AWS Big Data Blog
Category: Analytics

Accelerate AWS Glue zero-ETL data ingestion using Salesforce Bulk API
AWS Glue zero-ETL (extract, transform, and load) now supports Salesforce Bulk API, delivering substantial performance gains compared to Salesforce REST API for large-scale data integration for targets such as Amazon SageMaker lakehouse and Amazon Redshift. In this blog post, we show you how to use zero-ETL powered by AWS Glue with Salesforce Bulk API to accelerate your data integration processes.

Achieve full control over your data encryption using customer managed keys in Amazon Managed Service for Apache Flink
Encryption of both data at rest and in transit is a non-negotiable feature for most organizations. Furthermore, organizations operating in highly regulated and security-sensitive environments—such as those in the financial sector—often require full control over the cryptographic keys used for their workloads. Amazon Managed Service for Apache Flink makes it straightforward to process real-time data […]

Deep dive into the Amazon Managed Service for Apache Flink application lifecycle – Part 2
In Part 1 of this series, we discussed fundamental operations to control the lifecycle of your Amazon Managed Service for Apache Flink application. In this post, we explore failure scenarios that can happen during normal operations or when you deploy a change or scale the application, and how to monitor operations to detect and recover when something goes wrong.

Deep dive into the Amazon Managed Service for Apache Flink application lifecycle – Part 1
In this two-part series, we explore what happens during an application’s lifecycle. This post covers core concepts and the application workflow during normal operations. In Part 2, we look at potential failures, how to detect them through monitoring, and ways to quickly resolve issues when they occur.

Use account-agnostic, reusable project profiles in Amazon SageMaker to streamline governance
Amazon SageMaker now supports account-agnostic project profiles, so you can create reusable project templates across multiple AWS accounts and organizational units. In this post, we demonstrate how account-agnostic project profiles can help you simplify and streamline the management of SageMaker project creation while maintaining security and governance features. We walk through the technical steps to configure account-agnostic, reusable project profiles, helping you maximize the flexibility of your SageMaker deployments.

Deploy Apache YuniKorn batch scheduler for Amazon EMR on EKS
This post explores Kubernetes scheduling fundamentals, examines the limitations of the default kube-scheduler for batch workloads, and demonstrates how YuniKorn addresses these challenges. We discuss how to deploy YuniKorn as a custom scheduler for Amazon EMR on EKS, its integration with job submissions, how to configure queues and placement rules, and how to establish resource quotas. We also show these features in action through practical Spark job examples.
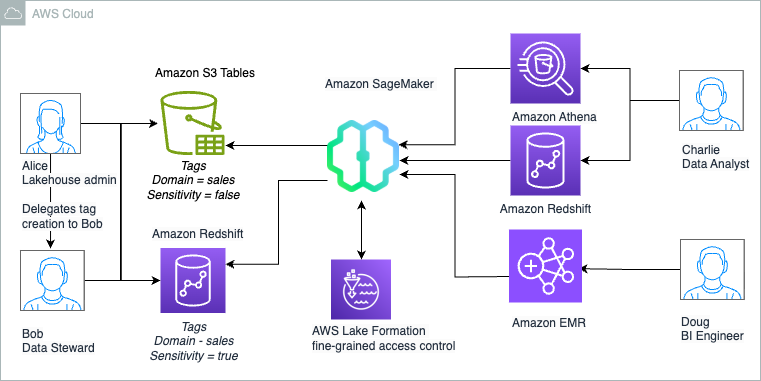
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Modernize Amazon Redshift authentication by migrating user management to AWS IAM Identity Center
Amazon Redshift is a powerful cloud-based data warehouse that organizations can use to analyze both structured and semi-structured data through advanced SQL queries. As a fully managed service, it provides high performance and scalability while allowing secure access to the data stored in the data warehouse. Organizations worldwide rely on Amazon Redshift to handle massive […]

Implement fine-grained access control using Amazon OpenSearch Service and JSON Web Tokens
This post demonstrates how to build a secure search application using Amazon OpenSearch Service and JSON Web Tokens (JWTs). We discuss the basics of OpenSearch Service and JWTs and how to implement user authentication and authorization through an existing identity provider (IdP). The focus is on enforcing fine-grained access control based on user roles and permissions.

How Ancestry optimizes a 100-billion-row Iceberg table
This is a guest post by Thomas Cardenas, Staff Software Engineer at Ancestry, in partnership with AWS. Ancestry, the global leader in family history and consumer genomics, uses family trees, historical records, and DNA to help people on their journeys of personal discovery. Ancestry has the largest collection of family history records, consisting of 40 […]