AWS for Industries
Migrating Enterprise ML Workloads to AWS for large scale ML
Machine learning (ML) models operate directly in the critical path of ad delivery, influencing bidding, pricing, and campaign optimization under strict latency, reliability, and correctness requirements. These models are trained frequently on large volumes of historical auction data and produce deterministic artifacts that downstream serving systems rely on for consistent behavior in production.
Historically, Kargo, a digital advertising platform that powers real-time decisioning across billions of ad auctions every day, implemented their ML pipelines on Databricks. Spark-based notebooks handled data provisioning from Snowflake, feature aggregation, model fitting, and optimization, with intermediate datasets stored in Delta Lake tables. This approach enabled rapid iteration early on, but as pipelines expanded across multiple models and execution dimensions, it introduced increasing operational complexity.
As part of this evolution, shared modeling logic was often composed dynamically at runtime through notebook-level imports and platform-specific constructs. Although this pattern was effective for experimentation, it made reproducibility, continuous integration and continuous delivery (CI/CD) adoption, and portability to production environments more challenging.
To support continued growth, we migrated our enterprise ML workloads to a fully Amazon Web Services (AWS) based architecture built around managed data processing, orchestration, and ML services. This migration consolidated our data and ML infrastructure onto AWS, enabled large-scale parallel execution across workloads, and significantly improved the maintainability and extensibility of our ML platform.
In this post, we detail our migration journey: the challenges we faced; our architectural redesign using AWS Glue, Apache Iceberg, and Amazon SageMaker; and how we achieved scalable, cost-efficient, reproducible machine learning at Kargo.
Migration plan
Rather than attempting a lift and shift, we approached the migration as a re-architecture driven by production requirements. The plan was guided by four hard constraints.
The first constraint was output parity. Existing pipelines produce deterministic artifact sets—lookup files, configurations, and pointer files. These artifacts are consumed directly by downstream decisioning systems and act as a contract between training and serving, defining both model behavior and safe rollout boundaries.
Because downstream systems depend on the exact structure, ordering, and availability of these files, the AWS migration needed to produce byte-for-byte identical outputs for the same inputs. This requirement shaped the migration approach and is addressed later in the post through deterministic data partitioning, containerized execution, and controlled orchestration.
Second, we require minimal change to modeling logic. Core curve-fitting and optimization code—implemented using libraries such as lmfit, Pyomo, and Gurobi—had already been validated in production. To reduce risk, the migration focused on changing the execution substrate while reusing existing Python logic directly.
Third, the platform needed operational safety at scale. Pipelines had to support large fan-out execution across dimensions such as demand-side platform (DSP), media type, and auction type, with strict failure isolation, reproducible reruns, deterministic artifact publication, and automated deployment through CI/CD.
Finally, the architecture needed to be compatible with real-time inference. A growing portion of our ML workloads operate directly in the ad request path, where models must serve predictions at a million-request-per-second scale with single-digit millisecond latency. The migrated system needed to integrate cleanly with a dedicated real-time serving layer without coupling inference to batch or training infrastructure.
With these constraints in place, we executed the migration in progressive phases, starting with simpler workloads and moving toward more complex, tightly integrated systems. We began with supervised models to validate containerization, CI/CD pipelines, and basic SageMaker workflows. We then migrated to the Optimal Bid/CPM pipeline, which drove the adoption of AWS Glue, Apache Iceberg, Amazon Athena, and Amazon SageMaker Pipelines to orchestrate large-scale parallel execution.
With the data and optimization foundation in place, we moved to click-through rate (CTR) and video recommendation models, introducing explicit model lifecycle management based on SageMaker Pipelines. Finally, we migrated the dynamic product ads models, which exercised the full platform—from feature store integration and frequent retraining to strict artifact versioning and low-latency real-time inference using sidecar-based serving.
By using this phased approach, we reduced the risk of the migration, validated each architectural layer independently, and converged on a unified AWS based platform that supports both offline optimization and real-time inference without forcing all workloads into a single execution model.
Solution overview
The new architecture is built around a clear separation of concerns, allowing data provisioning, model training, orchestration, and serving to evolve independently while sharing a common platform foundation on AWS.
