AWS Big Data Blog
Category: Amazon EMR
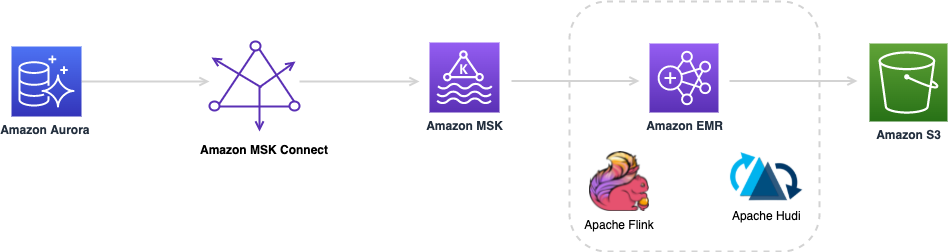
Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. During the recent years, there has been a shift from monolithic to the microservices architecture. The microservices architecture makes applications easier to scale and quicker to develop, […]

How Cynamics built a high-scale, near-real-time, streaming AI inference system using AWS
This post is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics. Cynamics provides a new paradigm of cybersecurity — predicting attacks long before they hit by collecting small network samples (less than 1%), inferring from them how the full network (100%) behaves, and predicting threats […]

Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger. Ensuring complete financial reconciliation at this scale is critical […]
How Belcorp decreased cost and improved reliability in its big data processing framework using Amazon EMR managed scaling
This is a guest post by Diego Benavides and Luis Bendezú, Senior Data Architects, Data Architecture Direction at Belcorp. Belcorp is one of the main consumer packaged goods (CPG) companies providing cosmetics products in the region for more than 50 years, allocated to around 13 countries in North, Central, and South America (AMER). Born in Peru […]
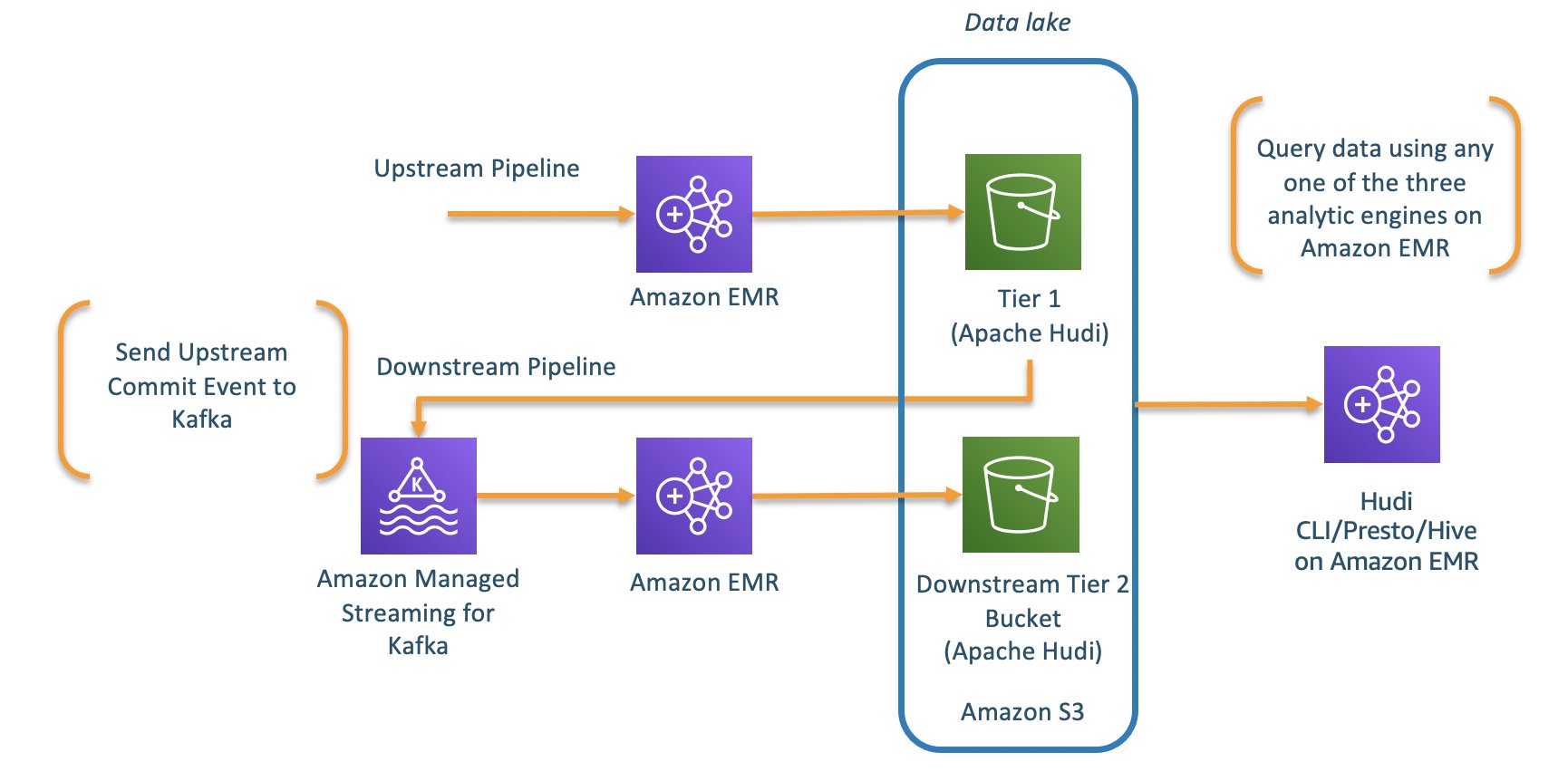
New features from Apache Hudi 0.7.0 and 0.8.0 available on Amazon EMR
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development by providing record-level insert, update, and delete capabilities. This record-level capability is helpful if you’re building your data lakes on Amazon Simple Storage Service (Amazon S3) or Hadoop Distributed File System (HDFS). You can use it […]

