Artificial Intelligence
Accelerating AI model production at Hexagon with Amazon SageMaker HyperPod
This blog post was co-authored with Johannes Maunz, Tobias Bösch Borgards, Aleksander Cisłak, and Bartłomiej Gralewicz from Hexagon.
Hexagon is the global leader in measurement technologies and provides the confidence that vital industries rely on to build, navigate, and innovate. From microns to Mars, Hexagon’s solutions drive productivity, quality, safety, and sustainability across aerospace, agriculture, automotive, construction, manufacturing, and mining.
Applications in these industries often rely on capturing the reality by recording vast amounts of highly accurate point cloud data with Hexagon measurement technology. A point cloud is a collection of data points in 3D space, typically representing the external surface of an object or a scene. Point clouds are commonly used in applications like 3D modeling, computer vision, robotics, autonomous vehicles, and geospatial analysis.
Hexagon provides specialized AI models to its customers to help them ensure productivity, quality, safety, or sustainability in their applications. These AI models are purpose built for a given domain and usually focus on understanding the built environment.
In this blog post, we demonstrate how Hexagon collaborated with Amazon Web Services to scale their AI model production by pretraining state-of-the-art segmentation models, using the model training infrastructure of Amazon SageMaker HyperPod.
AI impact and opportunity
AI models provided by Hexagon to its customers help them solve complex challenges. These challenges are solved by specialized AI models that are often more effective than large, general-purpose ones. Before using scanned point clouds in geospatial applications, it’s essential to perform preprocessing and point cloud cleaning operations. Instead of relying on a single AI model to classify an entire dataset, targeted AI models have been developed that tackle distinct operations: one efficiently removes stray points from dust or sensor noise, another helps separate land types even in complex environments, and another detects and eliminates moving objects like cars and pedestrians while keeping fixed objects in the scene. This AI approach not only improves precision and efficiency, but also reduces processing demands and leads to faster creation of and more accurate 3D models.
The following figures illustrate the practical application of specialized AI models, such as the point cloud classification models that Hexagon is developing.
The first figure shows how mobile mapping road models enable the creation of digital twins of entire cities.

The second figure is a heavy construction model that enables on-site decision making.

There’s a significant opportunity to accelerate Hexagon’s AI innovation and time-to-market by implementing a robust, scalable, and high-performance infrastructure that enables efficient and fast model training and development of new, specialized AI use cases in days rather than months.
Hexagon and Amazon SageMaker HyperPod: A success story
To address Hexagon’s need for scalable compute resources, access to the latest GPUs, and streamlined training pipelines, the Hexagon team evaluated the key features of Amazon SageMaker HyperPod for their model training requirements:
- Resilient architecture: SageMaker HyperPod streamlined operations through proactive node health checks and automated cluster monitoring. With built-in self-healing capabilities and automated job resumption, it enables training runs to run for weeks or months without interruptions. In the event of a node failure, it will automatically detect the failure, replace the faulty node, and resume the training from the most recent checkpoint.
- Scalable infrastructure: Using single-spine node topology and pre-configured Elastic Fabric Adapter (EFA), SageMaker HyperPod delivers optimal inter-node communication. Its flexible compute capacity allocation enables seamless scaling without compromising performance, making it ideal for growing workloads spanning multiple nodes.
- Versatile deployment: Compatible with a wide range of generative AI software stacks, SageMaker HyperPod simplifies deployment through lifecycle scripts and Helm customization. It supports leading Amazon Elastic Compute Cloud (Amazon EC2) instances like the P6-B200 and P6e-GB200, which are accelerated by NVIDIA Blackwell GPUs, offering versatility in implementation.
- Efficient operations: Through intelligent task governance and integrated SageMaker tools, SageMaker HyperPod automatically optimizes cluster utilization. Pre-configured Deep Learning Amazon Machine Images (DLAMI) with compatible drivers and libraries, combined with quick start training recipes, help to ensure maximum operational efficiency.
Solution overview
Hexagon implemented a robust training environment using Amazon SageMaker HyperPod managed infrastructure, shown in the following figure. It includes an integrated data pipeline, compute cluster management, and MLOps monitoring stack.
