AWS Big Data Blog
Query cross-account AWS Glue Data Catalogs using Amazon Athena
Many AWS customers rely on a multi-account strategy to scale their organization and better manage their data lake across different projects or lines of business. The AWS Glue Data Catalog contains references to data used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. Using a centralized Data Catalog offers organizations a unified metadata repository and minimizes the administrative overhead related to sharing data across different accounts, thereby expanding access to the data lake.
Amazon Athena is one of the popular choices to run analytical queries in data lakes. This interactive query service makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you’re charged based on the amount of data scanned by your queries.
In May 2021, Athena introduced the ability to query Data Catalogs across multiple AWS accounts, enabling you to access your data lake without the complexity of replicating catalog metadata in individual AWS accounts. This blog post details the procedure for using the feature.
Solution overview
The following diagram shows the necessary components used in two different accounts (consumer account and producer account, hosting a central Data Catalog) and the flow between the two for cross-account Data Catalog access using Athena.

Our use case showcases Data Catalog sharing between two accounts:
- Producer account – The account that administrates the central Data Catalog
- Consumer account – The account querying data from the producer’s Data Catalog (the central Data Catalog)
In this walkthrough, we use the following two tables, extracted from an ecommerce dataset:
- The orders table logs the website’s orders and contains the following key attributes:
- Row ID – Unique entry identifier in the orders table
- Order ID – Unique order identifier
- Order date – Date the order was placed
- Profit – Profit value of the order
- The returns table logs the returned items and contains the following attributes:
- Returned – If the order has been returned (Yes/No)
- Order ID – Unique order identifier
- Market – Region market
We walk you through the following high-level steps to use this solution:
- Set up the producer account.
- Set up the consumer account.
- Set up permissions.
- Register the producer account in the Data Catalog.
- Query your data.
You use Athena in the consumer account to perform different operations using the producer account’s Data Catalog.
First, you use the consumer account to query the orders table in the producer account’s Data Catalog.

Next, you use the consumer account to join the two tables and retrieve information about lost profit from returned items. The returns table is in the consumer’s Data Catalog, and the orders table is in the producer’s.

Prerequisites
The following are the prerequisites for this walkthrough:
- Two AWS accounts.
- An AWS Identity and Access Management (IAM) principal with access to AWS resources used in this solution.
- In this post, AWS Lake Formation is disabled. For cross-account access with AWS Lake Formation, please refer to the AWS documentation.
- Querying Data Catalogs across accounts only works with Athena engine V2. To check if your Athena workgroup is running on this engine, select the Workgroup tab on the left of the Athena console.

This lists all your Athena workgroups. Make sure that the one you use runs on Athena engine version 2.

If all your workgroups are using Athena engine version 1, you need to update the engine version of an existing workgroup or create a new workgroup with the appropriate version.
Set up the producer account
In the producer account, complete the following steps:
- Create an S3 bucket for your producer’s data. For information about how to secure your S3 bucket, see Security Best Practices for Amazon S3.
- In this bucket, create a prefix named
orders. - Download the orders table in CSV format and upload it to the
ordersprefix. - Run the following Athena query to create the producer’s database:
- Run the following Athena query to create the orders table in the producer’s database. Make sure to replace <your-producer-s3-bucket-name> with the name of the bucket you created.
Set up the consumer account
In the consumer account, complete the following steps:
- Create an S3 bucket for your consumer’s data.
- In this bucket, create a prefix named
returns. - Download the returns table in CSV format and upload it to the
returnsprefix. - Run the following Athena query to create the consumer’s database:
- Run the following Athena query to create the returns table in the consumer’s database. Make sure to replace <your-consumer-s3-bucket-name> with the name of the bucket you created.
Set up permissions
For the consumer account to query data in the producer account, we need to set up permissions.
First, we give the consumer account permission to access the producer account’s AWS Glue resources.
- In the producer account’s Data Catalog settings, add the following AWS Glue resource policy, which grants the consumer account access to the Data Catalog:

Next, we give the consumer account permission to list and get data from the S3 bucket in the producer account.
