AWS Big Data Blog
Category: Compute

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

Orchestrate multiple ETL jobs using AWS Step Functions and AWS Lambda
In this post, I show you how to use AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs involving a diverse set of technologies in an arbitrarily-complex ETL workflow.
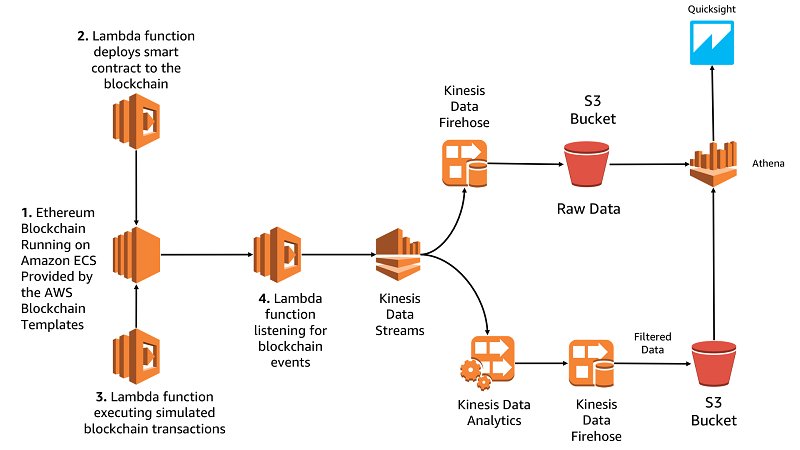
Build a blockchain analytic solution with AWS Lambda, Amazon Kinesis, and Amazon Athena
In this post, we’ll show you how to deploy an Ethereum blockchain using the AWS Blockchain Templates, deploy a smart contract, and build a serverless analytics pipeline for that contract based around AWS Lambda, Amazon Kinesis, and Amazon Athena.
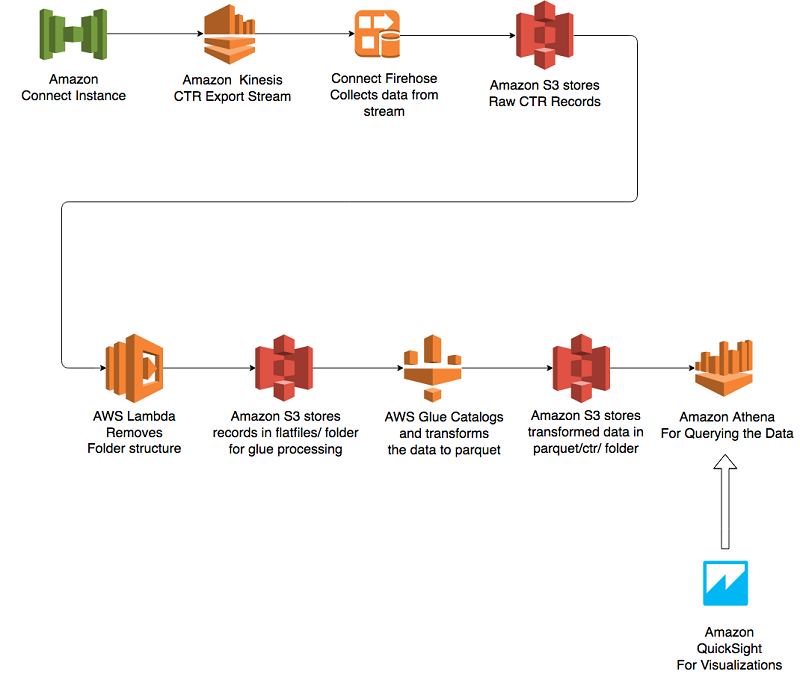
Analyze Amazon Connect records with Amazon Athena, AWS Glue, and Amazon QuickSight
In this blog post, we focus on how to get analytics out of the rich set of data published by Amazon Connect. We make use of an Amazon Connect data stream and create an end-to-end workflow to offer an analytical solution that can be customized based on need.

Orchestrate Apache Spark applications using AWS Step Functions and Apache Livy
In this post, I’ll show you how to use AWS Step Functions to orchestrate your Spark jobs that are running on Amazon EMR.
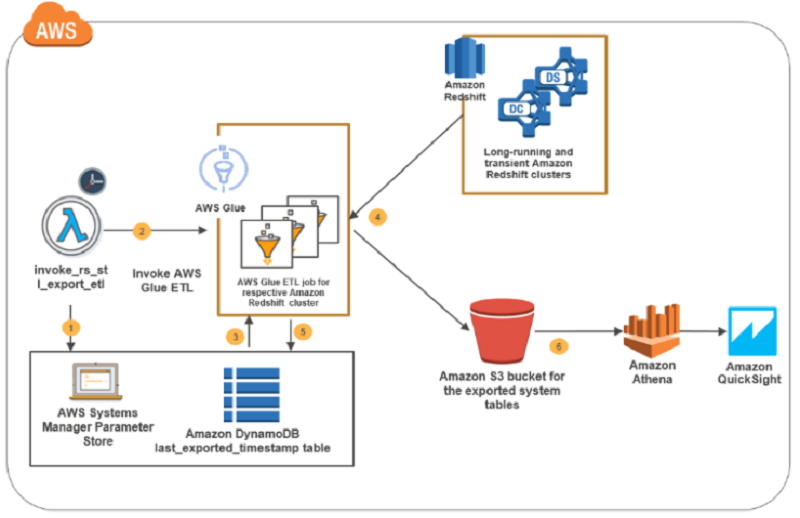
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.
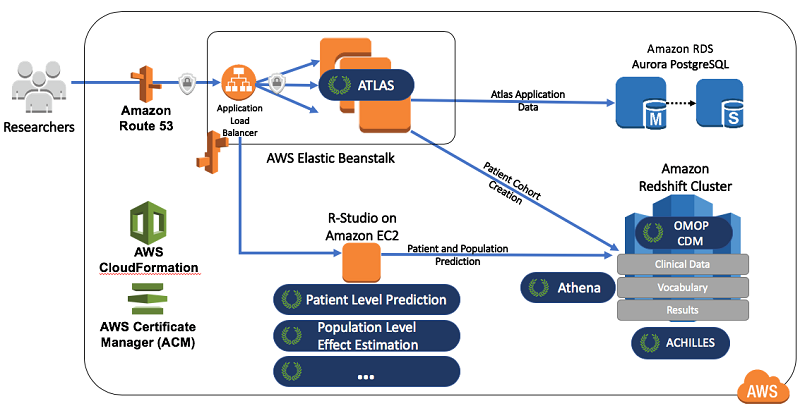
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.

Power from wind: Open data on AWS
Data that describe processes in a spatial context are everywhere in our day-to-day lives and they dominate big data problems. Map data, for instance, whether describing networks of roads or remote sensing data from satellites, get us where we need to go. Atmospheric data from simulations and sensors underlie our weather forecasts and climate models. […]
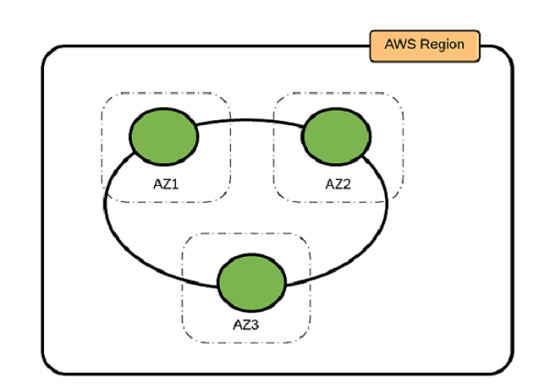
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.