AWS Database Blog
Migrate Amazon Aurora and Amazon RDS to a new AWS Region
At times you may need to migrate your workloads from one AWS Region to another Region.
In this post, we highlight best practices for cross-Region migration of Amazon Relational Database Service (Amazon RDS) and Amazon Aurora . We provide prescriptive guidance on migration of various components related to the RDS databases. We also discuss the migration in the context of the same AWS account and same VPC. Lastly, we highlight the considerations and approaches for a cross-Region, cross-account migration. In this post we will focus on the PostgreSQL, MySQL, and MariaDB engines.
There are multiple aspects of the workload that need to be considered for such a migration. A typical workload built on AWS consists of multiple services, such as Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda, and Amazon RDS. For the workload migration, each of these components (or services) needs to be migrated to the target Region. Because the mechanism for migration depends on the nature of the component (or service), you need to think about each component’s migration independently. You need to identify migration options and select an approach that works best for that component in your workload.
Different approaches for cross-Region migration
For a cross-Region migration of RDS databases, there are various approaches to consider. The following table provides a list based on different RDS databases: Amazon RDS for MySQL, Amazon RDS for MariaDB, Amazon RDS for PostgreSQL, Amazon Aurora MySQL-Compatible Edition, and Amazon Aurora PostgreSQL-Compatible Edition.
| Feature | Amazon RDS for MySQL | Amazon RDS for MariaDB | Amazon RDS for PostgreSQL | Amazon Aurora MySQL | Amazon Aurora PostgreSQL |
| Snapshot Restore for Cross-Region Migration | Supported | Supported | Supported | Supported | Supported |
| Read Replica for Cross-Region Migration | Supported | Supported | Supported | Supported | Not Supported |
| Automated Backup for Cross-Region Migration | Supported | Supported | Supported | Not Supported | Not Supported |
| Aurora Global Database | Not Supported | Not Supported | Not Supported | Supported | Supported |
| Native and AWS DMS Replication | Supported | Supported | Supported | Supported | Supported |
Let’s examine each option in more detail.
Snapshot restore for cross-Region migration
(Supports all Databases)
In this option, Amazon RDS creates a storage volume snapshot of your DB instance, backing up the entire DB instance and not just individual databases. You can create a new DB instance by restoring from a DB snapshot. You provide the name of the DB snapshot to restore from, and then provide a name for the new DB instance that is created from the restore. You can’t restore from a DB snapshot to an existing DB instance; a new DB instance is created when you restore. The following diagram illustrates this migration option.

The snapshot restore process is very similar between Amazon RDS and Aurora. For more information, see Copying a DB cluster snapshot and Restoring from a DB cluster snapshot.
Read replica for cross-Region migration
(Supports RDS/Aurora MySQL, RDS PostgreSQL, RDS MariaDB)
The following diagram illustrates the option of using a read replica.

With this method, Amazon RDS creates another DB instance using a snapshot of the source DB instance. It then uses the engines’ native asynchronous replication to update the read replica whenever there is a change to the source DB instance. The read replica operates as a DB instance that allows only read-only connections; applications can connect to a read replica just as they would to any DB instance. Amazon RDS replicates all databases in the source DB instance.
Amazon RDS for MySQL, Amazon RDS for MariaDB, and Amazon RDS for PostgreSQL
Creating a read replica in a different Region from the source instance is similar to creating a replica in the same Region. You can use the AWS Management Console, run the create-db-instance-read-replica command via the AWS Command Line Interface (AWS CLI), or call the CreateDBInstanceReadReplica API operation.
For more information, see Best practices for Amazon RDS for PostgreSQL cross-Region read replicas and Cross-Region Read Replicas for Amazon RDS for MySQL.
After you create the cross-Region read replicas, you can promote them to standalone DB instances. The following steps show the general process for promoting a read replica to a DB instance:
- Stop any transactions from being written to the primary DB instance, then wait for all updates to be made to the read replica.Alternatively, for MySQL and MariaDB you can switch the writer instance to a read-only state by changing the
read_onlyparameter to 1 on the source to protect against accidental writes.Database updates occur on the read replica after they have occurred on the primary DB instance, and this replication lag can vary significantly. - Use the ReplicaLag metric to determine when all updates have been made to the read replica.
