Artificial Intelligence
Accelerating generative AI applications with a platform engineering approach
Over the past two years, I’ve worked with many customers using generative AI to transform their organizations. Most stall at experimentation, because costs stack up and timelines extend before delivering demonstrable value. A 2023 AWS MIT Chief Data Officer (CDO) Symposium survey backs this up, reporting that while 71% of Chief Data Officers were experimenting with generative AI, only 6% had successfully deployed it in production.
Successful adopters use platform engineering concepts to avoid this trap by building reusable components to accelerate development and control costs. In this post, I will illustrate how applying platform engineering principles to generative AI unlocks faster time-to-value, cost control, and scalable innovation.
Why platform engineering?
Platform engineering isn’t a new concept. In traditional software development, teams have long invested in building functional tooling to accelerate application development. This approach not only saves time and money but also allows development teams to focus on improving application quality by isolating concerns. A dedicated platform engineering team handles the creation and enhancement of these tools, providing expanded functionality, ease of use, and continuous improvement.
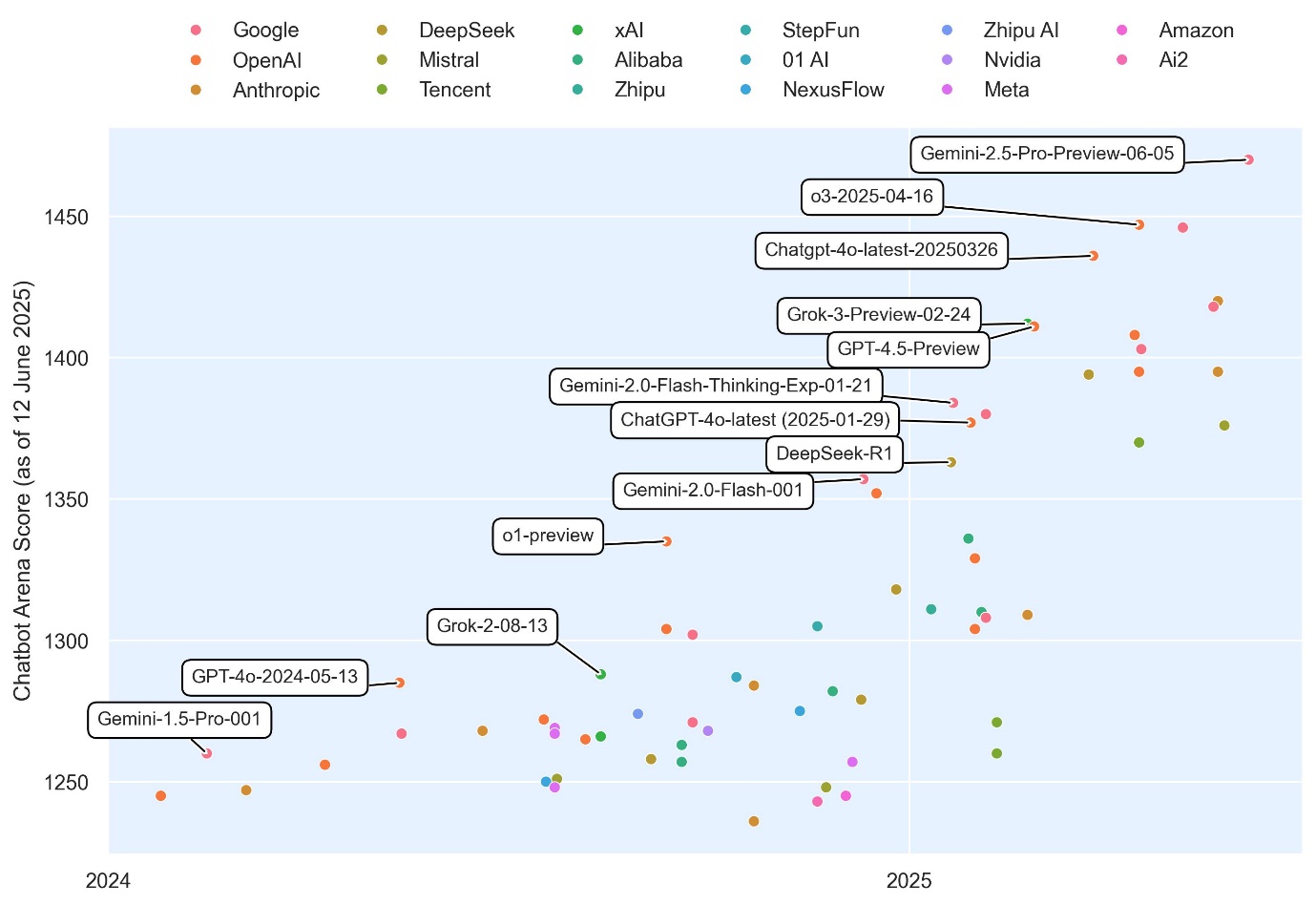
As shown in the following figure, not only are newer large language models launching more frequently, but their benchmark scores are also improving at twice the rate in early 2025 compared to 2024. This accelerating pace of innovation makes platform engineering especially important, enabling organizations to quickly adopt newer, more capable models, integrate the latest advancements, and continuously enhance their applications.
