AWS Big Data Blog
Build an Apache Iceberg data lake using Amazon Athena, Amazon EMR, and AWS Glue
March 2024: This post was reviewed and updated for accuracy.
Most businesses store their critical data in a data lake, where you can bring data from various sources to a centralized storage. The data is processed by specialized big data compute engines, such as Amazon Athena for interactive queries, Amazon EMR for Apache Spark applications, Amazon SageMaker for machine learning, and Amazon QuickSight for data visualization.
Apache Iceberg is an open-source table format for data stored in data lakes. It is optimized for data access patterns in Amazon Simple Storage Service (Amazon S3) cloud object storage. Iceberg helps data engineers tackle complex challenges in data lakes such as managing continuously evolving datasets while maintaining query performance. Iceberg allows you to do the following:
- Maintain transactional consistency where files can be added, removed, or modified atomically with full read isolation and multiple concurrent writes
- Implement full schema evolution to process safe table schema updates as the table data evolves
- Organize tables into flexible partition layouts with partition evolution, enabling updates to partition schemes as queries and data volume changes without relying on physical directories
- Perform row-level update and delete operations to satisfy new regulatory requirements such as the General Data Protection Regulation (GDPR)
- Provide versioned tables and support time travel queries to query historical data and verify changes between updates
- Roll back tables to prior versions to return tables to a known good state in case of any issues
In 2021, AWS teams contributed the Apache Iceberg integration with the AWS Glue Data Catalog to open source, which enables you to use open-source compute engines like Apache Spark with Iceberg on AWS Glue. In 2022, Amazon Athena announced support of Iceberg and Amazon EMR added support of Iceberg starting with version 6.5.0.
In this post, we show you how to use Amazon EMR Spark to create an Iceberg table, load sample product data, and use Athena to query, perform schema evolution, row-level update and delete, and time travel, all coordinated through the AWS Glue Data Catalog.
Solution overview
We use the Amazon Science Shopping Queries Dataset as our source data. The dataset contains data files in Apache Parquet format on Amazon S3. We load all the product data as an Iceberg table to demonstrate the advantages of using the Iceberg table format on top of raw Parquet files. The following diagram illustrates our solution architecture.
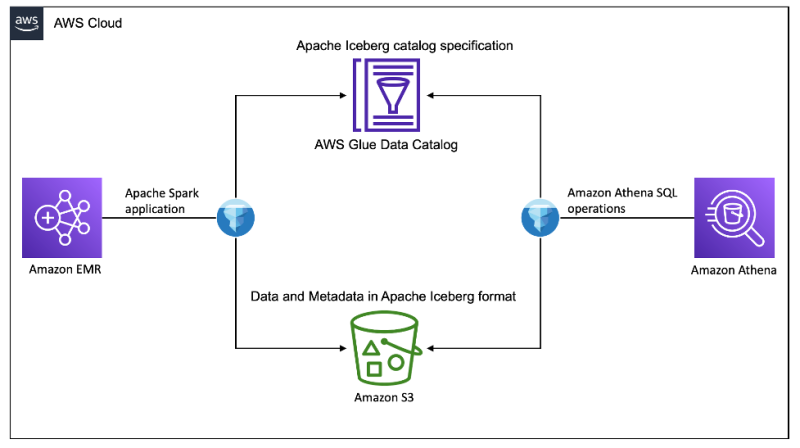
To set up and test this solution, we complete the following high-level steps:
- Create an S3 bucket.
- Create an EMR workspace.
- Configure a Spark session.
- Load data into the Iceberg table.
- Query the data in Athena.
- Perform a row-level update in Athena.
- Perform a schema evolution in Athena.
- Perform time travel in Athena.
- Consume Iceberg data across Amazon EMR and Athena.
Prerequisites
To follow along with this walkthrough, you must have the following:
- An AWS Account with a role that has sufficient access to provision the required resources.
Create an S3 bucket
To create an S3 bucket that holds your Iceberg data, complete the following steps:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Choose Create bucket.
- For Bucket name, enter a name (for this post, we enter
aws-lake-house-iceberg-blog-demo).
Because S3 bucket names are globally unique, choose a different name when you create your bucket.
- For AWS Region, choose your preferred Region (for this post, we use
us-east-1).

