AWS Big Data Blog
Build a serverless pipeline to analyze streaming data using AWS Glue, Apache Hudi, and Amazon S3
Organizations typically accumulate massive volumes of data and continue to generate ever-exceeding data volumes, ranging from terabytes to petabytes and at times to exabytes of data. Such data is usually generated in disparate systems and requires an aggregation into a single location for analysis and insight generation. A data lake architecture allows you to aggregate data present in various silos, store it in a centralized repository, enforce data governance, and support analytics and machine learning (ML) on top of this stored data.
Typical building blocks to implement such an architecture include a centralized repository built on Amazon Simple Storage Service (Amazon S3) providing the least possible unit cost of storage per GB, big data ETL (extract, transform, and load) frameworks such as AWS Glue, and analytics using Amazon Athena, Amazon Redshift, and Amazon EMR notebooks.
Building such systems involves technical challenges. For example, data residing in S3 buckets can’t be updated in-place using standard data ingestion approaches. Therefore, you must perform constant ad-hoc ETL jobs to consolidate data into new S3 files and buckets.
This is especially the case with streaming sources, which require constant support for increasing data velocity to provide faster insights generation. An example use case might be an ecommerce company looking to build a real-time date lake. They need their solution to do the following:
- Ingest continuous changes (like customer orders) from upstream systems
- Capture tables into the data lake
- Provide ACID properties on the data lake to support interactive analytics by enabling consistent views on data while new data is being ingested
- Provide schema flexibility due to upstream data layout changes and provisions for late arrival of data
To deliver on these requirements, organizations have to build custom frameworks to handle in-place updates (also referred as upserts), handle small files created due to the continuous ingestion of changes from upstream systems (such as databases), handle schema evolution, and compromise on providing ACID guarantees on its data lake.
A processing framework like Apache Hudi can be a good way solve such challenges. Hudi allows you to build streaming data lakes with incremental data pipelines, with support for transactions, record-level updates, and deletes on data stored in data lakes. Hudi is integrated with various AWS analytics services, like AWS Glue, Amazon EMR, Athena, and Amazon Redshift. This helps you ingest data from a variety of sources via batch streaming while enabling in-place updates to an append-oriented storage system such as Amazon S3 (or HDFS). In this post, we discuss a serverless approach to integrate Hudi with a streaming use case and create an in-place updatable data lake on Amazon S3.
Solution overview
We use Amazon Kinesis Data Generator to send sample streaming data to Amazon Kinesis Data Streams. To consume this streaming data, we set up an AWS Glue streaming ETL job that uses the Apache Hudi Connector for AWS Glue to write ingested and transformed data to Amazon S3, and also creates a table in the AWS Glue Data Catalog.
After the data is ingested, Hudi organizes a dataset into a partitioned directory structure under a base path pointing to a location in Amazon S3. Data layout in these partitioned directories depends on the Hudi dataset type used during ingestion, such as Copy on Write (CoW) and Merge on Read (MoR). For more information about Hudi storage types, see Using Athena to Query Apache Hudi Datasets and Storage Types & Views.
CoW is the default storage type of Hudi. In this storage type, data is stored in columnar format (Parquet). Each ingestion creates a new version of files during a write. With CoW, each time there is an update to a record, Hudi rewrites the original columnar file containing the record with the updated values. Therefore, this is better suited for read-heavy workloads on data that changes less frequently.
The MoR storage type is stored using a combination of columnar (Parquet) and row-based (Avro) formats. Updates are logged to row-based delta files and are compacted to create new versions of columnar files. With MoR, each time there is an update to a record, Hudi writes only the row for the changed record into the row-based (Avro) format, which is compacted (synchronously or asynchronously) to create columnar files. Therefore, MoR is better suited for write or change-heavy workloads with a lesser amount of read.
For this post, we use the CoW storage type to illustrate our use case of creating a Hudi dataset and serving the same via a variety of readers. You can extend this solution to support MoR storage via selecting the specific storage type during ingestion. We use Athena to read the dataset. We also illustrate the capabilities of this solution in terms of in-place updates, nested partitioning, and schema flexibility.
The following diagram illustrates our solution architecture.

