AWS Big Data Blog
Category: AWS Glue

Enhance analytics with Google Trends data using AWS Glue, Amazon Athena, and Amazon QuickSight
In today’s market, business success often lies in the ability to glean accurate insights and predictions from data. However, data scientists and analysts often find that the data they have at their disposal isn’t enough to help them make accurate predictions for their use cases. A variety of factors might alter an outcome and should […]

Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container. Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs. Jan 2023: This post was reviewed and updated with enhanced […]

Best practices to optimize data access performance from Amazon EMR and AWS Glue to Amazon S3
June 2024: This post was reviewed for accuracy and updated to cover Apache Iceberg. June 2023: This post was reviewed and updated for accuracy. Customers are increasingly building data lakes to store data at massive scale in the cloud. It’s common to use distributed computing engines, cloud-native databases, and data warehouses when you want to […]

Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry
September 2025: This post was reviewed for accuracy. AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry […]

Design patterns: Set up AWS Glue Crawlers using S3 event notifications
The AWS Well-Architected Data Analytics Lens provides a set of guiding principles for analytics applications on AWS. One of the best practices it talks about is build a central Data Catalog to store, share, and track metadata changes. AWS Glue provides a Data Catalog to fulfill this requirement. AWS Glue also provides crawlers that automatically […]
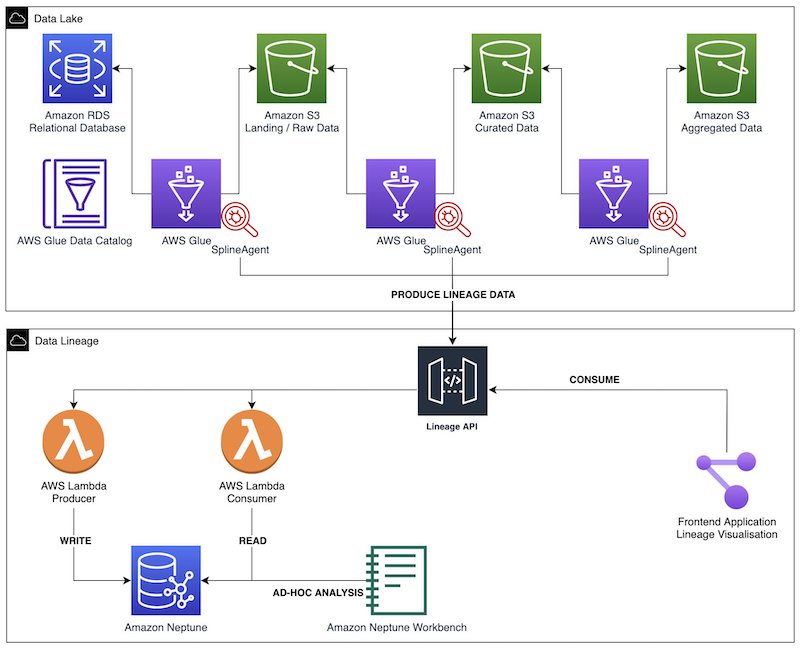
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by […]

Build a serverless pipeline to analyze streaming data using AWS Glue, Apache Hudi, and Amazon S3
Organizations typically accumulate massive volumes of data and continue to generate ever-exceeding data volumes, ranging from terabytes to petabytes and at times to exabytes of data. Such data is usually generated in disparate systems and requires an aggregation into a single location for analysis and insight generation. A data lake architecture allows you to aggregate […]

How the Georgia Data Analytics Center built a cloud analytics solution from scratch with the AWS Data Lab
This is a guest post by Kanti Chalasani, Division Director at Georgia Data Analytics Center (GDAC). GDAC is housed within the Georgia Office of Planning and Budget to facilitate governed data sharing between various state agencies and departments. The Office of Planning and Budget (OPB) established the Georgia Data Analytics Center (GDAC) with the intent […]

Audit AWS service events with Amazon EventBridge and Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS […]

Extract ServiceNow data using AWS Glue Studio in an Amazon S3 data lake and analyze using Amazon Athena
Many different cloud-based software as a service (SaaS) offerings are available in AWS. ServiceNow is one of the common cloud-based workflow automation platforms widely used by AWS customers. In the past few years, we saw a lot of customers who wanted to extract and integrate data from IT service management (ITSM) tools like ServiceNow for […]