AWS Big Data Blog
Category: Technical How-to

Introducing new features for Amazon Redshift COPY: Part 1
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]

Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]
Copy large datasets from Google Cloud Storage to Amazon S3 using Amazon EMR
Data migration between GCS and Amazon S3 is possible by utilizing Hadoop’s native support for S3 object storage and using a Google-provided Hadoop connector for GCS. This post demonstrates how to configure an EMR cluster for DistCp and S3DistCP, goes over the settings and parameters for both tools, performs a copy of a test 9.4 TB dataset, and compares the performance of the copy.

Use Amazon Athena and Amazon QuickSight in a cross-account environment
This blog post was last reviewed and updated in June 2025. Many AWS customers use a multi-account strategy to host applications for different departments within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach, which raises challenges when you need to use QuickSight in combination with Amazon Athena to […]

Amazon QuickSight deployment models for cross-account and cross-Region access to Amazon Redshift and Amazon RDS
Many AWS customers use multiple AWS accounts and Regions across different departments and applications within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach to centralize users, data source access, and dashboard management. This post explores how you can use different Amazon Virtual Private Cloud (Amazon VPC) private connectivity features to connect QuickSight […]

Create a custom Amazon S3 Storage Lens metrics dashboard using Amazon QuickSight
Companies use Amazon Simple Storage Service (Amazon S3) for its flexibility, durability, scalability, and ability to perform many things besides storing data. This has led to an exponential rise in the usage of S3 buckets across numerous AWS Regions, across tens or even hundreds of AWS accounts. To optimize costs and analyze security posture, Amazon […]
Synchronize and control your Amazon Redshift clusters maintenance windows
Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Amazon Redshift to run mission-critical business intelligence dashboards, analyze real-time streaming data, and run predictive analytics jobs. Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and […]
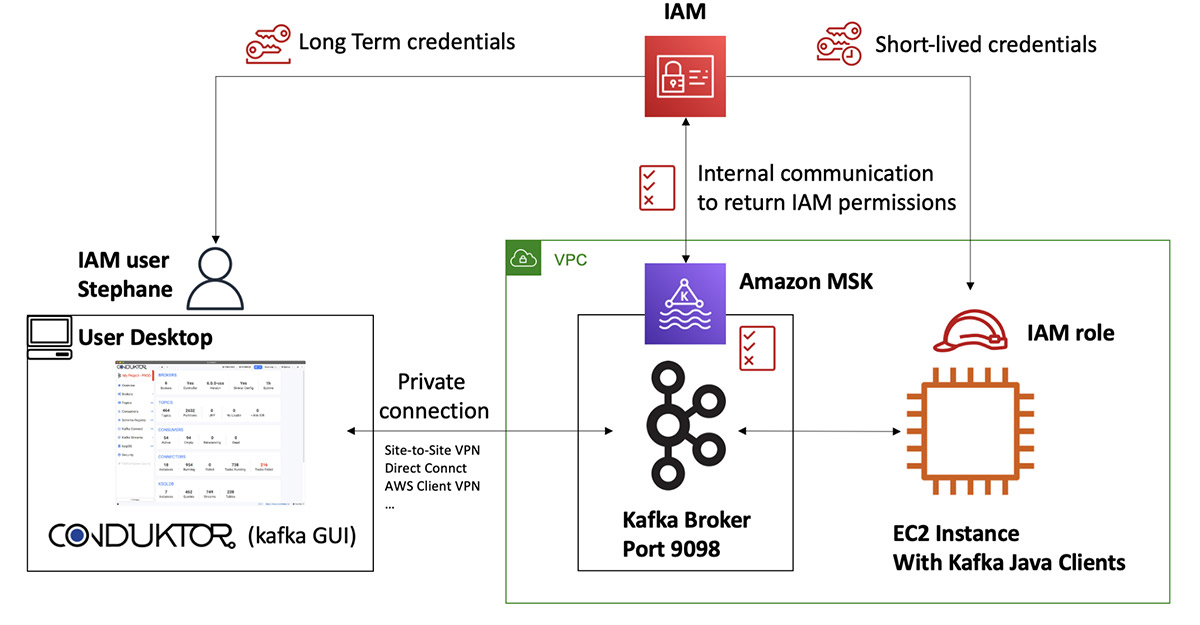
Securing Apache Kafka is easy and familiar with IAM Access Control for Amazon MSK
September 2025: This post was reviewed and updated for accuracy. AWS launched IAM Access Control for Amazon MSK, which is a security option offered at no additional cost that simplifies cluster authentication and Apache Kafka API authorization using AWS Identity and Access Management (IAM) roles or user policies to control access. This eliminates the need […]