- For MySQL and MariaDB only, if you need to make changes to the MySQL or MariaDB read replica, you must set the
read_onlyparameter to 0 in the DB parameter group for the read replica.You can then perform all needed DDL operations, such as creating indexes, on the read replica. Actions taken on the read replica don’t affect the performance of the primary DB instance. - Promote the read replica via the Amazon RDS console, the AWS CLI command promote-read-replica, or the PromoteReadReplica Amazon RDS API operation.
To learn more, see Working with read replicas.
Automated backup for cross-Region migration
(Supports RDS for PostgreSQL, RDS for MySQL, and RDS for MariaDB)
We can also automate backup replication to another AWS Region, which replicates snapshots and transaction logs immediately after they are available in the source. This feature is currently supported for Amazon RDS for PostgreSQL.
For more information, refer to Replicating automated backups to another AWS Region.
The following diagram illustrates the automated backup replication architecture.
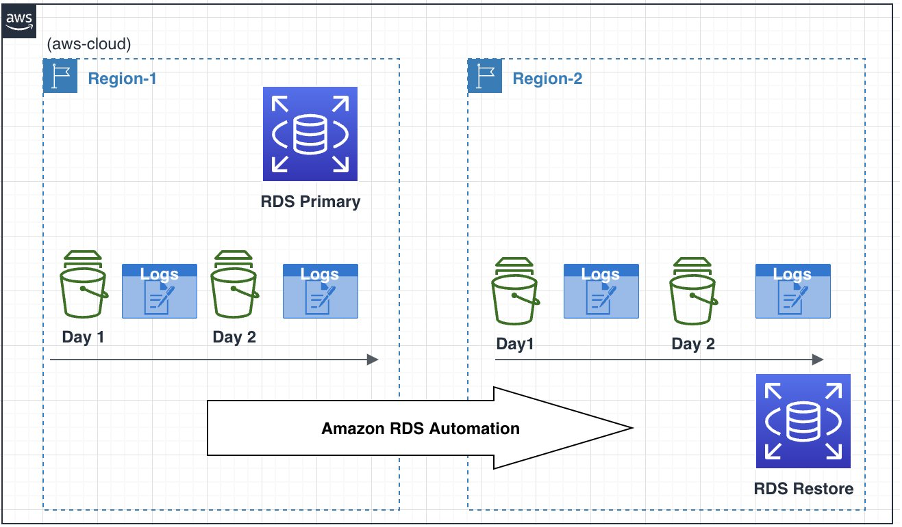
When you’re ready for the Region migration, you can restore a DB instance to a specific point in time from a replicated backup using the Amazon RDS console. You can also use the restore-db-instance-to-point-in-time AWS CLI command or the RestoreDBInstanceToPointInTime RDS API operation.
For general information on point-in-time recovery (PITR), see Restoring a DB instance to a specified time.
For more information on automated backup replication and best practices, refer to Replicating automated backups to another AWS Region.
Aurora Global Database
(Supports Aurora MySQL, Aurora PostgreSQL)
Amazon Aurora Global Database is designed to keep pace with customer and business requirements for globally distributed applications. Aurora Global Database performs storage-level replication using compute resources outside of the instances in the cluster (the storage engine). This results in lower performance impact on the source, lower replication lag, and higher and more consistent throughput. Aurora Global Database is the preferred method over logical replication. This allows Aurora to span multiple Regions and provide cross-Region migration from a primary Region to the secondary Region by promoting the Aurora cluster in the secondary Region in a few minutes.
For more information, refer to Cross-Region disaster recovery using Amazon Aurora Global Database for Amazon Aurora PostgreSQL.
When you create global databases in another Region, you can use managed planned failover to promote and relocate the cluster in another Region. With managed planned failover, you can relocate the primary DB cluster of your Aurora global database to one of the secondary Regions. Because this feature synchronizes secondary DB clusters with the primary before making any other changes, RPO (Recovery Point Objective) is 0 (no data loss).
For Aurora MySQL, you can also create an Aurora read replica of an Aurora MySQL DB cluster in a different Region by using MySQL binary log (binlog) replication. Each cluster can have up to five read replicas created this way, each in a different Region.
For more information about performing managed failover, refer to Using failover in an Amazon Aurora global database.
Native and AWS DMS replication
(Supports all Databases)
Native replication provides another way to create read replica and standby instances in another Region, which can later be promoted to standalone instances. With native replication, the process to set up the read replica and promotion are manual steps.
AWS Database Migration Service (AWS DMS) is the recommended migration method if the migration is heterogenous or if you want to migrate selective datasets.
