AWS Big Data Blog
Handle fast-changing reference data in an AWS Glue streaming ETL job
Streaming ETL jobs in AWS Glue can consume data from streaming sources such as Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, as well as continuously load the results into Amazon Simple Storage Service (Amazon S3) data lakes, data warehouses, or other data stores.
The always-on nature of streaming jobs poses a unique challenge when handling fast-changing reference data that is used to enrich data streams within the AWS Glue streaming ETL job. AWS Glue processes real-time data from Amazon Kinesis Data Streams using micro-batches. The foreachbatch method used to process micro-batches handles one data stream.
This post proposes a solution to enrich streaming data with frequently changing reference data in an AWS Glue streaming ETL job.
You can enrich data streams with changing reference data in the following ways:
- Read the reference dataset with every micro-batch, which can cause redundant reads and an increase in read requests. This approach is expensive, inefficient, and isn’t covered in this post.
- Design a method to tell the AWS Glue streaming job that the reference data has changed and refresh it only when needed. This approach is cost-effective and highly available. We recommend using this approach.
Solution overview
This post uses DynamoDB Streams to capture changes to reference data, as illustrated in the following architecture diagram. For more information about DynamoDB Streams, see DynamoDB Streams Use Cases and Design Patterns.

The workflow contains the following steps:
- A user or application updates or creates a new item in the DynamoDB table.
- DynamoDB Streams is used to identify changes in the reference data.
- A Lambda function is invoked every time a change occurs in the reference data.
- The Lambda function captures the event containing the changed record, creates a “change file” and places it in an Amazon S3 bucket.
- The AWS Glue job is designed to monitor the stream for this value in every micro-batch. The moment that it sees the change flag, AWS Glue initiates a refresh of the DynamoDB data before processing any further records in the stream.
This post is accompanied by an AWS CloudFormation template that creates resources as described in the solution architecture:
- A DynamoDB table named
ProductPrioritywith a few items loaded - An S3 bucket named
demo-bucket-<AWS AccountID> - Two Lambda functions:
demo-glue-script-creator-lambdademo-reference-data-change-handler
- A Kinesis data stream named
SourceKinesisStream - An AWS Glue Data Catalog database called
my-database - Two Data Catalog tables
- An AWS Glue job called
demo-glue-job-<AWS AccountID>. The code for the AWS Glue job can be found at this link. - Two AWS Identity and Access Management (IAM) roles:
- A role for the Lambda functions to access Kinesis, Amazon S3, and DynamoDB Streams
- A role for the AWS Glue job to access Kinesis, Amazon S3, and DynamoDB
- An Amazon Kinesis Data Generator (KDG) account with a user created through Amazon Cognito to generate a sample data stream
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- The IAM user should have permissions to create the required roles
- Permission to create a CloudFormation stack and the services we detailed
Create resources with AWS CloudFormation
To deploy the solution, complete the following steps:
- Choose Launch Stack:

- Set up an Amazon Cognito user pool and test if you can access the KDG URL specified in the stack’s output tab. Furthermore, validate if you can log in to KDG using the credentials provided while creating the stack.
You should now have the required resources available in your AWS account.
- Verify this list with the resources in the output section of the CloudFormation stack.
Sample data
Sample reference data has already been loaded into the reference data store. The following screenshot shows an example.
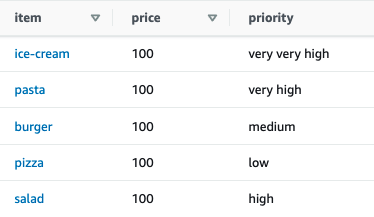
The priority value may change frequently based on the time of the day, the day of the week, or other factors that drive demand and supply.
The objective is to accommodate these changes to the reference data seamlessly into the pipeline.
Generate a randomized stream of events into Kinesis
Next, we simulate a sample stream of data into Kinesis. For detailed instructions, see Test Your Streaming Data Solution with the New Amazon Kinesis Data Generator. For this post, we define the structure of the simulated orders data using a parameterized template.
- On the KDG console, choose the Region where the source Kinesis stream is located.
- Choose your delivery stream.
- Enter the following template into the Record template field:
- Choose Test template, then choose Send data.

