AWS Big Data Blog
Category: Best Practices

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 2
(Continued from Part 1) In this post, we show how you can give on-premises clients and spoke account resources private access to OpenSearch Serverless collections distributed across multiple business unit accounts.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 1
In this post, we show how organizations can provide secure, private access to multiple Amazon OpenSearch Serverless collections from both on-premises environments and distributed AWS accounts using a single centralized interface VPC endpoint and Route 53 Profiles.

Simplifying Kafka operations with Amazon MSK Express brokers
In this post, we show you how Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express brokers brokers streamline the end-to-end activities for Kafka administration.
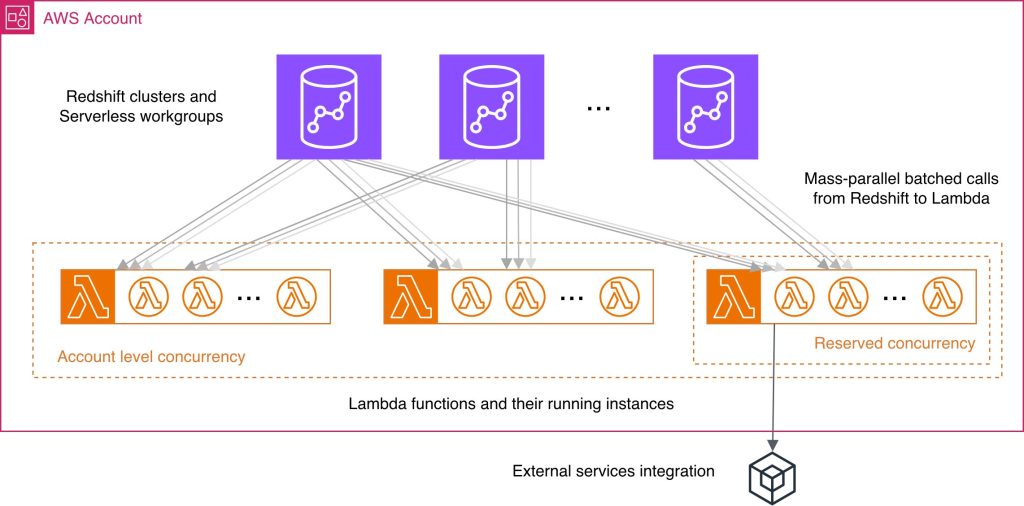
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.

Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.

Kinesis On-demand Advantage saves 60%+ on streaming costs
On November 4, 2025, Amazon Kinesis Data Streams introduced On-demand Advantage mode, a capability that enables on-demand streams to handle instant throughput increases at scale and cost optimization for consistent streaming workloads. Historically, you had to choose between provisioned mode, which required managing stream capacity, and on-demand mode, which automatically scaled capacity, but this new offering removes the need to think about stream type at all. In this post, we show three real-world scenarios comparing different usage patterns and demonstrate how On-demand Advantage mode can optimize your streaming costs while maintaining performance and flexibility.
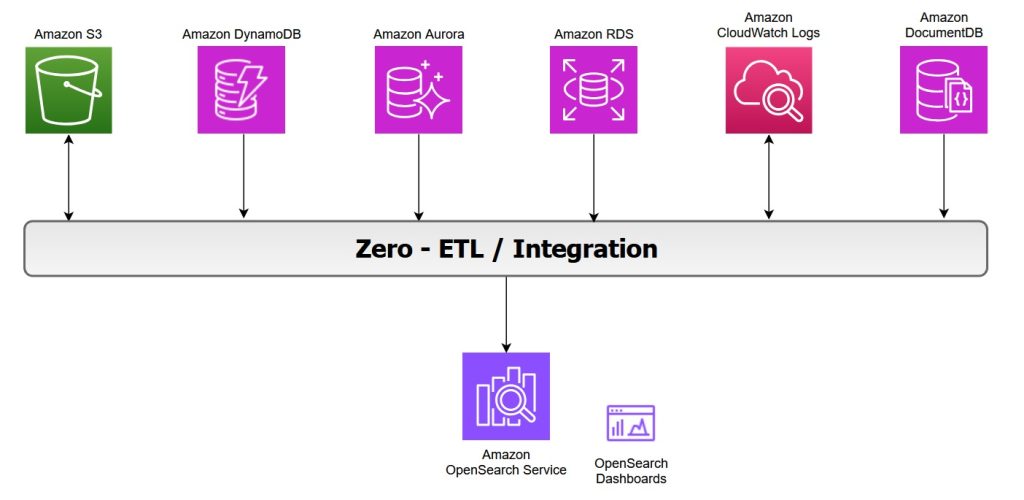
Zero-ETL integrations with Amazon OpenSearch Service
OpenSearch Service offers zero-ETL integrations with other Amazon Web Service (AWS) services, enabling seamless data access and analysis without the need for maintaining complex data pipelines. Zero-ETL refers to a set of integrations designed to minimize or eliminate the need to build traditional extract, transform, load (ETL) pipelines. In this post, we explore various zero-ETL integrations available with OpenSearch Service that can help you accelerate innovation and improve operational efficiency.

Best practices for right-sizing Amazon OpenSearch Service domains
In this post, we guide you through the steps to determine if your OpenSearch Service domain is right-sized, using AWS tools and best practices to optimize your configuration for workloads like log analytics, search, vector search, or synthetic data testing.

Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink
This post was originally published in March 2024 and updated in February 2026. Stream data processing allows you to act on data in real time. Real-time data analytics can help you have on-time and optimized responses while improving overall customer experience. Apache Flink is a distributed computation framework that allows for stateful real-time data processing. It […]
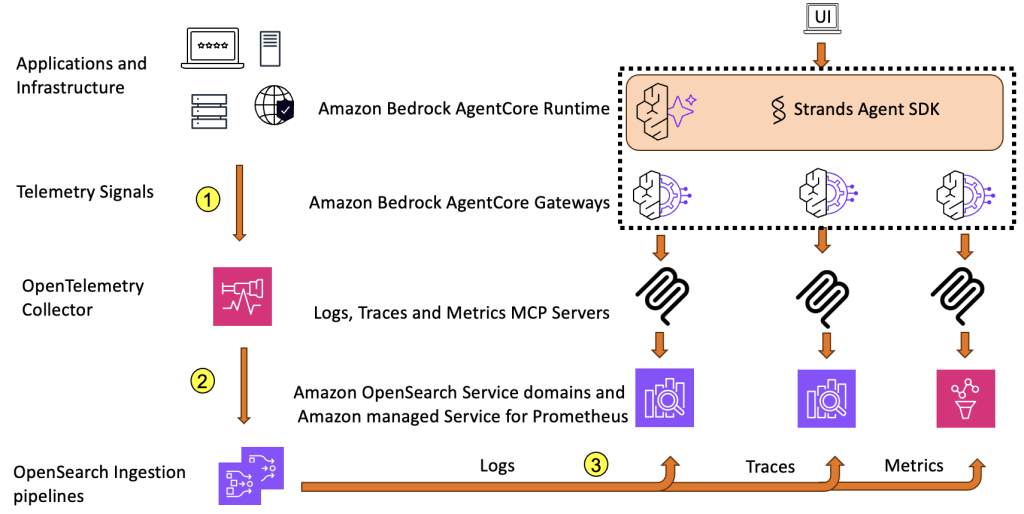
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.