- In the producer account, add the following S3 bucket policy to the bucket <Producer-bucket>, which stores the data:
Register the producer account’s Data Catalog
At this stage, you have set up the required permissions to access the central Data Catalog in the producer account from the consumer account. You now need to register the central Data Catalog as a data source in Athena.
- In the consumer account, go the Athena console and choose Connect data source.
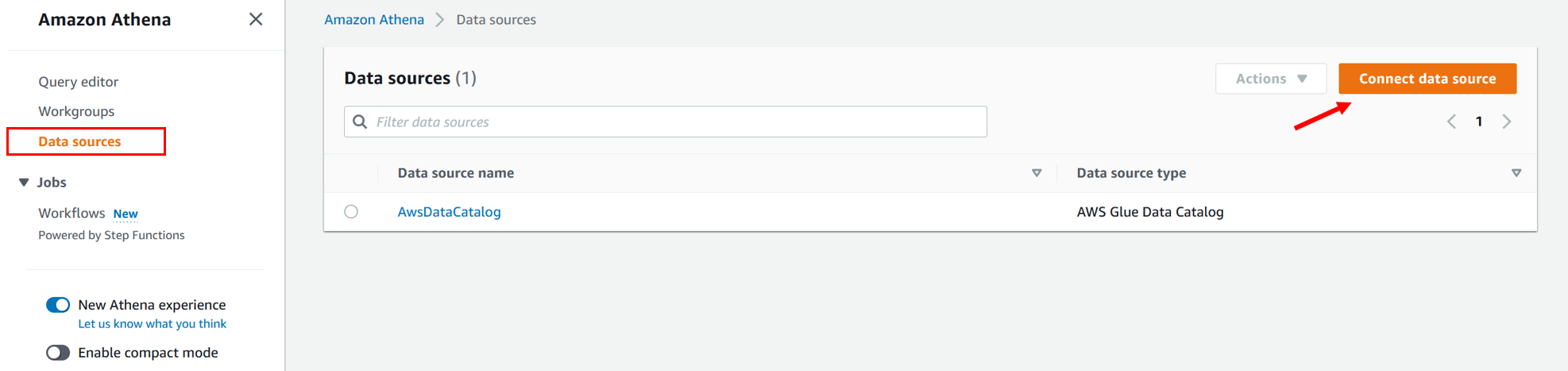
- Select S3 – AWS Glue Data Catalog as the data source selection.
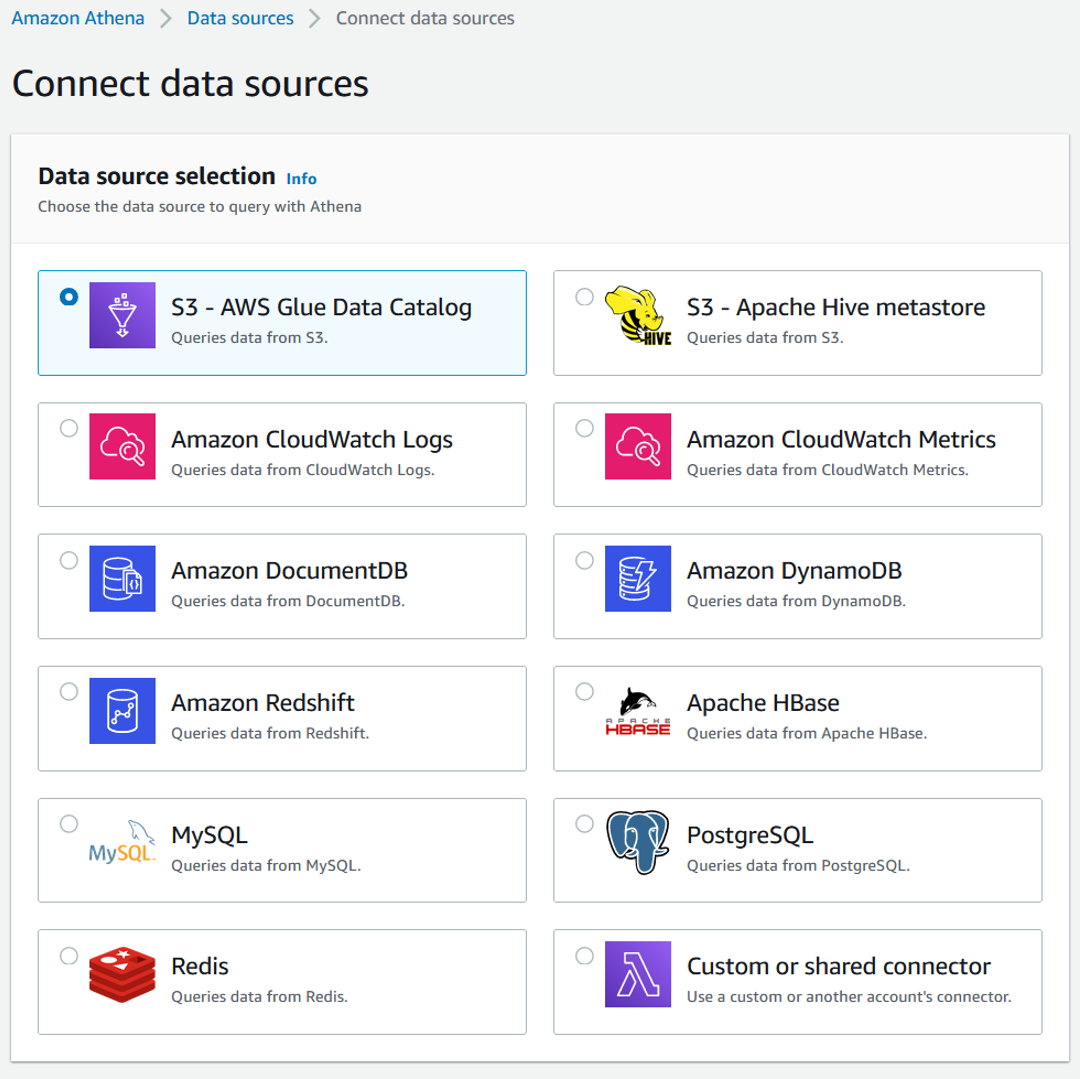
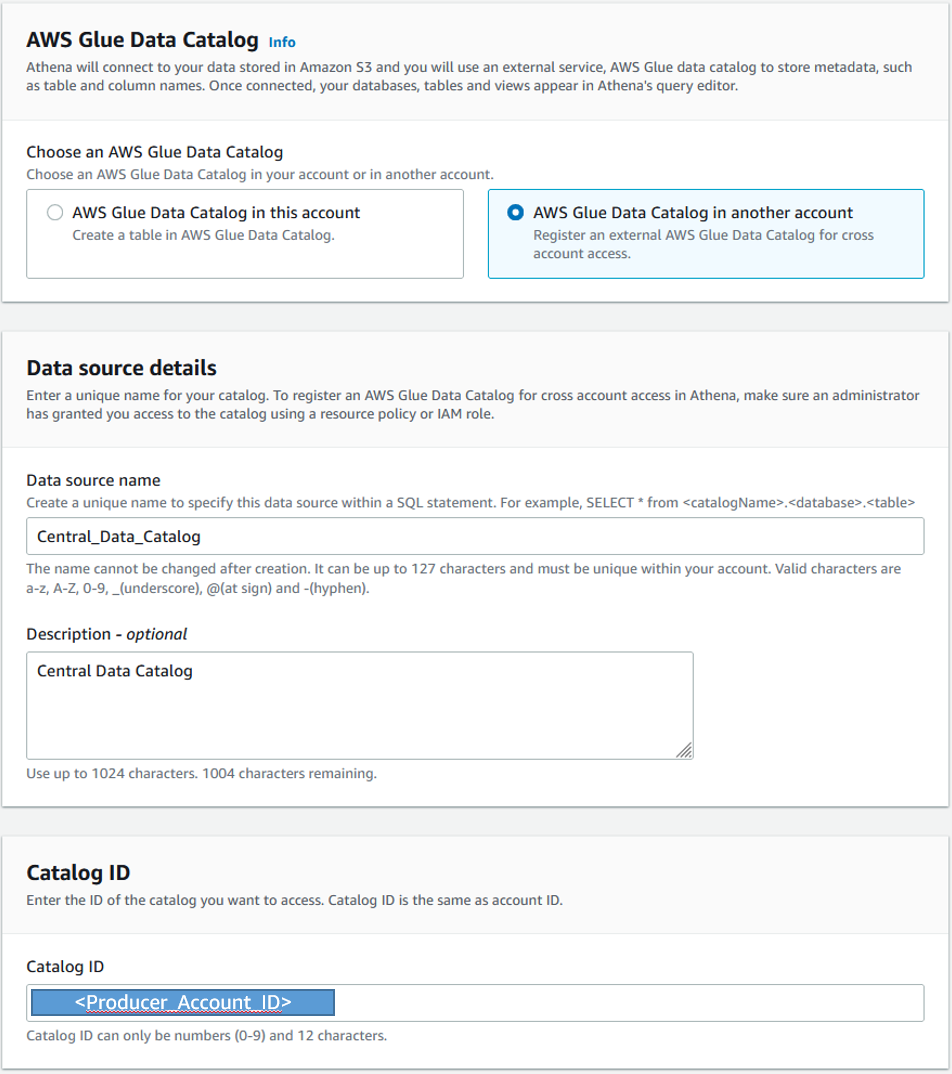
- Select AWS Glue Data Catalog in another account.