KDG should start sending a stream of randomly generated orders to the Kinesis data stream.
Run the AWS Glue streaming job
The CloudFormation stack created an AWS Glue job that reads from the Kinesis data stream through a Data Catalog table, joins with the reference data in DynamoDB, and writes the result to an S3 bucket. To run the job, complete the following steps:
- On the AWS Glue console, under ETL in the navigation pane, choose Jobs.
- Select the job
demo-glue-job-<AWS AccountID>. - On the Actions menu, choose Run job.
In addition to the enrichment, the job includes an additional check that monitors an Amazon S3 prefix for a “Change Flag” file. This file is created by the Lambda function, which is invoked by the DynamoDB stream whenever there is an update or a new reference item.
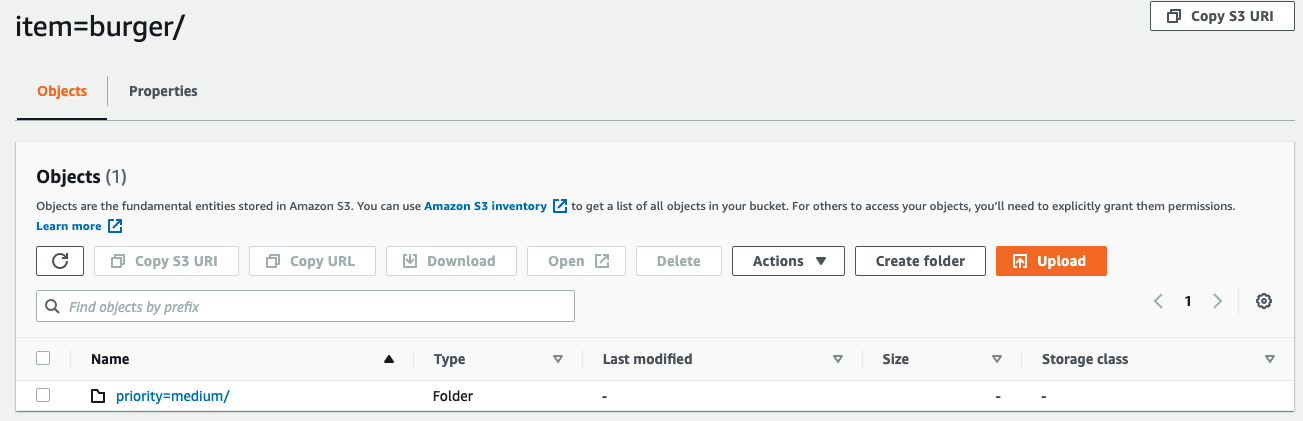
Investigate the target data in Amazon S3
The following is a screenshot of the data being loaded in real time into the item=burger partition. The priority was set to medium in the reference data, and the orders go into the corresponding partition.
Update the reference data
Now we update the priority for burgers to high in the DynamoDB table through the console while the orders are streaming into the pipeline.
Use the following command to perform the update through Amazon CloudShell. Change the Region to the appropriate value.
Verify that the data got updated.

Navigate to the target S3 folder to confirm the contents. The AWS Glue job should have started sending the orders for burgers into the high partition.
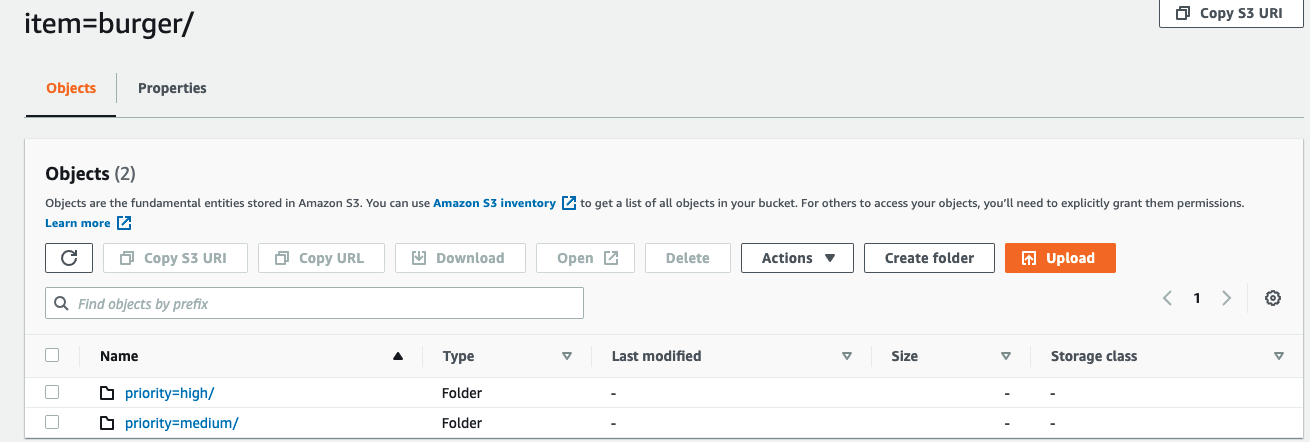
The Lambda function is invoked by the DynamoDB stream and places a “Change Flag” file in an Amazon S3 bucket. The AWS Glue job refreshes the reference data and deletes the file to avoid redundant refreshes.
Using this pattern for reference data in Amazon S3
If the reference data is stored in an S3 bucket, create an Amazon S3 event notification that identifies changes to the prefix where the reference data is stored. The event notification invokes a Lambda function that inserts the change flag into the data stream.
Cleaning up
To avoid incurring future charges, delete the resources. You can do this by deleting the CloudFormation stack.
Conclusion
In this post, we discussed approaches to handle fast-changing reference data stored in DynamoDB or Amazon S3. We demonstrated a simple use case that implements this pattern.
Note that DynamoDB Streams writes stream records in near-real time. When designing your solution, account for a minor delay between the actual update in DynamoDB and the write into the DynamoDB stream.
About the Authors
 Jerome Rajan is a Lead Data Analytics Consultant at AWS. He helps customers design & build scalable analytics solutions and migrate data pipelines and data warehouses into the cloud. In an alternate universe, he is a World Chess Champion!
Jerome Rajan is a Lead Data Analytics Consultant at AWS. He helps customers design & build scalable analytics solutions and migrate data pipelines and data warehouses into the cloud. In an alternate universe, he is a World Chess Champion!
 Dipankar Ghosal is a Principal Architect at Amazon Web Services and is based out of Minneapolis, MN. He has a focus in analytics and enjoys helping customers solve their unique use cases. When he’s not working, he loves going hiking with his wife and daughter.
Dipankar Ghosal is a Principal Architect at Amazon Web Services and is based out of Minneapolis, MN. He has a focus in analytics and enjoys helping customers solve their unique use cases. When he’s not working, he loves going hiking with his wife and daughter.