AWS Big Data Blog
Category: Amazon Elastic Kubernetes Service
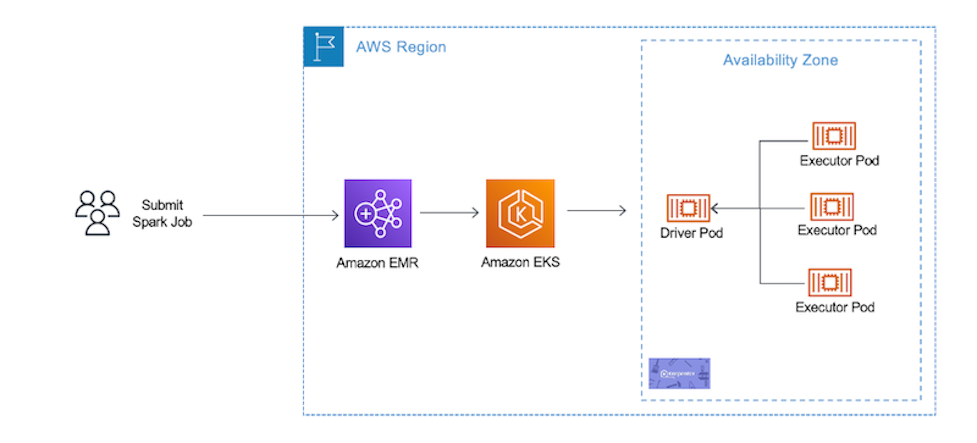
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]

How SailPoint solved scaling issues by migrating legacy big data applications to Amazon EMR on Amazon EKS
This post is co-written with Richard Li from SailPoint. SailPoint Technologies is an identity security company based in Austin, TX. Its software as a service (SaaS) solutions support identity governance operations in regulated industries such as healthcare, government, and higher education. SailPoint distinguishes multiple aspects of identity as individual identity security services, including cloud governance, […]

Unify log aggregation and analytics across compute platforms
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Our customers want to make sure their users have the best experience running their application on AWS. To make this happen, you need to monitor and fix software problems as quickly as […]
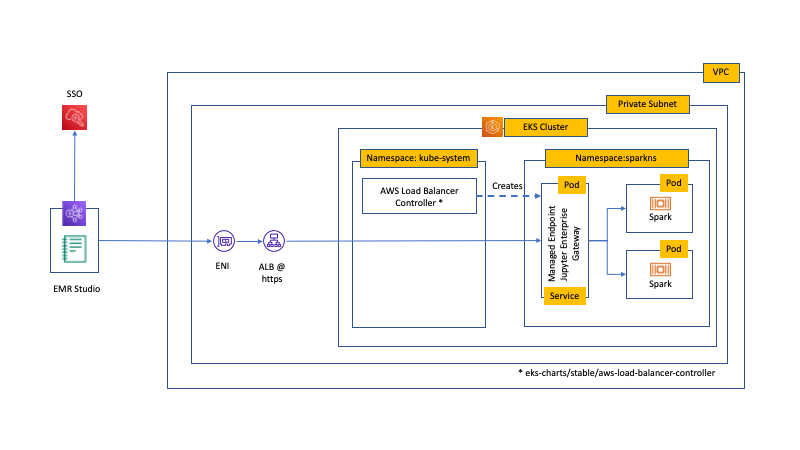
Configure Amazon EMR Studio and Amazon EKS to run notebooks with Amazon EMR on EKS
Amazon EMR on Amazon EKS provides a deployment option for Amazon EMR that allows you to run analytics workloads on Amazon Elastic Kubernetes Service (Amazon EKS). This is an attractive option because it allows you to run applications on a common pool of resources without having to provision infrastructure. In addition, you can use Amazon […]

Reduce costs and increase resource utilization of Apache Spark jobs on Kubernetes with Amazon EMR on Amazon EKS
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows you to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). If you run open-source Apache Spark on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and run Apache Spark up to three times faster. […]

Run and debug Apache Spark applications on AWS with Amazon EMR on Amazon EKS
Customers today want to focus more on their core business model and less on the underlying infrastructure and operational burden. As customers migrate to the AWS Cloud, they’re realizing the benefits of being able to innovate faster on their own applications by relying on AWS to handle big data platforms, operations, and automation. Many of […]

Run a Spark SQL-based ETL pipeline with Amazon EMR on Amazon EKS
Increasingly, a business’s success depends on its agility in transforming data into actionable insights, which requires efficient and automated data processes. In the previous post – Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, we described a common productivity issue in a modern data architecture. To address the challenge, we demonstrated how to utilize a declarative approach as the key enabler to improve efficiency, which resulted in a faster time to value for businesses. Generally speaking, managing applications declaratively in Kubernetes is a widely adopted best practice. You can use the same approach to build and deploy Spark applications with open-source or in-house build frameworks to achieve the same productivity goal.

Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS
Today, the most successful and fastest growing companies are generally data-driven organizations. Taking advantage of data is pivotal to answering many pressing business problems; however, this can prove to be overwhelming and difficult to manage due to data’s increasing diversity, scale, and complexity. One of the most popular technologies that businesses use to overcome these […]