Create the Apache Hudi connection using the Apache Hudi Connector for AWS Glue
To create your AWS Glue job with an AWS Glue custom connector, complete the following steps:
- On the AWS Glue Studio console, choose Marketplace in the navigation pane.
- Search for and choose Apache Hudi Connector for AWS Glue.

- Choose Continue to Subscribe.
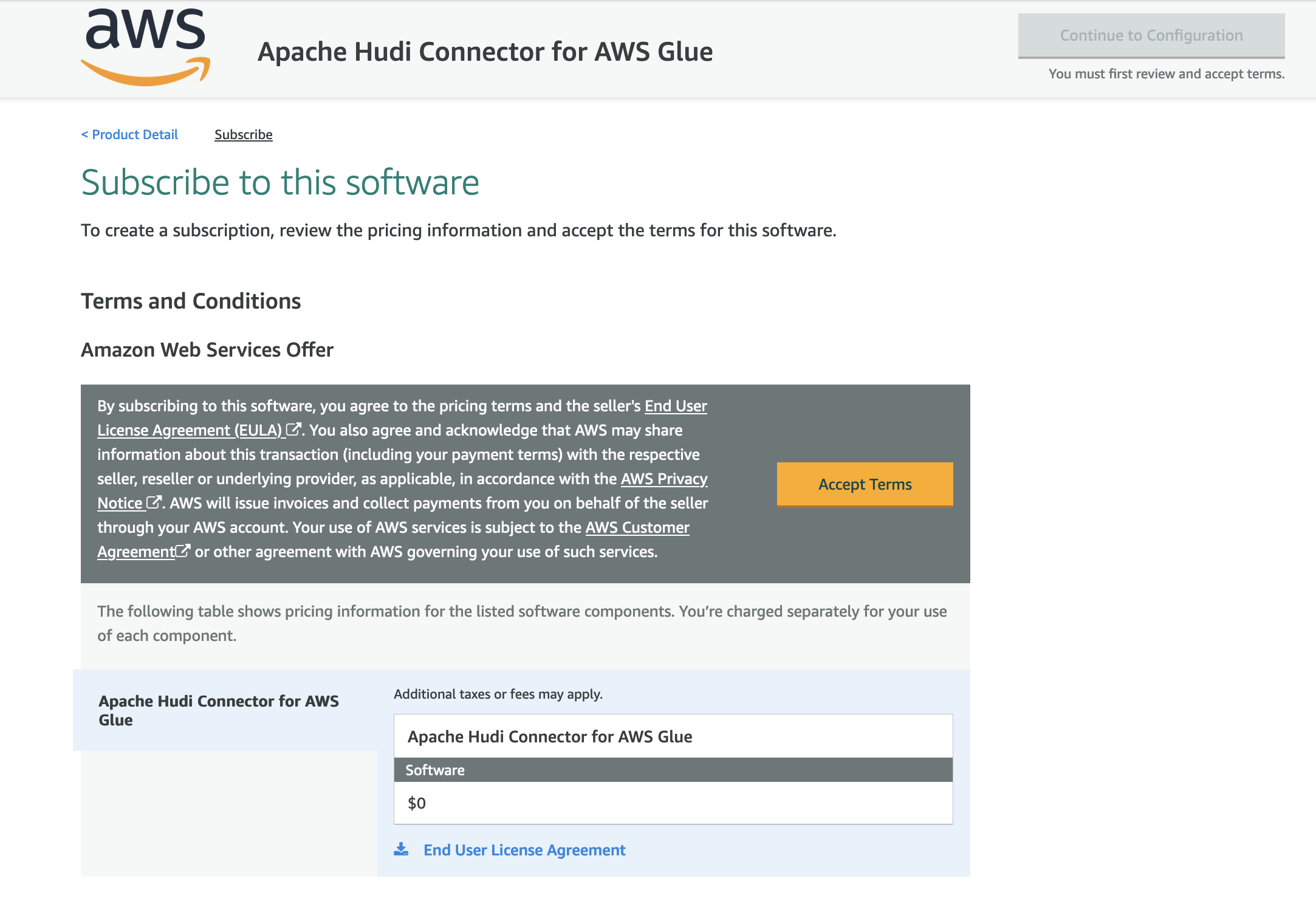
- Review the terms and conditions and choose Accept Terms.
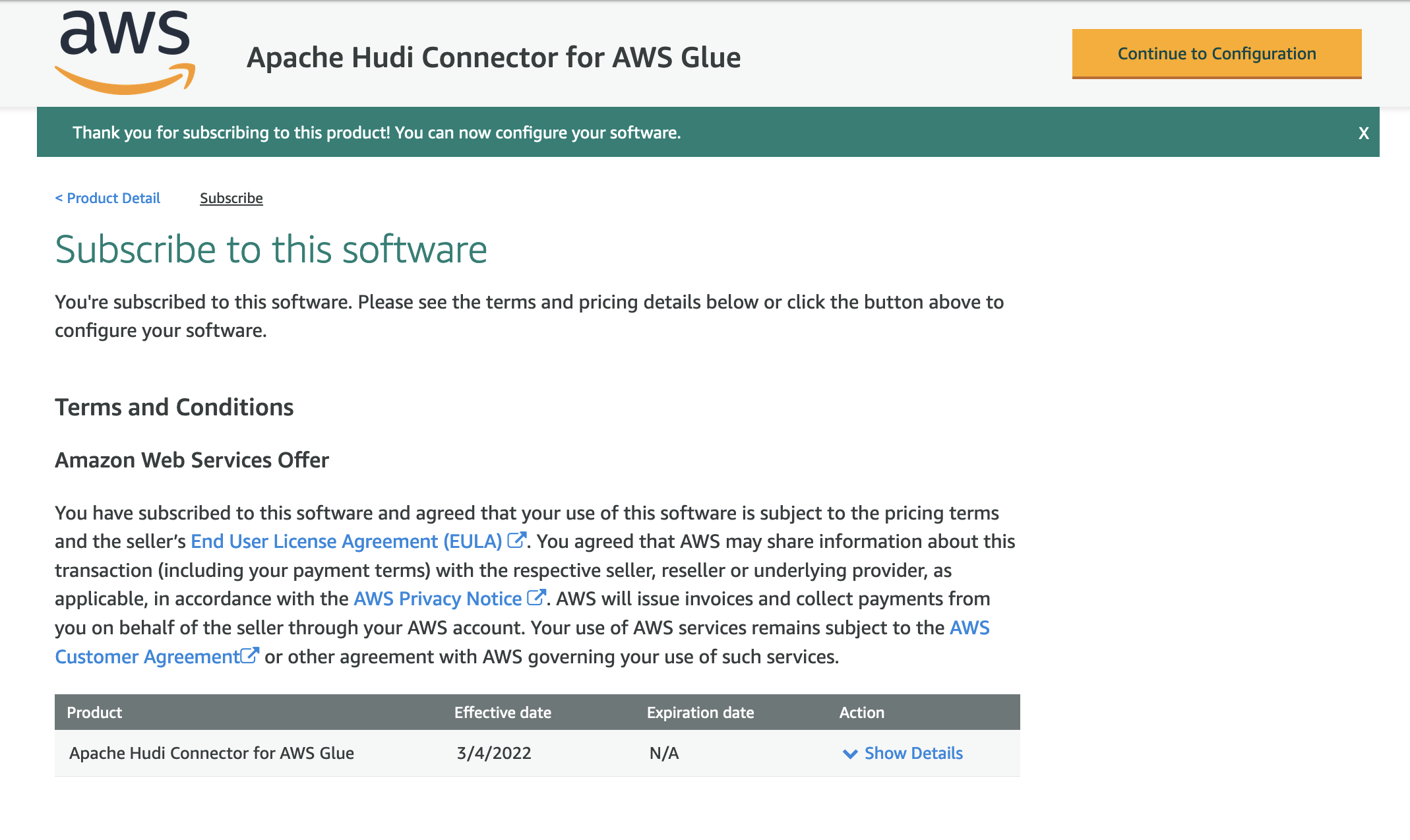
- Make sure that the subscription is complete and you see the Effective date populated next to the product, then choose Continue to Configuration.
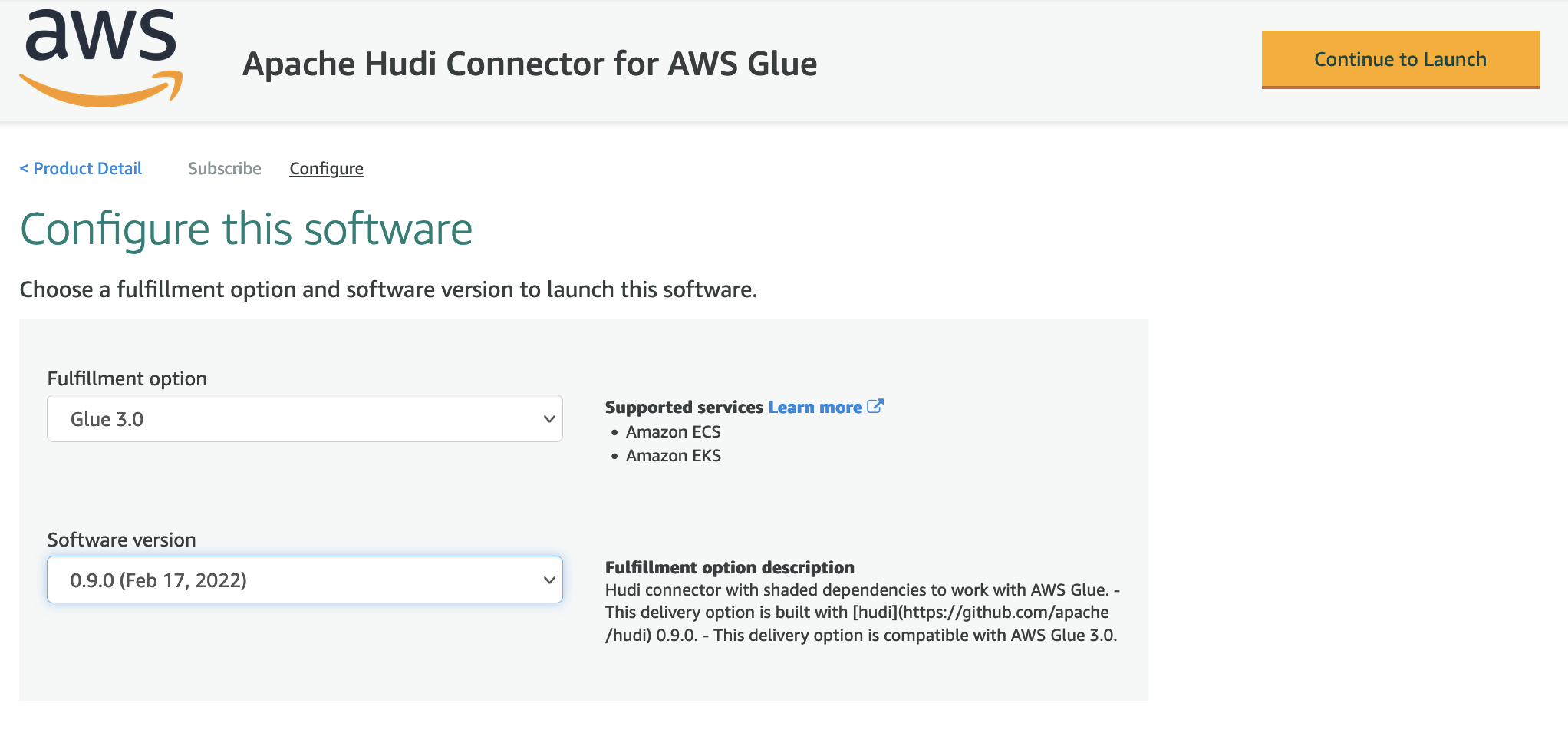
- For Delivery Method, choose Glue 3.0.
- For Software Version, choose the latest version (as of this writing, 0.9.0 is the latest version of the Apache Hudi Connector for AWS Glue).
- Choose Continue to Launch.
- Under Launch this software, choose Usage Instructions and then choose Activate the Glue connector for Apache Hudi in AWS Glue Studio.