You then need to provide some information regarding the central Data Catalog you want to register.
- For Data source name, enter a name for the catalog (for example,
Central_Data_Catalog). This serves as an alias in the consumer account, pointing to the central Data Catalog in the producer account.
- For Catalog ID, enter the producer account ID.
- Choose Register to complete the process.
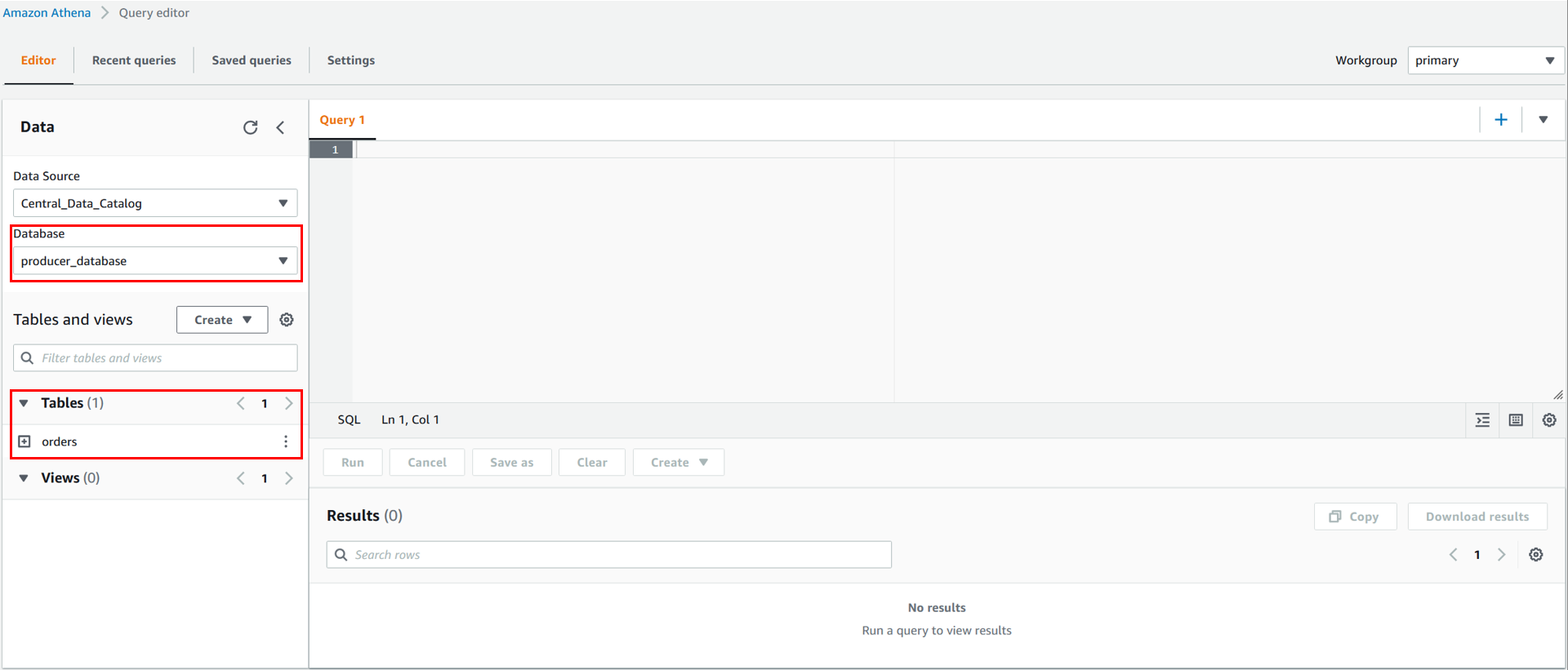
Query your data
You have now registered the central Data Catalog as a data source in the consumer account. In the Athena query editor, you can then choose Central_Data_Catalog as a data source. Under Database, you can see all the databases for which you were granted access in the producer account’s AWS Glue resource policy. The same applies for the tables. After completing the steps in the earlier sections, you should see the orders table from producer_database located in the producer account.
