AWS Big Data Blog
Category: AWS Glue
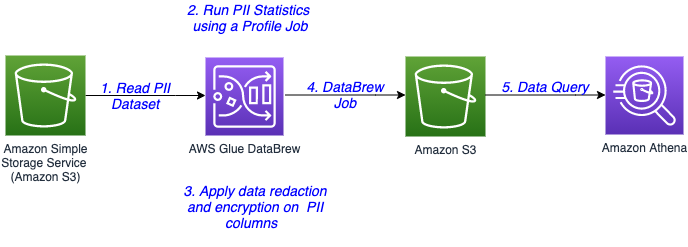
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]

Improve Amazon Athena query performance using AWS Glue Data Catalog partition indexes
The AWS Glue Data Catalog provides partition indexes to accelerate queries on highly partitioned tables. In the post Improve query performance using AWS Glue partition indexes, we demonstrated how partition indexes reduce the time it takes to fetch partition information during the planning phase of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS […]
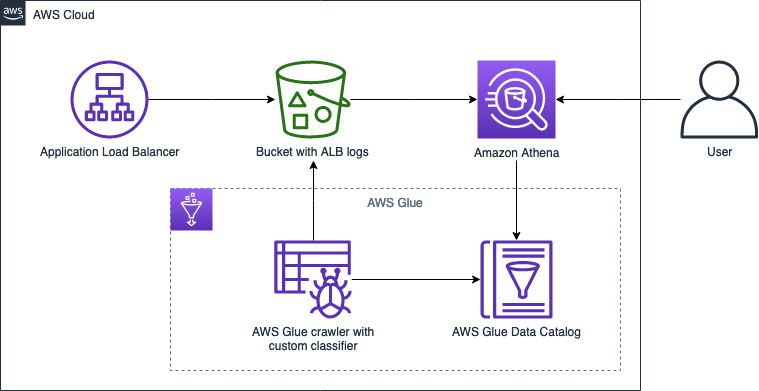
Catalog and analyze Application Load Balancer logs more efficiently with AWS Glue custom classifiers and Amazon Athena
You can query Application Load Balancer (ALB) access logs for various purposes, such as analyzing traffic distribution and patterns. You can also easily use Amazon Athena to create a table and query against the ALB access logs on Amazon Simple Storage Service (Amazon S3). (For more information, see How do I analyze my Application Load […]
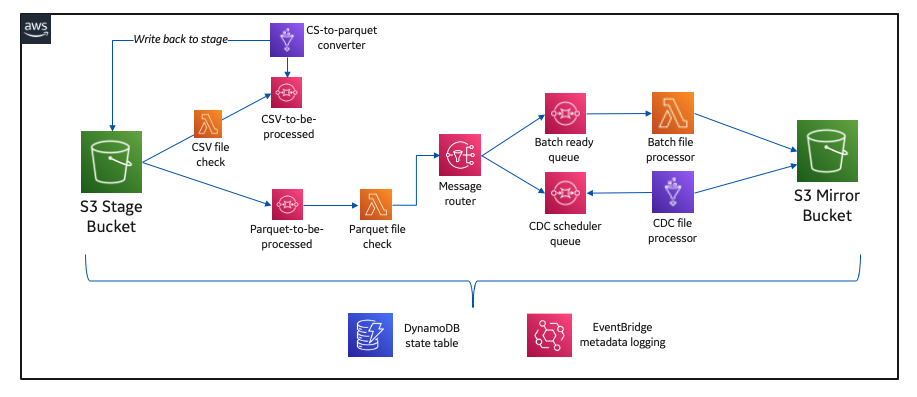
How GE Aviation built cloud-native data pipelines at enterprise scale using the AWS platform
This post was co-written with Alcuin Weidus, Principal Architect from GE Aviation. GE Aviation, an operating unit of GE, is a world-leading provider of jet and turboprop engines, as well as integrated systems for commercial, military, business, and general aviation aircraft. GE Aviation has a global service network to support these offerings. From the turbosupercharger […]
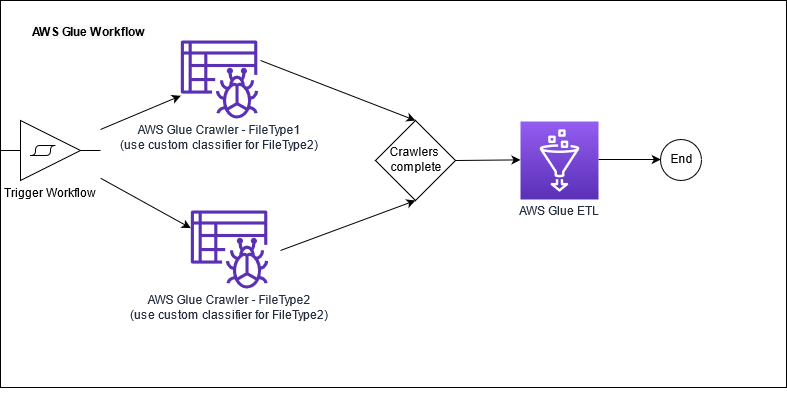
Orchestrate an ETL pipeline using AWS Glue workflows, triggers, and crawlers with custom classifiers
Extract, transform, and load (ETL) orchestration is a common mechanism for building big data pipelines. Orchestration for parallel ETL processing requires the use of multiple tools to perform a variety of operations. To simplify the orchestration, you can use AWS Glue workflows. This post demonstrates how to accomplish parallel ETL orchestration using AWS Glue workflows […]

Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]

Introducing Amazon S3 shuffle in AWS Glue
Nov 2022: Newer version of the product is now available to be used for this post. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. In AWS Glue, you can use Apache Spark, which is an open-source, distributed processing […]

Now Available: Updated guidance on the Data Analytics Lens for AWS Well-Architected Framework
Nearly all businesses today require some form of data analytics processing, from auditing user access to generating sales reports. For all your analytics needs, the Data Analytics Lens for AWS Well-Architected Framework provides prescriptive guidance to help you assess your workloads and identify best practices aligned to the AWS Well-Architected Pillars: Operational Excellence, Security, Reliability, […]

Accelerate large-scale data migration validation using PyDeequ
March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on DeeQu and it offers a simplified user experience for customers who want to this open-source package. Refer to the blog and documentation for additional details. Many enterprises are migrating their […]

Stream data from relational databases to Amazon Redshift with upserts using AWS Glue streaming jobs
Traditionally, read replicas of relational databases are often used as a data source for non-online transactions of web applications such as reporting, business analysis, ad hoc queries, operational excellence, and customer services. Due to the exponential growth of data volume, it became common practice to replace such read replicas with data warehouses or data lakes […]