Additionally, a platform engineering approach achieves scalability and efficiency through reusable components and standardized frameworks, enabling rapid deployment of multiple AI models and applications. Standardized processes and tools help ensure consistency and high-quality outputs. Security, compliance, and ethical standards are enhanced with uniform implementation across the platform. Innovation accelerates because AI developers can focus on creative solutions rather than infrastructure. Cost management improves by reducing duplication of effort and resource wastage, making generative AI more affordable. A shared platform fosters collaboration, breaking down silos for more cohesive AI solutions. Finally, intuitive, user-friendly tools reduce the learning curve, enhancing developer productivity.
Anatomy of generative AI applications
A good place to start imagining what a generative AI application would look like is to start from what we already know about majority of applications out there. Pre-generative AI era applications are primarily data handlers in some shape or form, and generally include three layers: a presentation (or frontend) layer, an application logic layer, and a data layer, as shown in the following figure.
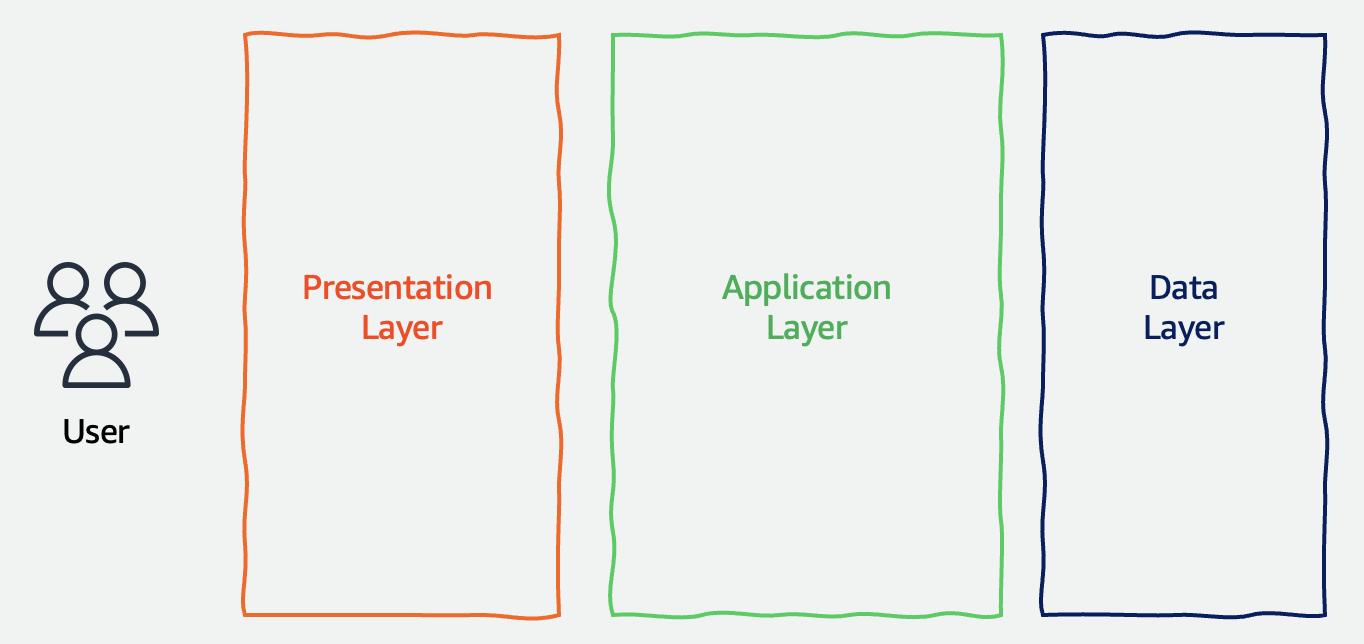
Each layer has a well-defined role—the presentation layer captures user instructions and input data, the application layer supports this instruction by either retrieving data from the data layer (in the case of READ operations) or processing the input before writing it to the data layer, the data layer receives instructions from the application layer and provides persistence to data.