You’re redirected to AWS Glue Studio.
- For Name, enter a name for your connection (for example, hudi-connection).
- For Description, enter a description.
- Choose Create connection and activate connector.

A message appears that the connection was successfully created, and the connection is now visible on the AWS Glue Studio console.

Configure resources and permissions
For this post, we provide an AWS CloudFormation template to create the following resources:
- An S3 bucket named
hudi-demo-bucket-<your-stack-id>that contains a JAR artifact copied from another public S3 bucket outside of your account. This JAR artifact is then used to define the AWS Glue streaming job. - A Kinesis data stream named
hudi-demo-stream-<your-stack-id>. - An AWS Glue streaming job named
Hudi_Streaming_Job-<your-stack-id>with a dedicated AWS Glue Data Catalog namedhudi-demo-db-<your-stack-id>. Refer to the aws-samples github repository for the complete code of the job. - AWS Identity and Access Management (IAM) roles and policies with appropriate permissions.
- AWS Lambda functions to copy artifacts to the S3 bucket and empty buckets first upon stack deletion.
To create your resources, complete the following steps:
- Choose Launch Stack:

- For Stack name, enter
hudi-connector-blog-for-streaming-data. - For HudiConnectionName, use the name you specified in the previous section.
- Leave the other parameters as default.
- Choose Next.

- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
Set up Kinesis Data Generator
In this step, you configure Kinesis Data Generator to send sample data to a Kinesis data stream.
- On the Kinesis Data Generator console, choose Create a Cognito User with CloudFormation.

You’re redirected to the AWS CloudFormation console.
- On the Review page, in the Capabilities section, select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.
- On the Stack details page, in the Stacks section, verify that the status shows
CREATE_COMPLETE. - On the Outputs tab, copy the URL value for
KinesisDataGeneratorUrl.
- Navigate to this URL in your browser.
- Enter the user name and password provided and choose Sign In.
Start an AWS Glue streaming job
To start an AWS Glue streaming job, complete the following steps:
- On the AWS CloudFormation console, navigate to the Resources tab of the stack you created.
- Copy the physical ID corresponding to the AWS::Glue::Job resource.

- On the AWS Glue Studio console, find the job name using the physical ID.
- Choose the job to review the script and job details.

- Choose Run to start the job.

- On the Runs tab, validate if the job is successfully running.

Send sample data to a Kinesis data stream
Kinesis Data Generator generates records using random data based on a template you provide. Kinesis Data Generator extends faker.js, an open-source random data generator.
In this step, you use Kinesis Data Generator to send sample data using a sample template using the faker.js documentation to the previously created data stream created at one record per second rate. You sustain the ingestion until the end of this tutorial to achieve reasonable data for analysis while performing the remaining steps.
- On the Kinesis Data Generator console, for Records per second, choose the Constant tab, and change the value to
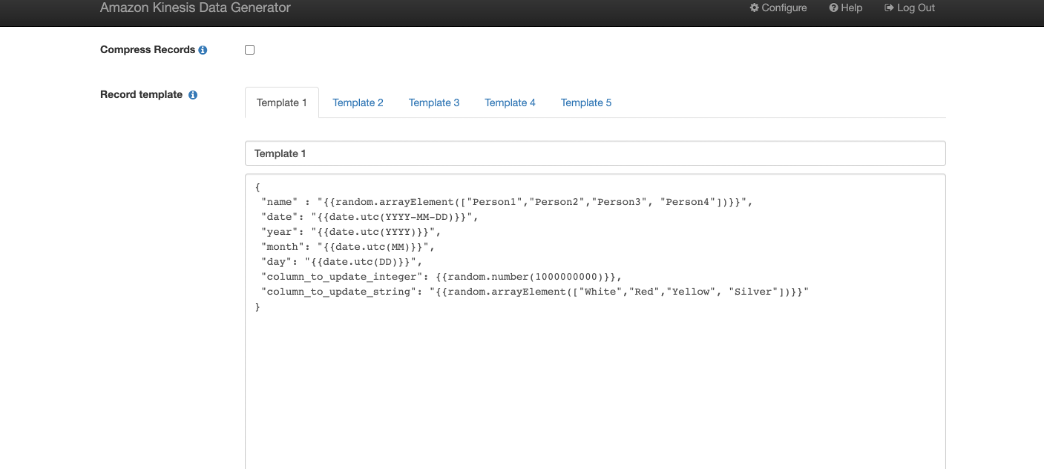
1. - For Record template, choose the Template 1 tab, and enter the following code sample into the text box:
- Choose Test template.