The solution follows these six high-level phases:
- Re-architecting data provisioning with AWS Glue and Iceberg
- Modularizing ML code and containerized execution
- Orchestrating the full workflow with SageMaker Pipelines
- End-to-end lifecycle training
- Real-time inference and serving at scale
- Observability, monitoring, and operational reliability
Re-architecting data provisioning with AWS Glue and Iceberg
The first step was replacing our Delta Lake–based ETL jobs with AWS Glue, configured to write Iceberg tables to Amazon Simple Storage Service (Amazon S3). Iceberg offered atomicity, consistency, isolation, durability (ACID) transactions, schema evolution, and efficient metadata pruning—critical for multi-DSP and multi-media optimization.
AWS Glue ETL jobs extract data from Snowflake, perform Spark-based joins and aggregations, and output partitioned Iceberg tables organized by DSP, media type, auction type, and advertiser CPM bucket. Iceberg’s open metadata layer allows Athena to perform dynamic queries across multiple dimensions without pre-computed datasets.
For example, ad campaign performance by demand-side platform and media type can be queried directly using Amazon Athena. Rather than materializing separate datasets for every combination of demand-side platform, media type, or auction type, we execute targeted, serverless Athena queries directly against provisioned Iceberg tables. These queries aggregate historical auction data across the required dimensions—such as DSP, media format, and auction type—and produce precisely scoped datasets for downstream model training and optimization.
Because Athena operates directly on data stored in Amazon S3 and uses Iceberg’s metadata-driven partition pruning, each query reads only the relevant partitions instead of scanning entire datasets. Using this approach, we dynamically slice and aggregate data on demand without maintaining long-running query clusters or precomputing large numbers of intermediate tables.
From a cost and operational perspective, this was a significant improvement over the previous model. Instead of provisioning and managing database or Spark clusters to support analytical queries, we rely on the Athena serverless, pay-per-query execution model, which scales automatically with workload size and incurs cost only when queries are executed. This reduced the operational overhead associated with always-on infrastructure while still supporting complex, multidimensional queries required by the optimization pipelines.
The resulting query outputs are written as optimized Parquet files to Amazon S3 and consumed directly by model training, which run as SageMaker processing jobs, enabling a clean and efficient handoff between data provisioning and model training.
This design eliminated the need for persistent cluster-based infrastructure and reduced data engineering compute costs.
Modularizing ML code and containerized execution
Previously, reusable modeling logic—such as curve fitting, parameter estimation, and solver configuration—was distributed across multiple notebooks. Although this supported rapid experimentation, it tightly coupled execution to the notebook environment and made versioning, testing, and automation more difficult as pipelines scaled.
As part of the migration, we consolidated all shared logic into a structured Python package maintained in a single source directory. This package is reused consistently across data provisioning, model training, and optimization workflows. Model execution is performed inside containerized runtimes hosted in Amazon Elastic Container Registry (Amazon ECR) and invoked through Amazon SageMaker Processing jobs.
Each processing job ran in a fully defined, reproducible environment that included the required numerical and optimization dependencies (such as Pyomo, IPOPT, lmfit, and supporting data libraries). By baking dependencies into the container image, we eliminated reliance on implicit notebook state and enabled the same runtime environment to be used across development, testing, and production.
This container-based approach decoupled modeling code from the execution platform and enabled standard software engineering practices such as unit testing, versioned releases, and automated CI/CD pipelines using GitHub Actions. It also meant that we could change the underlying execution infrastructure—moving from Databricks to SageMaker—without rewriting validated modeling logic.
Orchestrating the full workflow with SageMaker Pipelines
To simplify operations and make every run traceable, we standardized on SageMaker Pipelines to orchestrate the entire workflow—from data provisioning to artifact publication. Each pipeline execution captures parameters, inputs, outputs, and lineage metadata so we can reproduce any historical model build from end to end.
The first step in every pipeline execution is a lightweight AWS Lambda function that generates a run timestamp version (for example, YYYYMMDD-HHMMSS) and derives a deterministic Amazon S3 prefix for all intermediate and final outputs. This guarantees immutability for every run and enables safe publication semantics using marker and pointer files when validation is completed.
A typical pipeline execution includes:
- Data provisioning – Start and monitor an AWS Glue job that extracts from Snowflake and writes partitioned Iceberg tables to Amazon S3.
- Dataset assembly – Run parameterized Athena queries against Iceberg and export scoped training slices as Parquet to Amazon S3.
- Model fitting and optimization – Launch SageMaker processing (and, where applicable, training) jobs using shared Amazon ECR container images. Fan-out across DSP, media type, and auction configuration is achieved by running many parameterized pipeline executions concurrently, and independent steps can execute in parallel when dependencies allow.