- Upload the parquet file from the Amazon Science Shopping Queries Dataset to the bucket.
- If this is the first time that you’re using Athena to run queries, create another globally unique S3 bucket to hold your Athena query output.
Create an EMR workspace
For this demo, we use an EMR workspace to run Spark commands.
- From the EMR console, navigate to Studios and choose Create Studio.
- Under Studio settings, choose Edit and enter iceberg-studio for Studio name.
- Under Workspace settings, choose Edit and enter iceberg-spark-workspace for Workspace name.
- Choose Create Studio and launch Workspace. Once created, your newly created workspace will open in a new tab.
- Under Notebook, choose Spark.

- In a new tab, navigate to the IAM console, and choose Roles in the left navigation bar. Search for
AmazonEMRStudio_RuntimeRole_#############and select it. - Under Permissions policies, choose Add permissions and Attach policies. Attach the AWSGlueConsoleFullAccess policy to your runtime role.
Configure a Spark session
In your notebook, run the following code:
This sets the following Spark session configurations:
- spark.sql.catalog.demo – Registers a Spark catalog named
demo, which uses the Iceberg Spark catalog plugin - spark.sql.catalog.demo.catalog-impl – The
demoSpark catalog uses AWS Glue as the physical catalog to store Iceberg database and table information - spark.sql.catalog.demo.warehouse – The
demoSpark catalog stores all Iceberg metadata and data files under the root paths3://<your-iceberg-blog-demo-bucket> - spark.sql.extensions – Adds support to Iceberg Spark SQL extensions, which allows you to run Iceberg Spark procedures and some Iceberg-only SQL commands (you use this in a later step)
Load data into the Iceberg table
In our Spark session, run the following commands to load data:
Iceberg format v2 is needed to support row-level updates and deletes. See Format Versioning for more details.
It may take up to 15 minutes for the commands to complete. When it’s complete, you should be able to see the products table on the AWS Glue console, under the product_db database, with the Table format property shown as Apache Iceberg.

The table schema is inferred from the source Parquet data files. You can also create the table with a specific schema before loading data using Spark SQL, Athena SQL, or Iceberg Java and Python SDKs.
Query in Athena
Navigate to the Athena console and choose Query editor. If this is your first time using the Athena query editor, you need to configure to use the S3 bucket you created earlier to store the query results.
The table products is available for querying. Run the following query:
The following screenshot shows the first five records from the table being displayed.

Perform a row-level update in Athena
In the next few steps, let’s focus on a record in the table with product ID B083G4FDVV. Currently, it has no product description when we run the following query:

Let’s update the product_description value using the following query:

After your update command runs successfully, run the below query and note the updated result showing a new description:
Athena enforces ACID transaction guarantee for all the write operations against an Iceberg table. This is done through the Iceberg format’s optimistic locking specification. When concurrent attempts are made to update the same record, a commit conflict occurs. In this scenario, Athena displays a transaction conflict error, as shown in the following screenshot.

Delete queries work in a similar way; see DELETE for more details.
Perform a schema evolution in Athena
If you want to know how many of each product have sold over time, add a column as follows to keep track:
If you recently hit an all-time record, then update your quantity_sold.
Based on the AWS Glue table information, the quantity_sold is an integer column. If you try to update a value of 2.5 billion, which is greater than the maximum allowed integer value, you get an error.

Iceberg supports most schema evolution features as metadata-only operations, which don’t require a table rewrite. This includes add, drop, rename, reorder column, and promote column types. To solve this issue, you can change the integer column quantity_sold to a BIGINT type by running the following DDL:
You can now update the value successfully:
Querying the record now gives us the expected result in BIGINT:
Perform time travel in Athena
In Iceberg, the transaction history is retained, and each transaction commit creates a new version. You can perform time travel to look at a historical version of a table. In Athena, you can use the following syntax to travel to a time that is after when the first version was committed:

Consume Iceberg data across Amazon EMR and Athena
One of the most important features of a data lake is for different systems to seamlessly work together through the Iceberg open-source protocol. After all the operations are performed in Athena, let’s go back to Amazon EMR and confirm that Amazon EMR Spark can consume the updated data.
First, run the same Spark SQL in the Amazon EMR Workspace you created, and see if you get the description you set earlier:
Spark shows the new description you set for the product.