You can start querying the Data Catalog of the producer account directly from Athena in the consumer account. You can test this by running the following SQL query in Athena:
This SQL query extracts the first 10 rows of the orders table located in the producer account.
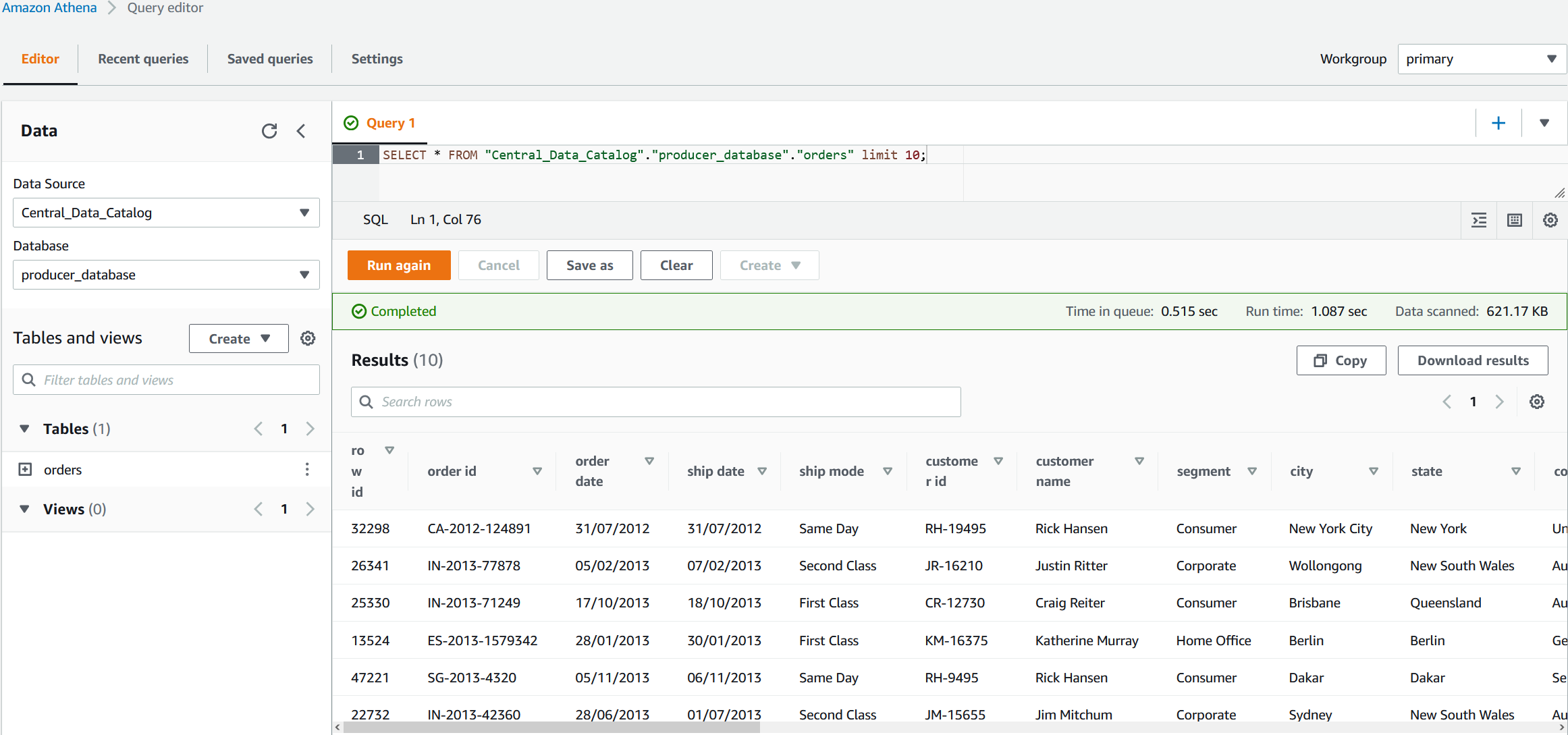
You just queried a Data Catalog located in another AWS account, which enables you to easily access your central Data Catalog and scale your data lake strategy.