- Validation and publication – Compute quality checks, generate deterministic artifact bundles, register model packages (or publish pointer files), and promote versions via explicit aliases such as champion and challenger.
To control throughput and cost, we cap the maximum number of concurrently running steps per execution and enable step caching for expensive but deterministic preprocessing. This allows reruns with identical inputs to reuse previous outputs rather than recomputing them.
The SageMaker pipeline follows this workflow:
- The AWS Lambda function generates a timestamp, executes the process, and creates a new version of the output.
- Fetch the data from Snowflake using AWS Glue ETL process and store in an Iceberg table.
- Take the data from Iceberg, perform slicing and aggregation using Amazon Athena, and store in a Parquet file.
- Use an Amazon SageMaker processing job with custom containers to train the models, running jobs in parallel for each DSP or media type. Store the artifacts in Amazon ECR.
- Validate the result and choose the best model.
- Publish artifacts to Amazon SageMaker Model Registry.
- The inference serving layer loads the model from the model registry.
The following diagram shows this workflow.
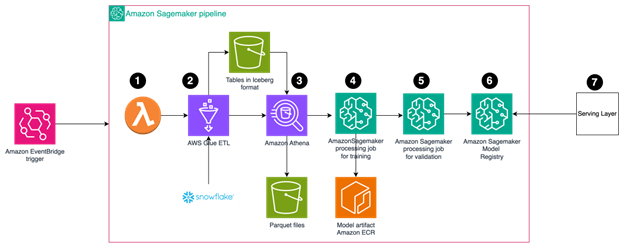 Figure 1: SageMaker pipeline workflow
Figure 1: SageMaker pipeline workflow
End-to-end lifecycle training
The migrated architecture standardizes the full model lifecycle from provisioning to production serving. Training begins with feature generation and dataset assembly, either through a feature store or through Iceberg or Athena fallback. Models are trained using Python APIs inside SageMaker jobs. Outputs are structured artifact bundles that include inference logic, feature transforms, and metadata.
Models are stored in a registry or in Amazon S3 with explicit tags such as model_family, model_version, and environment-specific aliases. Promotion is an explicit operation, enabling safe rollout and rollback.
Serving is decoupled from training. In production, inference is handled by dedicated services that consume registered artifacts. For some workloads—such as Vowpal Wabbit-based models—inference runs in a Python sidecar container deployed alongside the main request-handling service. This isolates model runtime concerns, supports hot reload without restarts, and avoids threading issues.
Sidecar containers periodically poll the model registry for updates, download new artifacts, and perform in-memory reloads. The primary service routes inference requests over a low-latency interface such as TCP or Unix domain sockets. This design supports zero-downtime model updates under live traffic.
Real-time inference and serving at scale
Inference runs in a dedicated serving layer that consumes versioned model artifacts produced by the workflows. Models are deployed into explicitly defined execution environments such as sidecar containers or managed SageMaker endpoints. They can be hot-reloaded, scaled independently, and optimized for low-latency execution in this environment. This separation allows training, orchestration, and serving to evolve independently, which means that changes to model pipelines don’t impact the stability or performance of latency-sensitive production inference.
Observability monitoring, and operational reliability
System components emit structured logs, metrics, and execution metadata to Amazon CloudWatch, enabling consistent observability across the ML platform. AWS Glue jobs, Athena queries, SageMaker processing and training jobs, and SageMaker pipeline executions are monitored through a unified logging and metrics layer, making it easier to trace failures, understand performance bottlenecks, and correlate issues across services.
Operational reliability is reinforced through automated, versioned deployments managed through GitHub Actions. AWS Glue scripts, container images, and SageMaker pipeline definitions are deployed using infrastructure as code (IaC) tools such as Terraform or AWS Cloud Development Kit (AWS CDK), providing traceability and reproducibility. Marker and pointer files enforce safe publication semantics, support controlled rollouts, and enable fast rollback when anomalies are detected through monitoring.