Check the transaction history of the operation in Athena through Spark Iceberg’s history system table:
This shows four transactions corresponding to the updates you ran in Athena.

Iceberg offers a variety of Spark procedures to optimize the table. For example, you can run an expire_snapshots procedure to remove old snapshots, and free up storage space in Amazon S3:
Note that, after running this procedure, time travel can no longer be performed against expired snapshots.
Examine the history system table again and notice that it shows you only the most recent snapshot.
Running the following query in Athena results in an error “No table snapshot found before timestamp…” as older snapshots were deleted, and you are no longer able to time travel to the older snapshot:
Clean up
To avoid incurring ongoing costs, complete the following steps to clean up your resources:
- Run the following code in your notebook to drop the AWS Glue table and database:
- On the Amazon EMR console, choose Workspaces in the navigation pane.
- Select the notebook
iceberg-spark-workspaceand choose Delete under Actions. - Choose Studios in the navigation pane.
- Select the studio
iceberg_studioand choose Delete. - Choose Clusters in the navigation pane.
- Select the cluster
Iceberg Spark Clusterand choose Terminate. - Delete the S3 buckets and any other resources that you created as part of the prerequisites for this post.
Conclusion
In this post, we showed you an example of using Amazon S3, AWS Glue, Amazon EMR, and Athena to build an Iceberg data lake on AWS. An Iceberg table can seamlessly work across two popular compute engines, and you can take advantage of both to design your customized data production and consumption use cases.
With AWS Glue, Amazon EMR, and Athena, you can already use many features through AWS integrations, such as SageMaker Athena integration for machine learning, or QuickSight Athena integration for dashboard and reporting. AWS Glue also offers the Iceberg connector, which you can use to author and run Iceberg data pipelines.
In addition, Iceberg supports a variety of other open-source compute engines that you can choose from. For example, you can use Apache Flink on Amazon EMR for streaming and change data capture (CDC) use cases. The strong transaction guarantee and efficient row-level update, delete, time travel, and schema evolution experience offered by Iceberg offers a sound foundation and infinite possibilities for users to unlock the power of big data.
About the Authors
 Kishore Dhamodaran is a Senior Solutions Architect at AWS. Kishore helps strategic customers with their cloud enterprise strategy and migration journey, leveraging his years of industry and cloud experience.
Kishore Dhamodaran is a Senior Solutions Architect at AWS. Kishore helps strategic customers with their cloud enterprise strategy and migration journey, leveraging his years of industry and cloud experience.
 Jack Ye is a software engineer of the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
Jack Ye is a software engineer of the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
 Mohit Mehta is a Principal Architect at AWS with expertise in AI/ML and data analytics. He holds 12 AWS certifications and is passionate about helping customers implement cloud enterprise strategies for digital transformation. In his free time, he trains for marathons and plans hikes across major peaks around the world.
Mohit Mehta is a Principal Architect at AWS with expertise in AI/ML and data analytics. He holds 12 AWS certifications and is passionate about helping customers implement cloud enterprise strategies for digital transformation. In his free time, he trains for marathons and plans hikes across major peaks around the world.
 Giovanni Matteo Fumarola is the Engineering Manager of the Athena Data Lake and Storage team. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013.
Giovanni Matteo Fumarola is the Engineering Manager of the Athena Data Lake and Storage team. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013.
 Jared Keating is a Senior Cloud Consultant with AWS Professional Services. Jared assists customers with their cloud infrastructure, compliance, and automation requirements, drawing from his 20+ years of IT experience.
Jared Keating is a Senior Cloud Consultant with AWS Professional Services. Jared assists customers with their cloud infrastructure, compliance, and automation requirements, drawing from his 20+ years of IT experience.
 Miriam Lebowitz is a Solutions Architect in the Strategic ISV segment at AWS. She is engaged with teams across Salesforce, including Heroku. Outside of work she enjoys baking, traveling, and spending quality time with friends and family.
Miriam Lebowitz is a Solutions Architect in the Strategic ISV segment at AWS. She is engaged with teams across Salesforce, including Heroku. Outside of work she enjoys baking, traveling, and spending quality time with friends and family.
Audit History
Last reviewed and updated in March 2024 by Miriam Lebowitz | Solutions Architect