AWS Big Data Blog
Category: AWS Lake Formation
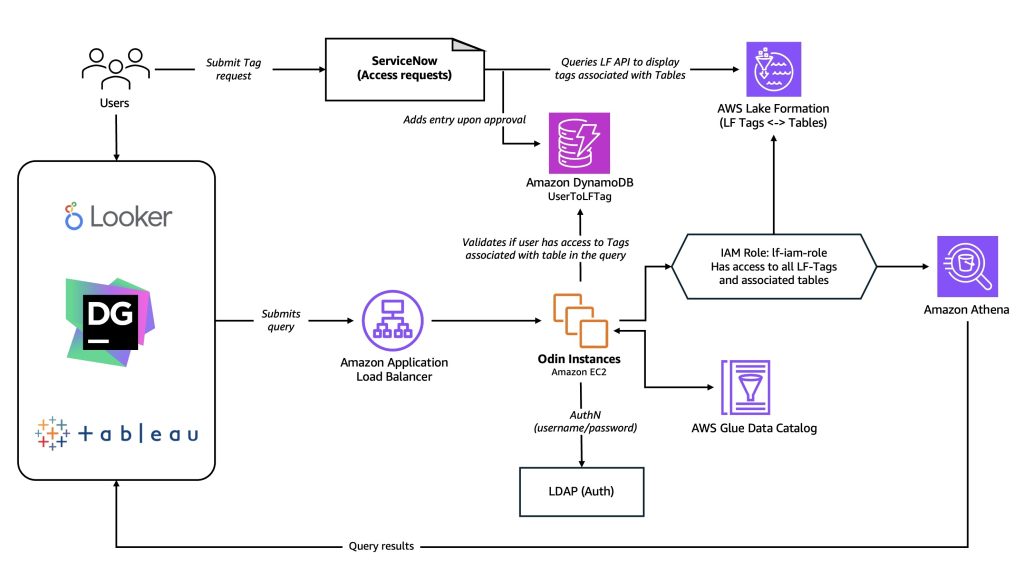
How Twilio secured their multi-engine query platform with AWS Lake Formation
Twilio is a cloud communications platform that provides programmable APIs and tools for developers to easily integrate voice, messaging, email, video, and other communication features into their applications and customer engagement workflows. In this blog series we discuss how we built a multi-engine query platform at Twilio. The first part introduces the use case that led us to build a new platform and why we selected Amazon Athena alongside our open-source Presto implementation. This second part discusses how Twilio’s query infrastructure platform integrates with AWS Lake Formation to provide fine-grained access control to all their data.