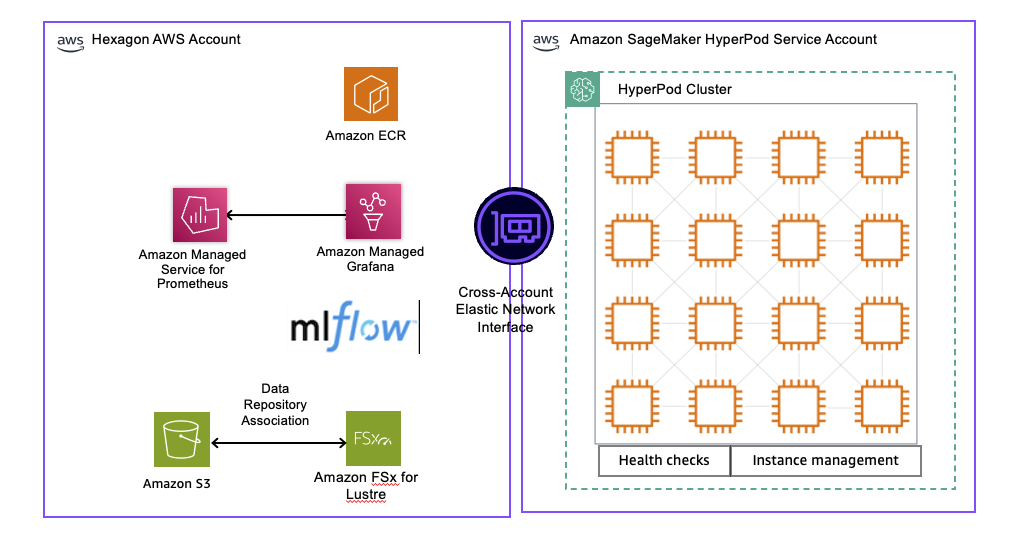
Solution Architecture Diagram
Data pipeline and storage
Training data is stored in Amazon Simple Storage Service (Amazon S3) within Hexagon’s AWS account, with Amazon FSx for Lustre providing high-performance parallel file system capabilities. The Amazon FSx for Lustre file system is configured with a data repository association (DRA) that automatically synchronizes with the S3 bucket, enabling lazy loading of training data and automatic export of model checkpoints back to Amazon S3.
This configuration enables streaming of terabytes of training data directly to GPU accelerated compute nodes at multi-GBs per second throughput rates, eliminating data transfer bottlenecks during model training. The DRA helps ensure that data scientists can work with familiar Amazon S3 interfaces while benefiting from the performance advantages of a parallel file system during training.
Compute cluster management
SageMaker HyperPod cluster provisioned with built-in health checks and automated instance management. Through Amazon SageMaker Training Plans, Hexagon can flexibly reserve GPU capacity from 1 day to 6 months, helping to ensure resource availability for both short experimental runs and extended training campaigns. These training plans provide predictable pricing and dedicated capacity, eliminating the uncertainty of on-demand resource availability for critical model development. The cluster automatically handles node failures and job resumption, maintaining training continuity without manual intervention.
MLOps and monitoring stack
The environment integrates with a one-click observability solution from Amazon SageMaker HyperPod, which automatically publishes comprehensive metrics to Amazon Managed Service for Prometheus and visualizes them through pre-built Amazon Managed Grafana dashboards optimized for foundation model development.
This unified observability consolidates health and performance data from NVIDIA Data Center GPU Manager, Kubernetes node exporters, EFA, integrated file systems, and SageMaker HyperPod task operators, enabling per-GPU level monitoring of resource utilization, GPU memory, and FLOPs.
For experiment tracking, MLflow on Amazon SageMaker AI provides a fully managed solution that requires minimal code modifications to Hexagon’s training containers. This integration enables automatic tracking of training parameters, metrics, model artifacts, and lineage across all experiment runs, with the ability to compare model performance and reproduce results reliably.
Key outcomes from using SageMaker HyperPod at Hexagon
Hexagon’s implementation of SageMaker HyperPod delivered measurable improvements across deployment speed, training efficiency, and model performance.
- Quick integration and deployment: Hexagon successfully integrated SageMaker HyperPod for training and achieved their first training deployment within hours, reflecting the ease of set-up and enhanced end-user experience for machine learning (ML) developers. Having all the services required for training models under a single ecosystem helped meet security and governance needs.
- Training time reduction: Hexagon reduced their training time from 80 days on-premises for a given network and configuration to approximately 4 days on AWS using 6x ml.p5.48xlarge instances each containing eight NVIDIA H100 GPUs, with EFA network interface that boosts distributed training efficiency through low-latency, high throughput networking for multi-node GPU training.
- Performance enhancement: SageMaker HyperPod enabled larger batch sizes during training, which led to better training performance, resulting in higher accuracy scores for the trained AI models.
AWS Enterprise Support played a crucial role in Hexagon’s successful implementation of Amazon SageMaker HyperPod. Through proactive guidance, deep technical expertise, and dedicated partnership, the AWS Enterprise Support team helped Hexagon navigate their cloud journey from initial AWS adoption to advanced generative AI implementations. The comprehensive support included best practices guidance, cost optimization strategies, and continuous architectural advice, so that Hexagon’s team could focus on innovation while maintaining operational excellence. This strategic partnership demonstrates how AWS Enterprise Support goes beyond traditional support services, becoming a trusted advisor that helps customers accelerate their business transformation and achieve their desired outcomes in the cloud.
Conclusion
Hexagon’s collaboration with Amazon Web Services delivered a remarkable 95% reduction in training time through Amazon SageMaker HyperPod. With flexible training plans, Hexagon teams can now provision the exact amount of accelerated compute capacity needed for each model training project with complete flexibility and freedom. This combination of flexibility, scalability, and performance unlocks a transformative approach to model development at Hexagon, accelerating innovation and powering the next generation of AI-enabled products that help customers build, navigate, and innovate across critical industries.