The following table summarizes the different replication types supported.
| DB Engine | Replication Methods |
| Amazon RDS for MySQL | Binlog, AWS DMS |
| Amazon RDS for MariaDB | Binlog, AWS DMS |
| Amazon RDS for PostgreSQL | AWS DMS, pglogical, native PostgreSQL logical replication |
| Amazon Aurora MySQL | Binlog, AWS DMS |
| Amazon Aurora PostgreSQL | AWS DMS, pglogical, native PostgreSQL logical replication |
For more information about setting up native replication and best practices for Amazon RDS for PostgreSQL and Aurora PostgreSQL, refer to Using logical replication to replicate managed Amazon RDS for PostgreSQL and Amazon Aurora to self-managed PostgreSQL.
For details regarding replication with Amazon RDS for MySQL or Aurora MySQL, refer to Replication between Aurora and MySQL or between Aurora and another Aurora DB cluster (binary log replication).
Cross-Region migration recovery patterns
When performing a cross-Region migration, a major concern is how to minimize the downtime. The following table provides the estimated RPO (Recovery Point Objective) and RTO (Recovery Time Objective) based on the approaches taken. You can use this as a guideline to decide which option would best fit your use case; make sure to test every option thoroughly before making the final decision. With an Aurora PostgreSQL-based global database, you can manage the RPO for your global database by using PostgreSQL’s rds.global_db_rpo parameter. For more information, refer to Managing RPOs for Aurora PostgreSQL–based global databases.
Please make sure to have data validations and data integrity check before new region cutover. It is recommended to avoid any long running transactions on database before the region cutover to minimize the application RTO.
| Migration Method | DB Engine | RPO* | RTO (Approximate) |
| RDS Snapshot to Another Region | PostgreSQL/MySQL/MariaDB | 0 |
Minutes to Hours (Depends on size of the volume and distance b/w regions) |
| RDS Cross-Region Read Replica Promotion | PostgreSQL/MySQL/MariaDB | 0 | 1 or 2 Minutes |
| Aurora Global DB Cross-Region Managed Failover | Aurora PostgreSQL/Aurora MySQL | 0 | Minutes |
| Replicating Automated Backups to Another Region | PostgreSQL/MySQL/MariaDB | 0 | Minutes |
| Aurora Cross-Region Read Replica | Aurora MySQL | 0 | 1 or 2 Minutes |
| Cross-Region Using Native Replication | PostgreSQL/MySQL/MariaDB | 0 | Minutes |
| AWS DMS Replication Cross-Region | Aurora PostgreSQL/Aurora MySQL/PostgreSQL/MySQL/MariaDB | 0 | 1 or 2 Minutes |
*The RPO for migration is 0 since migration methods to new region will be planned activity.
Migration considerations
There are multiple factors related to RDS databases that you need to consider for cross-Region migration, which we discuss in this section. In this post, we provide guidance on component migration in the context of a single AWS account.
Data
RDS databases offer multiple mechanisms for migrating data from one Region to another. Some of these mechanisms are offline (like snapshot backup and restore) and others are online (like read replica promotion or logical replications). The online mechanism reduces the downtime to a minimum from a database perspective. Depending on your needs, you may select the offline or online mechanism.
Encryption keys
RDS databases provide the option for encrypting data at rest. You use an AWS Key Management Service (AWS KMS) key for data encryption and decryption. Depending on the nature of the key used in the source Region, you need to think about migration or creation of the KMS key. You have the option to set the multi-Region property of a KMS key when you create it. You can’t convert a single-Region key to multi-Region key or multi-Region key to single Region. To move existing workloads into multi-Region scenarios, you must re-encrypt your data or create new signatures with new multi-Region keys. For more information, refer to Creating multi-Region replica keys.
Parameter groups
RDS database configuration is managed by way of parameter groups. DB cluster and DB instances in the RDS database may have different custom parameter groups assigned to it. For the migration of the database, you need to ensure that the parameter groups are recreated in the target Region and attached to the right instances in the database.
Database option groups and add-ons
Database engines allow you to extend the engine functionality by way of modules. The add-on capability depends on the RDS engine type. Out-of-the-box Amazon RDS supports option groups for adding functionality to most DB engines. Option groups specify the additional features enabled on the database. If your RDS database is set up with option groups, then you must recreate the custom option group to the target Region.
