AWS Big Data Blog
Best practices for running Apache Spark applications using Amazon EC2 Spot Instances with Amazon EMR
April 2024: This post was reviewed for accuracy.
Apache Spark has become one of the most popular tools for running analytics jobs. This popularity is due to its ease of use, fast performance, utilization of memory and disk, and built-in fault tolerance. These features strongly correlate with the concepts of cloud computing, where instances can be disposable and ephemeral.
Amazon EC2 Spot Instances offer spare compute capacity available in the AWS Cloud at steep discounts compared to On-Demand prices. EC2 can interrupt Spot Instances with two minutes of notification when EC2 needs the capacity back. You can use Spot Instances for various fault-tolerant and flexible applications. Some examples are analytics, containerized workloads, high-performance computing (HPC), stateless web servers, rendering, CI/CD, and other test and development workloads.
Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data using EC2 instances. When using Amazon EMR, you don’t need to worry about installing, upgrading, and maintaining Spark software (or any other tool from the Hadoop framework). You also don’t need to worry about installing and maintaining underlying hardware or operating systems. Instead, you can focus on your business applications and use Amazon EMR to remove the undifferentiated heavy lifting.
In this blog post, we are going to focus on cost-optimizing and efficiently running Spark applications on Amazon EMR by using Spot Instances. We recommend several best practices to increase the fault tolerance of your Spark applications and use Spot Instances. These work without compromising availability or having a large impact on performance or the length of your jobs.
Use the Spot Instance Advisor to target instance types with suitable interruption rates
As mentioned, Spot Instances can be interrupted if EC2 needs the capacity back. In this blog post, we share best practices on how to increase the fault tolerance of your Spark applications to withstand occasional loss of underlying EC2 instances due to Spot interruptions. However, even then, targeting EC2 Spot Instances with lower interruption rates can help further. This approach helps by decreasing occurrences where your job gets prolonged because Spark needs to redo some of the work when interruptions occur.
Use the Spot Instance Advisor to check the interruption rates and try to create your Amazon EMR cluster using instance types that historically have lower interruption rates. For example, the frequency of interruption for r4.2xlarge in the US East (Ohio) region at the time of writing this post is less than 5 percent. This means that less than 5 percent of all r4.2xlarge Spot Instances launched in the last 30 days were interrupted by EC2.
Run your Spot workloads on a diversified set of instance types
When running workloads (analytics or others) on EC2 instances and using On-Demand or Reserved Instances purchase options, you can generally use a single instance type across your entire cluster. You might do so after benchmarking to find the right instance type to fit the application’s requirement. However, with Spot Instances, using multiple Spot capacity pools (an instance type in an Availability Zone) in a cluster is key. This practice enables you to achieve scale and preserve capacity for running your jobs.
For example, suppose that I run my Spark application using On-Demand r4.xlarge instances (30.5 GiB memory and four vCPUs). When I start using Spot Instances, I can configure my Amazon EMR cluster’s Core or Task Instance Fleets with several instance types that have similar vCPUs to memory ratio (roughly 7 GB per vCPU) and let EMR choose the right instance type to run in the cluster. These include r4.2xlarge, r5.xlarge, i3.2xlarge, are i3.4xlarge. Taking this approach makes it more likely I’ll have sufficient Spot capacity to launch the cluster. It also increases the chance that Amazon EMR will be able to replenish the required capacity for the cluster to continue running (from other capacity pools) in case some of the capacity in the cluster is terminated by EC2 Spot Interruptions.
| Instance type | Number of vCPUs | RAM (in GB) |
| R4.xlarge | 4 | 30.5 |
| R4.2xlarge | 8 | 61 |
| R5.xlarge | 4 | 32 |
| I3.2xlarge | 8 | 61 |
| I3.4xlarge | 16 | 122 |
Size your Spark executors to allow using multiple instance types
As described just previously, a key factor for running on Spot instances is using a diversified fleet of instances. This also helps decrease the impact of Spot interruptions on your jobs. This approach dictates the architecture for your Spark applications.
Running with memory intensive executors (over 20 GB of RAM) ties your application to a specific set of instance types. These might not have sufficient Spot capacity for you to stand up your cluster. These also might have high Spot interruption rates, which might have an impact on your running jobs.
For example, for a Spark application with 90 GiB of RAM and 15 cores per executor, only 11 instance types fit the hardware requirements and fall below the 20 percent Spot interruption rate. Suppose that we break down the executors, keeping the ratio of 6 GiB of RAM per core, to two cores per executor. If we do so, we open up to 20 additional instance types that our job can run on (below the 20 percent interruption rate).