- Verify the structure of the sample JSON records and choose Close.

- Choose Send data.
- Leave the Kinesis Data Generator page open to ensure sustained streaming of random records into the data stream.
Continue through the remaining steps while you generate your data.

Verify dynamically created resources
While you’re generating data for analysis, you can verify the resources you created.
Amazon S3 dataset
When the AWS Glue streaming job runs, the records from the Kinesis data stream are consumed and stored in an S3 bucket. While creating Hudi datasets in Amazon S3, the streaming job can also create a nested partition structure. This is enabled through the usage of Hudi configuration properties hoodie.datasource.write.partitionpath.field and hoodie.datasource.write.keygenerator.class in the streaming job definition.
In this example, nested partitions have been created by name, year, month, and day. The values of these properties are set as follows in the script for the AWS Glue streaming job.

For further details on how CustomKeyGenerator works to generate such partition paths, refer to Apache Hudi Key Generators.
The following screenshot shows the nested partitions created in Amazon S3.

AWS Glue Data Catalog table
A Hudi table is also created in the AWS Glue Data Catalog and mapped to the Hudi datasets on Amazon S3. See the following code in the AWS Glue streaming job.

The following table provides more details on the configuration options.
| hoodie.datasource.hive_sync.enable | Indicates if the table is synced to Apache Hive Metastore. |
| hoodie.datasource.hive_sync.sync_as_datasource | Avoids breaking changes introduced with HUDI-1415 (JIRA). |
| hoodie.datasource.hive_sync.database | The database name for your Data Catalog. |
| hoodie.datasource.hive_sync.table | The table name in your Data Catalog. |
| hoodie.datasource.hive_sync.use_jdbc | Uses JDBC for Hive synchronization. For more information, see the GitHub repo. |
| hoodie.datasource.write.hive_style_partitioning | Creates partitions with <partition_column_name>=<partition_value> format. |
| hoodie.datasource.hive_sync.partition_extractor_class | Required for nested partitioning. |
| hoodie.datasource.hive_sync.partition_fields | Columns in the table to use for Hive partition columns. |
The following screenshot shows the Hudi table in the Data Catalog and the associated S3 bucket.

Read results using Athena
Using Hudi with an AWS Glue streaming job allows us to have in-place updates (upserts) on the Amazon S3 data lake. This functionality allows for incremental processing, which enables faster and more efficient downstream pipelines. Apache Hudi enables in-place updates with the following steps:
- Define an index (using columns of the ingested record).
- Use this index to map every subsequent ingestion to the record storage locations (in our case Amazon S3) ingested previously.
- Perform compaction (synchronously or asynchronously) to allow the retention of the latest record for a given index.
In reference to our AWS Glue streaming job, the following Hudi configuration options enable us to achieve in-place updates for the generated schema.

