Artificial Intelligence
Accelerate business outcomes with 70% performance improvements to data processing, training, and inference with Amazon SageMaker Canvas
Amazon SageMaker Canvas is a visual interface that enables business analysts to generate accurate machine learning (ML) predictions on their own, without requiring any ML experience or having to write a single line of code. SageMaker Canvas’s intuitive user interface lets business analysts browse and access disparate data sources in the cloud or on premises, prepare and explore the data, build and train ML models, and generate accurate predictions within a single workspace.
SageMaker Canvas allows analysts to use different data workloads to achieve the desired business outcomes with high accuracy and performance. The compute, storage, and memory requirements to generate accurate predictions are abstracted from the end-user, enabling them to focus on the business problem to be solved. Earlier this year, we announced performance optimizations based on customer feedback to deliver faster and more accurate model training times with SageMaker Canvas.
In this post, we show how SageMaker Canvas can now process data, train models, and generate predictions with increased speed and efficiency for different dataset sizes.
Prerequisites
If you would like to follow along, complete the following prerequisites:
- Have an AWS account.
- Set up SageMaker Canvas. For instructions, refer to Prerequisites for setting up Amazon SageMaker Canvas.
- Download the following two datasets to your local computer. The first is the NYC Yellow Taxi Trip dataset; the second is the eCommerce behavior data about retails events related to products and users.
Both datasets come under the Attribution 4.0 International (CC BY 4.0) license and are free to share and adapt.
Data processing improvements
With underlying performance optimizations, the time to import data into SageMaker Canvas has improved by over 70%. You can now import datasets of up to 2 GB in approximately 50 seconds and up to 5 GB in approximately 65 seconds.
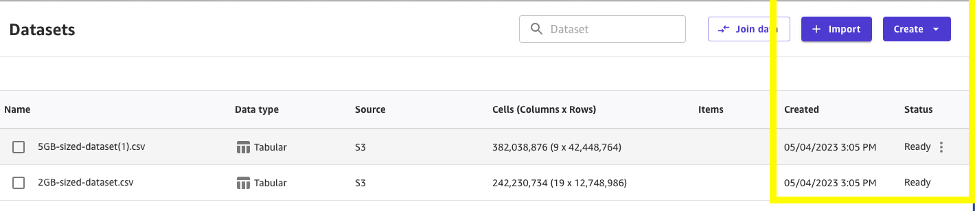
After importing data, business analysts typically validate the data to ensure there are no issues found within the dataset. Example validation checks can be ensuring columns contain the correct data type, seeing if the value ranges are in line with expectations, making sure there is uniqueness in values where applicable, and others.
Data validation is now faster. In our tests, all validations took 50 seconds for the taxi dataset exceeding 5 GB in size, a 10-times improvement in speed.
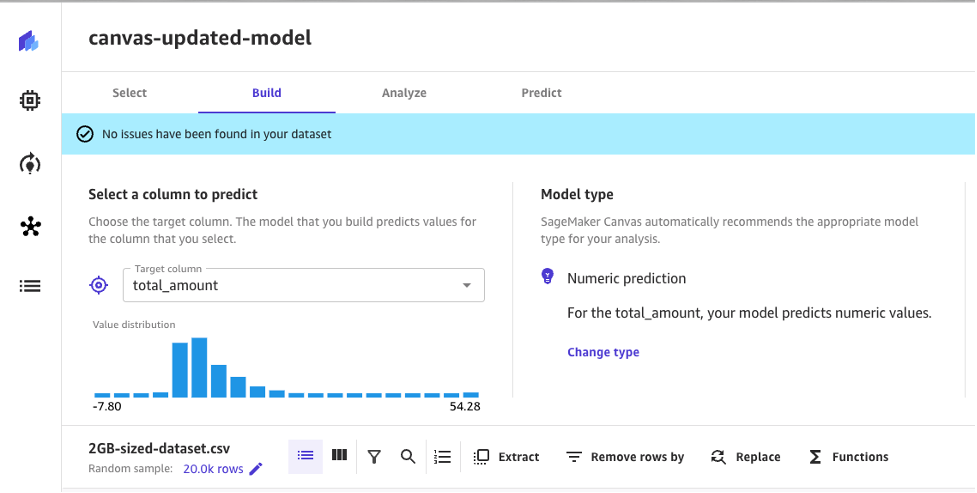
Model training improvements
The performance optimizations related to ML model training in SageMaker Canvas now enable you to train models without running into potential out-of-memory requests failures.
The following screenshot shows the results of a successful build run using a large dataset the impact of the total_amount feature on the target variable.
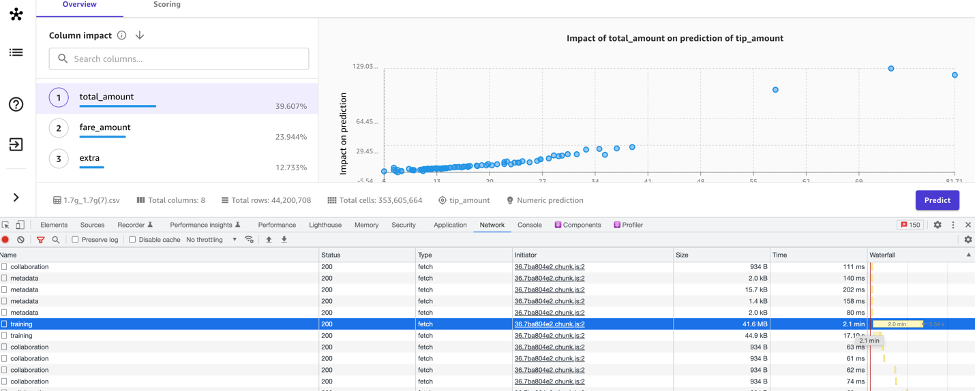
Inference improvements
Finally, SageMaker Canvas inference improvements achieved a 3.5 times reduction memory consumption in case of larger datasets in our internal testing.
Conclusion
In this post, we saw various improvements with SageMaker Canvas in importing, validation, training, and inference. We saw an increased in its ability to import large datasets by 70%. We saw a 10 times improvement in data validation, and a 3.5 times reduction in memory consumption. These improvements allow you to better work with large datasets and reduce time when building ML models with SageMaker Canvas.
We encourage you to experience the improvements yourself. We welcome your feedback as we continuously work on performance optimizations to improve the user experience.
About the authors
 Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
Peter Chung is a Solutions Architect for AWS, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions in both the public and private sectors. He holds all AWS certifications as well as two GCP certifications. He enjoys coffee, cooking, staying active, and spending time with his family.
 Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
Tim Song is a Software Development Engineer at AWS SageMaker, with 10+ years of experience as software developer, consultant and tech leader he has demonstrated ability to deliver scalable and reliable products and solve complex problems. In his spare time, he enjoys the nature, outdoor running, hiking and etc.
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.
Maia Haile is a Solutions Architect at Amazon Web Services based in the Washington, D.C. area. In that role, she helps public sector customers achieve their mission objectives with well architected solutions on AWS. She has 5 years of experience spanning from nonprofit healthcare, Media and Entertainment, and retail. Her passion is leveraging intelligence (AI) and machine learning (ML) to help Public Sector customers achieve their business and technical goals.