Now, let’s see how we can join two tables that are in different AWS accounts. In our scenario, the returns table is in the consumer account and the orders table is in the producer account. Suppose you want to join the two tables and see the total amount of items returned in each market. The Athena built-in support for cross-account Data Catalogs makes this operation easy. In the Athena query editor, run the following SQL query:
In this SQL query, you use both the consumer’s Data Catalog AwsDataCatalog and the producer’s Data Catalog Central_Data_Catalog to join tables and get insights from your data.
Limitations and considerations
The following are some limitations that you should take into consideration before using Athena built-in support for cross-account Data Catalogs:
- This Athena feature is available only in Regions where Athena engine version 2 is supported. For a list of Regions that support Athena engine version 2, see Athena engine version 2. To upgrade a workgroup to engine version 2, see Changing Athena Engine Versions.
- As of this writing, CREATE VIEW statements that include a cross-account Data Catalog are not supported.
- Cross-Region Data Catalog queries are not supported.
Clean up
After you query and analyze the data, you should clean up the resources used in this tutorial to prevent any recurring AWS costs.
To clean up the resources, navigate to the Amazon S3 console in both the provider and consumer accounts, and empty the S3 buckets. Also, navigate to the AWS Glue console and delete the databases.
Conclusion
In this post, you learned how to query data from multiple accounts using Athena, which allows your organization to access to a centralized Data Catalog. We hope that this post helps you build and explore your data lake across multiple accounts.
To learn more about AWS tools to manage access to your data, check out AWS Lake Formation. This service facilitates setting up a centralized data lake and allows you to grant users and ETL jobs cross-account access to Data Catalog metadata and underlying data.
About the Authors
 Louis Hourcade is a Data Scientist in the AWS Professional Services team. He works with AWS customer across various industries to accelerate their business outcomes with innovative technologies. In his spare time he enjoys running, climbing big rocks, and surfing (not so big) waves.
Louis Hourcade is a Data Scientist in the AWS Professional Services team. He works with AWS customer across various industries to accelerate their business outcomes with innovative technologies. In his spare time he enjoys running, climbing big rocks, and surfing (not so big) waves.
 Sara Kazdagli is a Professional Services consultant specialized in data analytics and machine learning. She helps customers across different industries build innovative solutions and make data-driven decisions. Sara holds a MSc in Software engineering and a MSc in data science. In her spare time, she likes to go on hikes and walks with her australian shepherd dog Kiba.
Sara Kazdagli is a Professional Services consultant specialized in data analytics and machine learning. She helps customers across different industries build innovative solutions and make data-driven decisions. Sara holds a MSc in Software engineering and a MSc in data science. In her spare time, she likes to go on hikes and walks with her australian shepherd dog Kiba.
 Jahed Zaïdi is an AI/ML & Big Data specialist at AWS Professional Services. He is a builder and a trusted advisor to companies across industries, helping them innovate faster and on a larger scale. As a lifelong explorer, Jahed enjoys discovering new places, cultures, and outdoor activities.
Jahed Zaïdi is an AI/ML & Big Data specialist at AWS Professional Services. He is a builder and a trusted advisor to companies across industries, helping them innovate faster and on a larger scale. As a lifelong explorer, Jahed enjoys discovering new places, cultures, and outdoor activities.