AWS Big Data Blog
Category: Generative AI
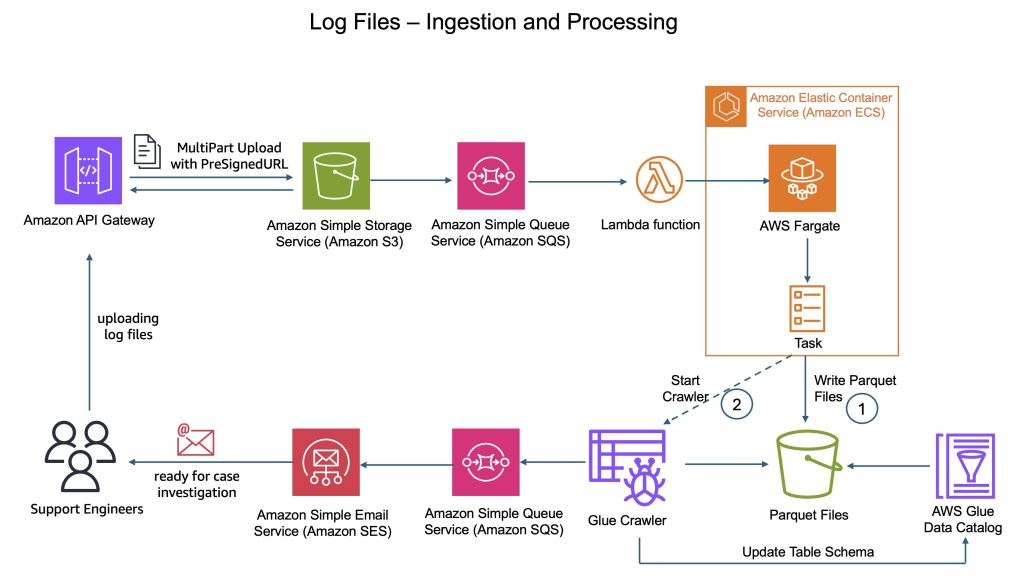
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.

Unifying metadata governance across Amazon SageMaker and Collibra
Amazon Web Services (AWS) and Collibra have built a new integrated solution that demonstrates the integration between the Collibra Platform and the next generation of Amazon SageMaker. In this post, we take a closer look at the integration, describe the use cases it enables, walk through the architecture, and show how to implement the solution in your environment.

Build conversational AI search with Amazon OpenSearch Service
Amazon OpenSearch Service is a versatile search and analytics tool. In this post, we explore conversational search, its architecture, and various ways to implement it.

Empower financial analytics by creating structured knowledge bases using Amazon Bedrock and Amazon Redshift
In this post, we showcase how financial planners, advisors, or bankers can now ask questions in natural language. These prompts will receive precise data from the customer databases for accounts, investments, loans, and transactions. Amazon Bedrock Knowledge Bases automatically translates these natural language queries into optimized SQL statements, thereby accelerating time to insight, enabling faster discoveries and efficient decision-making.

Amazon OpenSearch Service vector database capabilities revisited
As we enter 2025, OpenSearch Service support for OpenSearch 2.17 brings these improvements to the service. In this post, we walk through 2024’s innovations with an eye to how you can adopt new features to lower your cost, reduce your latency, and improve the accuracy of your search results and generated text.

Cost Optimized Vector Database: Introduction to Amazon OpenSearch Service quantization techniques
This blog post introduces a new disk-based vector search approach that allows efficient querying of vectors stored on disk without loading them entirely into memory. By implementing these quantization methods, organizations can achieve compression ratios of up to 64x, enabling cost-effective scaling of vector databases for large-scale AI and machine learning applications.

Recap of Amazon Redshift key product announcements in 2024
Amazon Redshift made significant strides in 2024, that enhanced price-performance, enabled data lakehouse architectures by blurring the boundaries between data lakes and data warehouses, simplified ingestion and accelerated near real-time analytics, and incorporated generative AI capabilities to build natural language-based applications and boost user productivity. This blog post provides a comprehensive overview of the major product innovations and enhancements made to Amazon Redshift in 2024.

Introducing generative AI troubleshooting for Apache Spark in AWS Glue (preview)
This post demonstrates how generative AI troubleshooting for Spark in AWS Glue helps your day-to-day Spark application debugging. It simplifies the debugging process for your Spark applications by using generative AI to automatically identify the root cause of failures and provides actionable recommendations to resolve the issues.

Introducing generative AI upgrades for Apache Spark in AWS Glue (preview)
Today, we are excited to announce the preview of generative AI upgrades for Spark, a new capability that enables data practitioners to quickly upgrade and modernize their Spark applications running on AWS. Starting with Spark jobs in AWS Glue, this feature allows you to upgrade from an older AWS Glue version to AWS Glue version 4.0. This new capability reduces the time data engineers spend on modernizing their Spark applications, allowing them to focus on building new data pipelines and getting valuable analytics faster.

Enrich your AWS Glue Data Catalog with generative AI metadata using Amazon Bedrock
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.