A fair approach to resizing an executor is to decide on the minimum number of cores to run your application on. Two is a good start. You then allocate memory using the following calculation:
NUM_CORES * ((EXECUTOR_MEMORY + MEMORY_OVERHEAD) / EXECUTOR_CORES)
In our example, that is 2 * (( 90 + 20 ) / 15) = 15GB
For more information about the memoryOverhead setting, see the Spark documentation.
Avoid large shuffles in Spark
To reduce the amount of data that Spark needs to reprocess if a Spot Instance is interrupted in your Amazon EMR cluster, you should avoid large shuffles.
Wide dependency operations like GroupBy and some types of joins can produce vast amounts of intermediate data. Intermediate data is stored on local disk and then transferred (shuffled) to other executors in your cluster.
Although you can’t always do so, we recommend to either avoid shuffle operations or work toward minimizing the amount of shuffle data. We recommend this for two reasons:
- This is a general Spark best practice, because shuffle is an expensive operation.
- In the context of Spot Instances, doing this decreases the fault tolerance of the job. This is because losing one node that either contains shuffle data or relies on shuffled data for computations (usually both) requires you to rerun some part of the shuffle process.
There are several patterns that we encounter that produce unnecessary amounts of shuffle data, described following.
The explode to group pattern
From a developer point of view, using explode on complex data types might be a quick solution to some use cases (exploding an array to multiple rows). We thus multiply the number of rows, and later in the job can join them back together.
For example, suppose that our data contains user IDs and an array of dates that describe visits to a website:
| A | B | |
| 1 | user_id | visit_dates_array |
| 2 | 0 | [ “28/01/2018”29/01/2018”, “01/01/2019”] |
| 3 | 100000 | [ “01/11/2017”, “01/12/2017”] |
| 4 | 999999 | [ “01/01/2017”, “02/01/2017”, “03/01/2017”, “04/01/2017”, “05/01/2017”, “06/01/2017”] |
Suppose that we run a Spark application that sums the number of visits of users in the website. In this case, an easy solution is to use explode and then aggregate the data, as shown following.
Explode the data:
Aggregate back the data:
Although this method is quick and easy, it bloats our data to three times more than the original data. To accurately sum the visits for each user_id, our data also has to be shipped across the network to other executors.
What are the alternatives to exploding and grouping?
One option is to create a UDF that does the calculations in place, avoiding or minimizing shuffles. The following example is in Scala.
Another option that was recently introduced in Spark 2.4 is the aggregate function. This function can also reduce the amount of shuffle data to a bare minimum, just the user_id and the count of their visits:
Huge data joins (bucketing)
When performing join operations, Spark repartitions (shuffles) the data by the join keys.
If you perform multiple joins on the same table or tables with the same key, you can use bucketing to shuffle the data only once. When persisting the data, any subsequent joins on that same key don’t require shuffle because the data is already “pre-shuffled” on Amazon S3.
To bucket your data, you need to decide on the number of buckets to divide your data into and the columns on which the bucketing occurs.
Work with data skew
In some cases, data doesn’t distribute uniformly between partitions. This is an issue for several reasons:
- Generally, most of the executors finish in a timely manner. However, those that handle the large outliers run for a longer time. This increases your risk of getting your Spot Instances interrupted and having to recompute the whole job. It also has a negative impact on overall performance and prolongs the length of the job or causes resources to be underutilized.
- Data skew can also be a source for large amounts of shuffle data, which can cause issues as discussed previously.
To handle data skew, we recommend that you try to do the computation that you’re interested in locally on the executors. You then compute over the results. This approach is also known as a combine operation.
A common technique to handle data skew is salting the keys.
Break huge Spark jobs into smaller ones to increase resiliency
One antipattern that we encounter is large applications that perform numerous jobs that can take hours or days to complete.
This kind of job creates an all-or-nothing situation. Here, a failure can cause loss of time and money due to an issue throughout the runtime of the job.
It might sound obvious, but breaking up your jobs to a chain of smaller jobs increases your resiliency to handle failures and Spot interruptions. Breaking up jobs also means that you can remediate any issues preventing the job from finishing successfully. In addition, it decreases the chances of losing the effort already invested in the process.
Work with Amazon EMR Instance fleets
You can use Amazon EMR instance fleets in a couple of techniques to work effectively with Spark.