Implement a data mesh pattern in Amazon SageMaker Catalog without changing applications
In this post, we walk through simulating a scenario based on data producer and data consumer that exists before Amazon SageMaker Catalog adoption. We use a sample dataset to simulate existing data and an existing application using an AWS Lambda function, then implement a data mesh pattern using Amazon SageMaker Catalog while keeping your current data repositories and consumer applications unchanged.
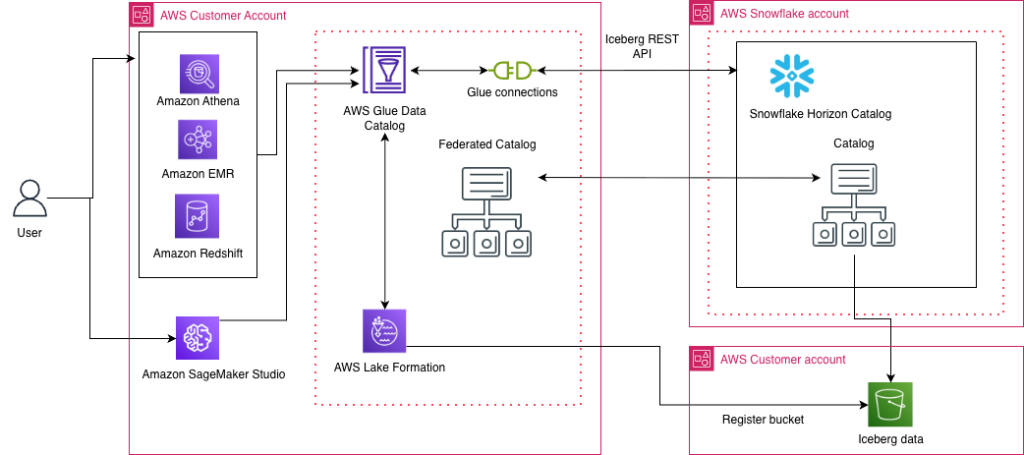
Access Snowflake Horizon Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has introduced a new catalog federation feature that enables direct access to Snowflake Horizon Catalog data through AWS Glue Data Catalog. This integration allows organizations to discover and query data in Iceberg format while maintaining security through AWS Lake Formation. This post provides a step-by-step guide to establishing this integration, including configuring Snowflake Horizon Catalog, setting up authentication, creating necessary IAM roles, and implementing AWS Lake Formation permissions. Learn how to enable cross-platform analytics while maintaining robust security and governance across your data environment.
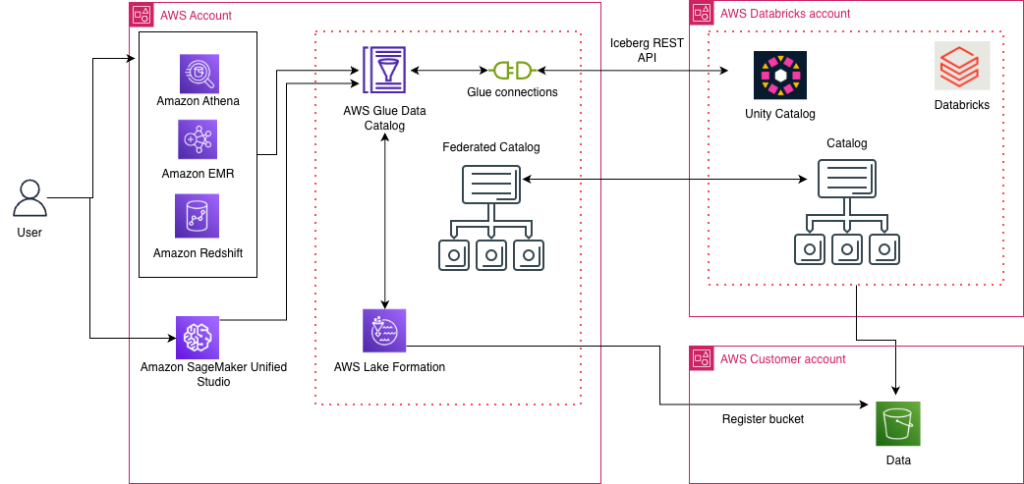
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]
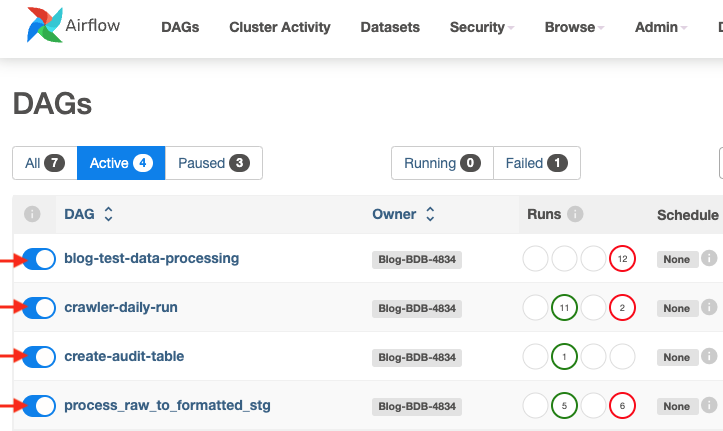
Building scalable AWS Lake Formation governed data lakes with dbt and Amazon Managed Workflows for Apache Airflow
Organizations often struggle with building scalable and maintainable data lakes—especially when handling complex data transformations, enforcing data quality, and monitoring compliance with established governance. Traditional approaches typically involve custom scripts and disparate tools, which can increase operational overhead and complicate access control. A scalable, integrated approach is needed to simplify these processes, improve data reliability, […]

Introducing catalog federation for Apache Iceberg tables in the AWS Glue Data Catalog
AWS Glue now supports catalog federation for remote Iceberg tables in the Data Catalog. With catalog federation, you can query remote Iceberg tables, stored in Amazon S3 and cataloged in remote Iceberg catalogs, using AWS analytics engines and without moving or duplicating tables. In this post, we discuss how to get started with catalog federation for Iceberg tables in the Data Catalog.

Implement fine-grained access control for Iceberg tables using Amazon EMR on EKS integrated with AWS Lake Formation
On February 6th 2025, AWS introduced fine-grained access control based on AWS Lake Formation for EMR on EKS from Amazon EMR 7.7 and higher version. You can now significantly enhance your data governance and security frameworks using this feature. In this post, we demonstrate how to implement FGAC on Apache Iceberg tables using EMR on EKS with Lake Formation.

Break down data silos and seamlessly query Iceberg tables in Amazon SageMaker from Snowflake
This blog post discusses how to create a seamless integration between Amazon SageMaker Lakehouse and Snowflake for modern data analytics. It specifically demonstrates how organizations can enable Snowflake to access tables in AWS Glue Data Catalog (stored in S3 buckets) through SageMaker Lakehouse Iceberg REST Catalog, with security managed by AWS Lake Formation. The post provides a detailed technical walkthrough of implementing this integration, including creating IAM roles and policies, configuring Lake Formation access controls, setting up catalog integration in Snowflake, and managing data access permissions. While four different patterns exist for accessing Iceberg tables from Snowflake, the blog focuses on the first pattern using catalog integration with SigV4 authentication and Lake Formation credential vending.

The Amazon SageMaker lakehouse architecture now automates optimization configuration of Apache Iceberg tables on Amazon S3
The Amazon SageMaker lakehouse architecture now automates optimization of Iceberg tables stored in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and improving query performance. This post demonstrates an end-to-end flow to enable catalog level table optimization setting.