AWS Big Data Blog
Category: AWS Big Data

Improve query performance using AWS Glue partition indexes
While creating data lakes on the cloud, the data catalog is crucial to centralize metadata and make the data visible, searchable, and queryable for users. With the recent exponential growth of data volume, it becomes much more important to optimize data layout and maintain the metadata on cloud storage to keep the value of data […]

Build a data quality score card using AWS Glue DataBrew, Amazon Athena, and Amazon QuickSight
Data quality plays an important role while building an extract, transform, and load (ETL) pipeline for sending data to downstream analytical applications and machine learning (ML) models. The analogy “garbage in, garbage out” is apt at describing why it’s important to filter out bad data before further processing. Continuously monitoring data quality and comparing it […]

Simplify incoming data ingestion with dynamic parameterized datasets in AWS Glue DataBrew
When data analysts and data scientists prepare data for analysis, they often rely on periodically generated data produced by upstream services, such as labeling datasets from Amazon SageMaker Ground Truth or Cost and Usage Reports from AWS Billing and Cost Management. Alternatively, they can regularly upload such data to Amazon Simple Storage Service (Amazon S3) […]

Set up CI/CD pipelines for AWS Glue DataBrew using AWS Developer Tools
An integral part of DevOps is adopting the culture of continuous integration and continuous delivery (CI/CD). This enables teams to securely store and version code, maintain parity between development and production environments, and achieve end-to-end automation of the release cycle, including building, testing, and deploying to production. In essence, development teams follow CI/CD processes to […]

How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform
April 2024: This post was reviewed for accuracy. This is a joint blog post co-authored with Anu Jain, Graham Person, and Paul Conroy from JP Morgan Chase. Most modern organizations recognize that their data benefits their entire enterprise. Data has value to the individual business process that produces it, but data’s additional potential can be […]
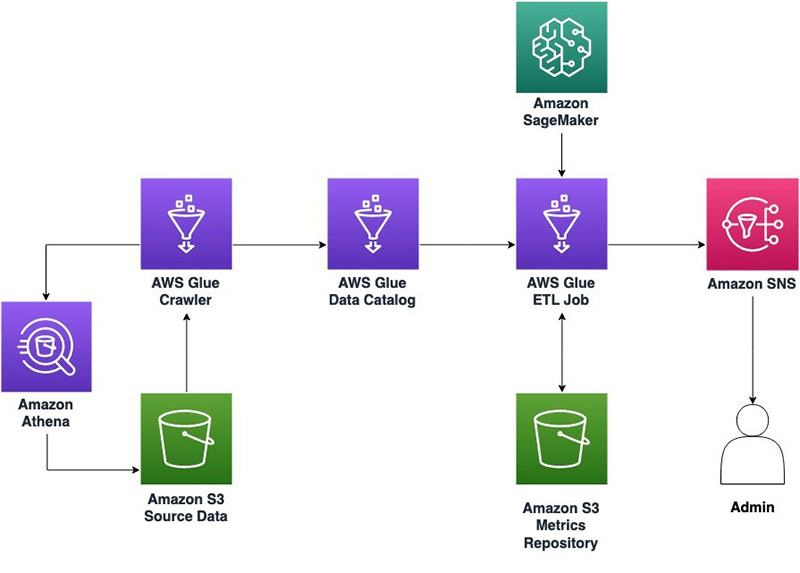
Monitor data quality in your data lake using PyDeequ and AWS Glue
August 2024: This post was reviewed and updated with examples against a new dataset. Additionally, changed the architecture to use AWS Glue Studio Notebooks and added information on the appropriate Deequ/PyDeequ versions. In our previous post, we introduced PyDeequ, an open-source Python wrapper over Deequ, which enables you to write unit tests on your data […]

Use Grok patterns in AWS Glue to process streaming data into Amazon Elasticsearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Recently, we launched AWS Glue custom connectors for Amazon OpenSearch Service, which provides the capability to ingest data into Amazon OpenSearch Service with just a few clicks. You can now use Amazon OpenSearch Service as a data store for your […]
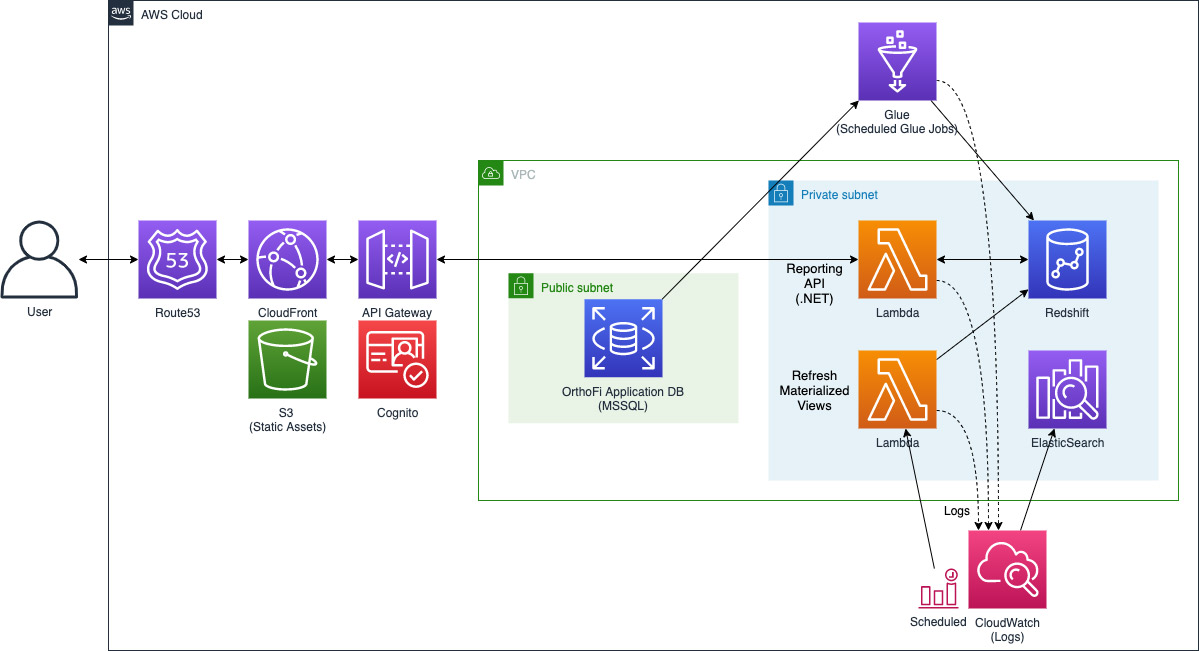
How OrthoFi delivers better insights for customers with Amazon Redshift and AWS Glue
This is a guest post by Christa Pierson and Jon Fearer at OrthoFi. OrthoFi is an orthodontic industry leader in revenue cycle management (RCM), and has partnered with more than 550 orthodontic practices across the country, delivering an end-to-end platform that enables orthodontists to bring on more patients and run their businesses more effectively. To […]

Analyzing petabytes of trade and quote data with Amazon FinSpace
We recently announced Amazon FinSpace, a fully-managed data management and analytics service that makes it easy to store, catalog, and prepare financial industry data at scale, reducing the time it takes for financial services industry (FSI) customers to find and access all types of financial data for analysis from months to minutes. Financial services organizations […]

Orchestrate AWS Glue DataBrew jobs using Amazon Managed Workflows for Apache Airflow
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Analysts are building complex data transformation pipelines that include multiple steps for data preparation and cleansing. However, analysts may want a simpler orchestration mechanism with a graphical user interface that […]