Diversify the EC2 instance types in your cluster
By configuring Amazon EMR instance fleets, you can set up a fleet of up to five EC2 instance types for each Amazon EMR node type (Master, Core, Task). As discussed earlier, being instance-flexible is key to the ability to launch and maintain Spot capacity for your Amazon EMR cluster.
For the Master node group, one instance out of your selection is chosen by Amazon EMR. In the Core and Task node groups, Amazon EMR selects the best instance types to use in the cluster based on capacity availability and low price. Also, you can specify multiple subnets in different Availability Zones. In this case, Amazon EMR selects the AZ that best fits the target capacity to launch the entire cluster in.
Size Amazon EMR instance fleets according to the job’s hardware requirements
Amazon EMR instance fleets enable you to define a pool of resources by specifying which instance types fit your application. You can also specify the weight each instance type carries in the pool toward your target capacity.
By default, instances are given weight equivalent to the number of their vCPUs. However, you can also provide weights according to other instance characteristics, such as memory, which I demonstrate in this section.
Sizing by CPU:
For example, suppose that I have a job that requires four cores per executor and 1 GB RAM per core, so the Spark configuration is as follows:
We want the job to run with 20 executors, which means that we need 80 cores (20*4):
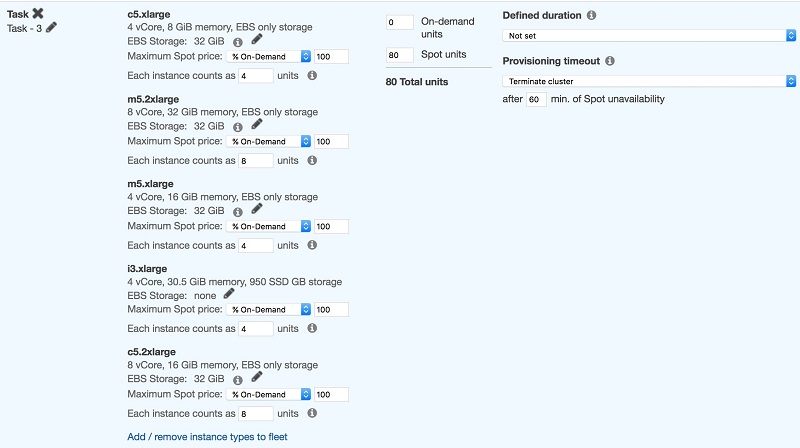
The screenshot shows 80 Spot Units as a representation of the 80 cores that are needed to run the job. It also shows the selection of different instance types that fit the hardware requirements.
Amazon EMR chooses any combination of these instance types to fulfill my target capacity of 80 spot units, while possibly some of the larger instance types will run more than one executor.
Sizing by memory
Some Spark application requirements are memory-intensive and require a different weight strategy.
For example, if our job runs with four cores and 6 GB per core (--executor-cores 4 --executor-memory 24G), we first choose instances that have at least 28 GB of RAM:
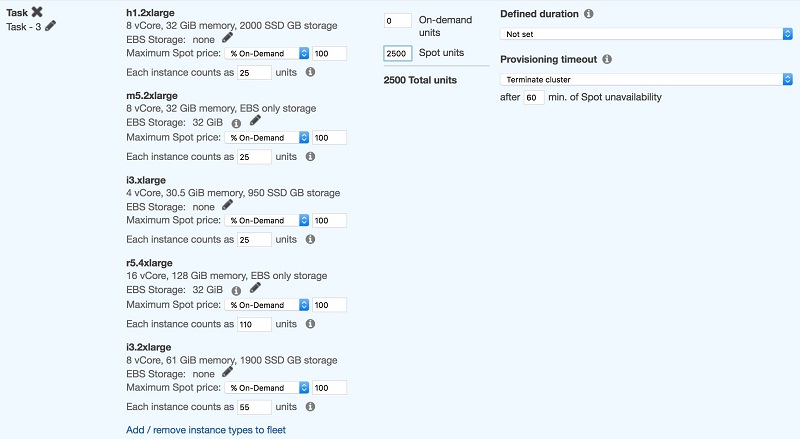
As you can see in the screenshot, in this configuration the instance type selection is set to accommodate the memory requirement. This leaves about 15–20 percent memory free for other processes running inside the instance operating system.
You then calculate the total units calculated by multiplying the number of units of the smallest eligible instances, with the desired number of executors (25*100).
As in the CPU intensive job, some instance types run only one executor while some run several.
Compensating for performance differences between instance generations
Some workloads can see performance improvements of up to 50 percent just by running on newer instance types. This effect is due to AWS Nitro technology, fast CPU clock speeds, or different CPU architecture (moving from Haswell/Broadwell to Skylake), or a combination of these.