Results and benefits
The migration delivered significant performance and operational improvements across all key metrics:
| Dimension | Prior Architecture (Databricks-based) | AWS Native Stack | Improvement |
| Cost | Cluster-based execution model used in our prior implementation | Serverless | Approximately 40% reduction in compute costs driven by serverless data processing and managed orchestration |
| Runtime | Sequential pipelines was used | Parallel Step Functions | 3–5X faster execution enabled by parallelization and improved orchestration |
| Scalability | Our Architecutre used limited parallel execution | Distributed Map | Near-linear scale for multi-DSP workloads |
| Portability | Notebook-coupled implementation | Open-source Iceberg + Docker | Full vendor independence |
| Observability | Fragmented logs | CloudWatch + Odin | Unified monitoring and traceability |
The move to AWS also simplified governance through AWS Identity and Access Management (IAM) based permissions and virtual private cloud (VPC) isolation, and enabled faster iteration through automated build pipelines for container images and AWS Glue jobs.
Lessons learned
Migrating from Databricks to AWS wasn’t a simple platform substitution; it required a deliberate rethinking of how different classes of ML workloads should be built, executed, and operated. Rather than attempting a lift and shift, we treated the migration as an opportunity to separate concerns across data provisioning, model execution, orchestration, and serving, and to align each layer with services designed for its specific execution characteristics.
One of the most important lessons was the value of modularization and early investment in open formats. By decoupling modeling logic from execution environments and standardizing on Iceberg for data storage and Docker for runtime packaging, we avoided tight coupling to any single platform and significantly improved portability, testability, and long-term maintainability. By using this approach, we were able to reuse existing Python modeling code while changing the underlying execution substrate with minimal risk.
We also learned that not all ML workloads benefit from the same execution model. Interactive development, large-scale batch processing, and latency-sensitive inference have very different requirements. Treating them as distinct workload classes—and mapping each to the appropriate AWS primitives—helped avoid overengineering and reduced both operational complexity and cost.
Adopting serverless through AWS Glue and Athena and managed orchestration primitives simplified operations at scale while resulting in significant cost savings. Using SageMaker Pipelines meant we could express complex workflows with clear data dependencies, parallel step execution, and step caching, eliminating much of the operational friction associated with managing long-lived clusters or custom schedulers. For model lifecycle management, SageMaker Pipelines also provided a consistent framework for defining training, evaluation, registration, and controlled promotion, improving reproducibility and governance.
Another key lesson was the importance of explicit versioning and immutability across the ML lifecycle. Versioned data (Iceberg snapshots), versioned code (container images), and versioned models (registry artifacts) made it significantly easier to reason about reproducibility, rollback failures, and audit model behavior over time. This discipline proved especially valuable during parallel experimentation and incremental rollout of new pipelines.
We also found that operational simplicity is a prerequisite for scale. Early investments in standardized container images, shared libraries, and common deployment patterns reduced cognitive load for teams and made it easier to onboard new use cases without bespoke engineering. In practice, consistency mattered more than theoretical flexibility.
Finally, integrating observability as a first-class concern proved critical. By standardizing logging and metrics through Amazon CloudWatch and internal dashboards such as Odin, teams gained real-time visibility into pipeline execution, performance characteristics, and failure modes. This visibility made it easier to reason about system behavior, debug issues quickly, and operate the platform with confidence as scale increased.
Conclusion
Migrating our ML workloads from Databricks to AWS fundamentally changed how Kargo builds, trains, and serves models. By embracing AWS managed services for data processing, orchestration, and model execution, we established a platform that supports a wide range of workloads—from large-scale offline optimization to feature-driven model lifecycles and real-time inference—without forcing them into a single execution model.
Today, the core ML pipelines run on AWS using serverless data processing, containerized execution, and dedicated real-time serving infrastructure. This foundation means that Kargo can scale workloads independently, evolve model architectures and serving runtimes over time, and maintain strict latency and reliability requirements for production systems.
With this platform in place, Kargo is continuing to expand into areas such as feature store integration using Feast and Amazon ElastiCache for Valkey, automated retraining and monitoring with Amazon SageMaker Model Monitor, and richer lineage and metadata tracking with DataHub. The architecture Kargo built enables quick iteration while maintaining the performance and operational rigor required for real-time advertising systems.
Contact an AWS Representative to know how we can help accelerate your business.
Further reading
- Bring legacy machine learning code into Amazon SageMaker using AWS Step Functions
- Generative AI inference architecture and best practices on AWS
- Migrate MLflow tracking servers to Amazon SageMaker AI with serverless MLflow
- How Pendulum achieves 6x faster processing and 40% cost reduction with Amazon S3 Tables
- Build real-time data lakes with Snowflake and Amazon S3 Tables