Secrets
As a best practice for managing RDS database passwords, we recommend using AWS Secrets Manager. If your RDS database is managing secrets in the Secrets Manager, then you need to replicate those secrets to the target Region. For more information, refer to Replicate an AWS Secrets Manager secret to other AWS Regions.
Backup management
Migration of the database also requires you to migrate your backup processes and automation to the target Region. It may be your native RDS or Aurora backup, homegrown automations, or the backup policies defined in the AWS backup.
Monitoring and audit
Monitoring is key to achieving operational excellence. Your operations team needs to have all the dashboards and tooling in the target Region to support the migrated RDS database in the target Region.
Other factors
The factors we have discussed so far must be taken care of for the RDS database migration, because they’re directly related to the RDS database for the workload. The next set of factors are also essential, but because they’re not directly related to Amazon RDS, we won’t be diving deep into these.
Network infrastructure
RDS databases are created in a VPC. Access to the database is controlled by network-level security with mechanisms such as ACLs and security groups. Before you can migrate the RDS databases, you need to set up the VPC and other infrastructure components in the target Region. As a best practice, the infrastructure should be defined as code using standard tools such as AWS CloudFormation. With the AWS CloudFormation import operation, you can make the RDS or Aurora replica part of the CloudFormation stack. Note that prior to cutover, the connectivity must be validated between the new application stack and the database.
Externalized user access
RDS database engines support integration with Active Directory. Often, the AWS Directory Service for Microsoft Active Directory, also known as AWS Managed Microsoft Active Directory (AD) is populated via integration with the on-premises AD. Depending on how you’re using the AD integration, you may need to decide on the approach. For more information, refer to Multi-Region replication.
Application configuration
Application code depends on the distributed components (or services). The code is bound with the components by way of configuration. For RDS databases, the application needs the connection endpoints, which are managed in some form of runtime configuration repository. For example, you can use Amazon Route 53 to define an alias for a database endpoint. This allows for a migration without having to change connection strings.
Data Transfer Costs
There is also data transfer costs involved when migrating between regions. If workload components communicate across multiple Regions using VPC peering connections or Transit Gateway, additional data transfer charges apply. If the VPCs are peered across regions, standard inter-Region data transfer charges will apply. You can use AWS Calculator to find the estimated data transfer costs.
Fallback strategy
Having a fallback plan for any database migration is a must, and we should test and document the complete fallback process in the form of “cookbook” in the event of a rollback.
Additionally, to reduce any application issues arising after migration, you can try to cut over application reads or a proportion of read traffic in advance of the cutover to validate if things work as expected. It’s important that after write traffic is cut over to the secondary Region, the application must not write to the original source to avoid split brain scenarios. If needed, after cutover we can stop replication and configure it in the opposite direction. As a best practice, you can leave the source Region running for a few days in case you experience issues and require a fallback.
Conclusion
When migrating across Regions, you may need to migrate several services and components. In this post, we focused on options for migrating your RDS and Aurora databases across Regions. We discussed several options for the migration using snapshots, backups, read replica promotion, and more, but the decision comes down what works best in your scenario. We encourage you to test the options thoroughly based on your use case and downtime requirements, and follow the best practices to minimize downtime.
We welcome your feedback. Share your comments or questions in the comments section.
About the Authors
 Vishal Srivastava is a Senior Partner Solutions Architect specializing in databases at AWS. In his role, Vishal works with ISV Partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Vishal Srivastava is a Senior Partner Solutions Architect specializing in databases at AWS. In his role, Vishal works with ISV Partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
 Vineet Agarwal is a Senior Database Specialist Solutions Architect with Amazon Web Services (AWS). Prior to AWS, Vineet has worked for large enterprises in financial, retail and healthcare verticals helping them with database and solutions architecture. In his spare time, you’ll find him playing poker, trying a new activity or a DIY project.
Vineet Agarwal is a Senior Database Specialist Solutions Architect with Amazon Web Services (AWS). Prior to AWS, Vineet has worked for large enterprises in financial, retail and healthcare verticals helping them with database and solutions architecture. In his spare time, you’ll find him playing poker, trying a new activity or a DIY project.
 Rajeev Sakhuja is a Solution Architect based out of New York City. He enjoys partnering with customers to solve complex business problems using AWS services. In his free time, he likes to hike, and create video courses on emerging technologies.
Rajeev Sakhuja is a Solution Architect based out of New York City. He enjoys partnering with customers to solve complex business problems using AWS services. In his free time, he likes to hike, and create video courses on emerging technologies.