If decreasing application running time is a major requirement, you can offset the performance difference between instance type generations by specifying smaller weights to the older instance generations.
For example, suppose that your job runs for an hour with 10 r5.2xlarge instance and two hours with 10 r4.2xlarge instance. In this case, you might prefer defining your instance fleet as follows:
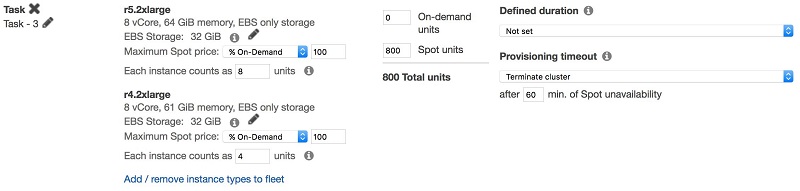
Select the right purchase option for each node type
Spot Blocks are defined-duration Spot Instances that can run up to six hours without being interrupted, and come at a smaller discount rate compared to Spot Instances. However, you can also use Spot Blocks if your jobs can’t suffer Spot interruptions, given that the cluster run time is forecasted to be smaller than six hours.
Master node: Unless your cluster is very short-lived and the runs are cost-driven, avoid running your Master node on a Spot Instance. We suggest this because a Spot interruption on the Master node terminates the entire cluster. Alternatively to On-Demand, you can set up the Master node on a Spot Block. You do so by setting the defined duration of the node and failing over to On-Demand if the Spot Block capacity is unavailable.
Core nodes: Avoid using Spot Instances for Core nodes if the jobs on the cluster use HDFS. That prevents a situation where Spot interruptions cause data loss for data that was written to the HDFS volumes on the instances.
Task nodes: Use Spot Instances for your task nodes by selecting up to five instance types that match your hardware requirement. Amazon EMR fulfills the most suitable capacity by price and capacity availability.
Get EC2 Spot interruption notifications
When EC2 needs to interrupt Spot Instances, a 2-minute warning is issued for each instance that is going to be interrupted. You can programmatically react to the warning in two ways: from within the instance by polling the instance’s metadata service, and by using Amazon CloudWatch Events. You can find the specifics in the documentation.
The use of this warning varies between types of workloads. For example, you can opt to detach the soon-to-be interrupted instances from an Elastic Load Balancer to drain in-flight connections before the instance gets shuts down. Alternatively, you can copy the logs to a centralized location, or gracefully shut down an application.
To learn more about how EMR handles EC2 Spot interruptions, see the AWS Big Data blog post
Spark enhancements for elasticity and resiliency on Amazon EMR.
You might still want to track the Spot interruptions, possibly to correlate between Amazon EMR job failures and Spot interruptions or job length. In this case, you can set up a CloudWatch Event to trigger an AWS Lambda function to feed the interruption into a data store. This approach means that you can query the historical interruptions in your account. For smaller scale or even initial testing, you can use Amazon SNS with an email target to simply get the interruption notifications by email.
Tag your Amazon EMR cluster and track your costs
Tagging your resources in the AWS Cloud is a fundamental best practice. You can read more about tagging strategies on this AWS Answers page. In Amazon EMR, after you tag the cluster, your tags propagate to the underlying EC2 instances and the Amazon EBS volumes that are created by the cluster. This enables you to have a holistic view of the costs of running your Amazon EMR clusters, and can be easily visualized with AWS Cost Explorer.
Summary
In this blog post, we list best practices for cost-optimizing your Spark applications on Amazon EMR by using Spot Instances. We hope that you find these useful and that you test these best practices with your Spark applications to cost-optimize your workloads.
About the authors
 Ran Sheinberg is a specialist solutions architect for EC2 Spot Instances with Amazon Web Services. He works with AWS customers on cost optimizing their compute spend by utilizing Spot Instances across different types of workloads: stateless web applications, queue workers, containerized workloads, analytics, HPC and others.
Ran Sheinberg is a specialist solutions architect for EC2 Spot Instances with Amazon Web Services. He works with AWS customers on cost optimizing their compute spend by utilizing Spot Instances across different types of workloads: stateless web applications, queue workers, containerized workloads, analytics, HPC and others.
 Daniel Haviv is a specialist solutions architect for Analytics with Amazon Web Services.
Daniel Haviv is a specialist solutions architect for Analytics with Amazon Web Services.
Audit History
Last reviewed and updated in April 2024 by Uday Narayanan | Principal Solutions Architect