AWS Big Data Blog
Category: AWS Glue

How GE Aviation automated engine wash analytics with AWS Glue using a serverless architecture
This post is authored by Giridhar G Jorapur, GE Aviation Digital Technology. Maintenance and overhauling of aircraft engines are essential for GE Aviation to increase time on wing gains and reduce shop visit costs. Engine wash analytics provide visibility into the significant time on wing gains that can be achieved through effective water wash, foam […]

Validate streaming data over Amazon MSK using schemas in cross-account AWS Glue Schema Registry
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Today’s businesses face an unprecedented growth in the volume of data. A growing portion of the data is generated in real time by IoT devices, websites, business […]
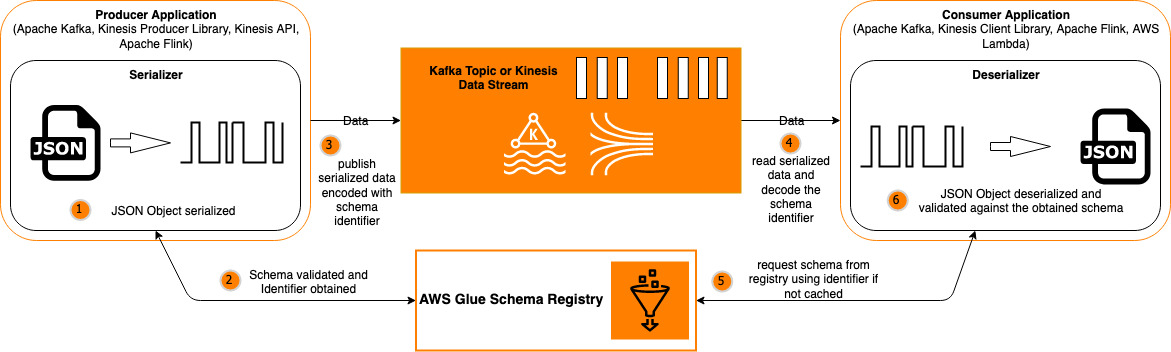
Evolve JSON Schemas in Amazon MSK and Amazon Kinesis Data Streams with the AWS Glue Schema Registry
Data is being produced, streamed, and consumed at an immense rate, and that rate is projected to grow exponentially in the future. In particular, JSON is the most widely used data format across streaming technologies and workloads. As applications, websites, and machines increasingly adopt data streaming technologies such as Apache Kafka and Amazon Kinesis Data […]

Handle fast-changing reference data in an AWS Glue streaming ETL job
Streaming ETL jobs in AWS Glue can consume data from streaming sources such as Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, as well as continuously load the results into Amazon Simple Storage Service (Amazon S3) data lakes, data warehouses, or other data stores. The always-on nature of streaming jobs poses […]

Securely share your data across AWS accounts using AWS Lake Formation
Data lakes have become very popular with organizations that want a centralized repository that allows you to store all your structured data and unstructured data at any scale. Because data is stored as is, there is no need to convert it to a predefined schema in advance. When you have new business use cases, you […]

Enrich datasets for descriptive analytics with AWS Glue DataBrew
Data analytics remains a constantly hot topic. More and more businesses are beginning to understand the potential their data has to allow them to serve customers more effectively and give them a competitive advantage. However, for many small to medium businesses, gaining insight from their data can be challenging because they often lack in-house data […]

Query cross-account AWS Glue Data Catalogs using Amazon Athena
Many AWS customers rely on a multi-account strategy to scale their organization and better manage their data lake across different projects or lines of business. The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. Using a centralized Data Catalog […]

Ibotta builds a self-service data lake with AWS Glue
This is a guest post co-written by Erik Franco at Ibotta. Ibotta is a free cash back rewards and payments app that gives consumers real cash for everyday purchases when they shop and pay through the app. Ibotta provides thousands of ways for consumers to earn cash on their purchases by partnering with more than […]

Effective data lakes using AWS Lake Formation, Part 2: Creating a governed table for streaming data sources
February 2023: The content of this blog post can be now be found on AWS Lake Formation public documentation. Please refer to it instead. We announced the general availability of AWS Lake Formation transactions, row-level security, and acceleration at AWS re:Invent 2021. In Part 1 of this series, we explained how to set up a […]

Simplify Snowflake data loading and processing with AWS Glue DataBrew
May 2024: Connecting to Snowflake as a data source is now supported natively. To learn more, visit our documentation. Historically, inserting and retrieving data from a given database platform has been easier compared to a multi-platform architecture for the same operations. To simplify bringing data in from a multi-database platform, AWS Glue DataBrew supports bringing […]