How Goldman Sachs built persona tagging using Apache Flink on Amazon EMR
The Global Investment Research (GIR) division at Goldman Sachs is responsible for providing research and insights to the firm’s clients in the equity, fixed income, currency, and commodities markets. One of the long-standing goals of the GIR team is to deliver a personalized experience and relevant research content to their research users. Previously, in order to customize […]

Announcing Amazon EMR Serverless (Preview): Run big data applications without managing servers
Today we’re happy to announce Amazon EMR Serverless, a new option in Amazon EMR that makes it easy and cost-effective for data engineers and analysts to run petabyte-scale data analytics in the cloud. With EMR Serverless, you can run applications built using open-source frameworks such as Apache Spark and Hive without having to configure, manage, […]
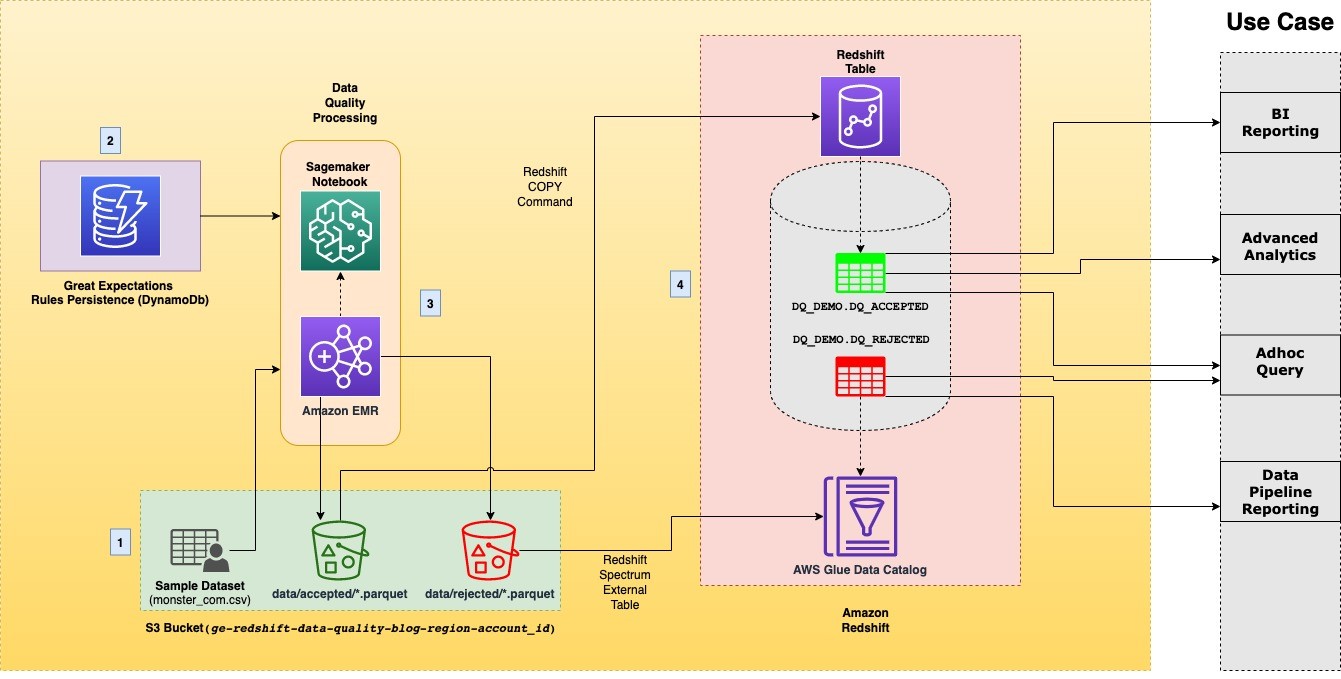
Provide data reliability in Amazon Redshift at scale using Great Expectations library
Ensuring data reliability is one of the key objectives of maintaining data integrity and is crucial for building data trust across an organization. Data reliability means that the data is complete and accurate. It’s the catalyst for delivering trusted data analytics and insights. Incomplete or inaccurate data leads business leaders and data analysts to make […]

Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes
The AWS Glue Data Catalog provides partition indexes to accelerate queries on highly partitioned tables. In the post Improve query performance using AWS Glue partition indexes, we demonstrated how partition indexes reduce the time it takes to fetch partition information during the planning phase of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS […]

Now Available: Updated guidance on the Data Analytics Lens for AWS Well-Architected Framework
Nearly all businesses today require some form of data analytics processing, from auditing user access to generating sales reports. For all your analytics needs, the Data Analytics Lens for AWS Well-Architected Framework provides prescriptive guidance to help you assess your workloads and identify best practices aligned to the AWS Well-Architected Pillars: Operational Excellence, Security, Reliability, […]