The following table provides more details of the highlighted configuration options.
| hoodie.datasource.write.recordkey.field | Indicates the column to be used within the ingested record for the Hudi index. |
| hoodie.datasource.write.operation | Defines the nature of operation on the Hudi dataset. In this example, it’s set to upsert for in-place updates. |
| hoodie.datasource.write.table.type | Indicates the Hudi storage type to be used. In this example, it’s set to COPY_ON_WRITE. |
| hoodie.datasource.write.precombine.field | When two records have the same key value, Apache Hudi picks the one with the largest value for the precombined field. |
To demonstrate an in-place update, consider the following input records sent to the AWS Glue streaming job via Kinesis Data Generator. The record identifier highlighted indicates the Hudi record key in the AWS Glue configuration. In this example, Person3 receives two updates. In first update, column_to_update_string is set to White; in the second update, it’s set to Red.

The streaming job processes these records and creates the Hudi datasets in Amazon S3. You can query the dataset using Athena. In the following example, we get the latest update.

Schema flexibility
The AWS Glue streaming job allows for automatic handling of different record schemas encountered during the ingestion. This is specifically useful in situations where record schemas can be subject to frequent changes. To elaborate on this point, consider the following scenario:
- Case 1 – At time t1, the ingested record has the layout
<col 1, col 2, col 3, col 4> - Case 2 – At time t2, the ingested record has an extra column, with new layout
<col 1, col 2, col 3, col 4, col 5> - Case 3 – At time t3, the ingested record dropped the extra column and therefore has the layout
<col 1, col 2, col 3, col 4>
For Case 1 and 2, the AWS Glue streaming job relies on the built-in schema evolution capabilities of Hudi, which enables an update to the Data Catalog with the extra column (col 5 in this case). Additionally, Hudi also adds an extra column in the output files (Parquet files written to Amazon S3). This allows for the querying engine (Athena) to query the Hudi dataset with an extra column without any issues.
Because Case 2 ingestion updates the Data Catalog, the extra column (col 5) is expected to be present in every subsequent ingested record. If we don’t resolve this difference, the job fails.
To overcome this and achieve Case 3, the streaming job defines a custom function named evolveSchema, which handles the record layout mismatches. The method queries the AWS Glue Data Catalog for each to-be-ingested record and gets the current Hudi table schema. It then merges the Hudi table schema with the schema of the to-be-ingested record and enriches the schema of the record before exposing with the Hudi dataset.

For this example, the to-be-ingested record’s schema <col 1, col 2, col 3, col 4> is modified to <col 1, col 2, col 3, col 4, col 5>, where the value of the extra col 5 is set to NULL.
To illustrate this, we stop the existing ingestion of Kinesis Data Generator and modify the record layout to send an extra column called new_column:

