on Amazon EKS provides up to 61% lower costs and up to 68% performance improvement for Spark workloads
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. In our benchmark […]

How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint. SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, […]

Best practices to optimize data access performance from Amazon EMR and AWS Glue to Amazon S3
June 2024: This post was reviewed for accuracy and updated to cover Apache Iceberg. June 2023: This post was reviewed and updated for accuracy. Customers are increasingly building data lakes to store data at massive scale in the cloud. It’s common to use distributed computing engines, cloud-native databases, and data warehouses when you want to […]