The Hudi table in the Data Catalog updates as follows, with the newly added column (Case 2).
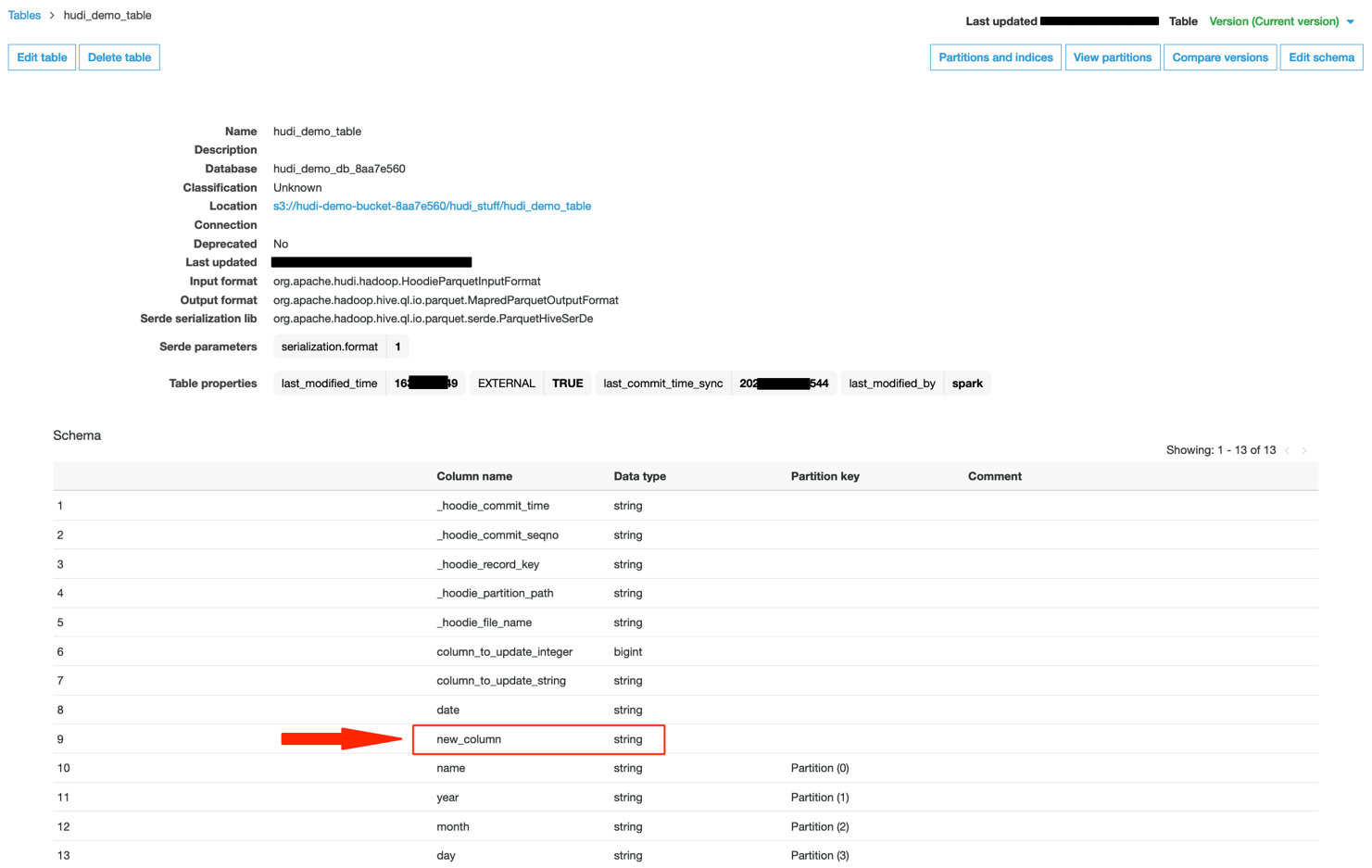
When we query the Hudi dataset using Athena, we can see the presence of a new column.

We can now use Kinesis Data Generator to send records with an old schema—without the newly added column (Case 3).
In this scenario, our AWS Glue job keeps running. When we query using Athena, the extra added column gets populated with NULL values.

If we stop Kinesis Data Generator and start sending records with a schema containing extra columns, the job keeps running and the Athena query continues to return the latest values.

Clean up
To avoid incurring future charges, delete the resources you created as part of the CloudFormation stack.
Summary
This post illustrated how to set up a serverless pipeline using an AWS Glue streaming job with the Apache Hudi Connector for AWS Glue, which runs continuously and consumes data from Kinesis Data Streams to create a near-real-time data lake that supports in-place updates, nested partitioning, and schema flexibility.
You can also use Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) as the source of a similar streaming job. We encourage you to use this approach for setting up a near-real-time data lake. As always, AWS welcomes feedback, so please leave your thoughts or questions in the comments.
About the Authors
 Nikhil Khokhar is a Solutions Architect at AWS. He joined AWS in 2016 and specializes in building and supporting data streaming solutions that help customers analyze and get value out of their data. In his free time, he makes use of his 3D printing skills to solve everyday problems.
Nikhil Khokhar is a Solutions Architect at AWS. He joined AWS in 2016 and specializes in building and supporting data streaming solutions that help customers analyze and get value out of their data. In his free time, he makes use of his 3D printing skills to solve everyday problems.
 Dipta S Bhattacharya is a Solutions Architect Manager at AWS. Dipta joined AWS in 2018. He works with large startup customers to design and develop architectures on AWS and support their journey on the cloud.
Dipta S Bhattacharya is a Solutions Architect Manager at AWS. Dipta joined AWS in 2018. He works with large startup customers to design and develop architectures on AWS and support their journey on the cloud.