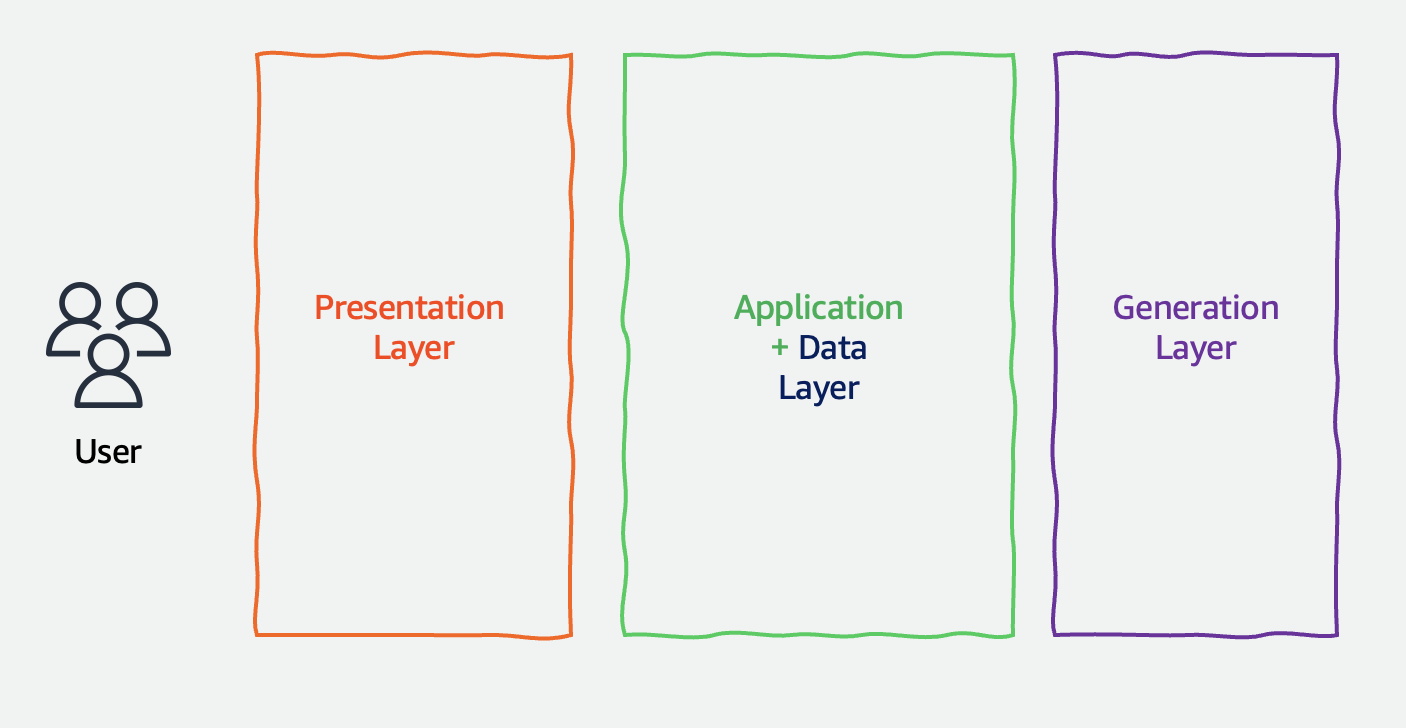
A generative AI application consists of the same basic setup; however, applications don’t just deal with CRUD (CREATE, READ, UPDATE, DELETE) operations with data anymore—generative AI technology replaces the data layer with the generation layer. Data is now part of the wider middle layer, and plays a supporting function to the generation layer, as shown in the following figure.
Platform engineering blueprint for generative AI
With this mental model of a generative AI application, you can start looking at what reusable components you can build with the sound platform engineering principles in Why platform engineering? The following figure is an overview of the components described in this section.

Frontend components
All applications require a great presentation layer, and more specifically to generative AI, you need a presentation layer to cover several key functionalities. If you’re building an interactive application, you probably need session management capabilities so that the application can remember the interactions it had with the user, and over time re-use this data as context to guide future responses. Because such interactions are private, you need sufficient authentication and authorization controls to secure access at an individual basis. These capabilities can be packaged into one of many micro-frontend components that are reusable across all applications, saving time for development and adding a consistent organizational touch to the applications. Finally, interactive frontends are just one channel of interacting with your applications, other times it might make more sense to expose over RESTful or Websocket APIs so that you can embed into websites or internal messaging applications. So, by building a well-defined connectors layer, you can standardize all associated aspects (such as security, monitoring and logging, and documentation) and empower independent experimentation.
Data
To unlock the greatest business value, you need to include organizational data in your generative AI use cases by building a suitable data infrastructure to allow secure access to that data at scale. Data can be grouped either as unstructured data (stored on intranet sites, wikis, and content and knowledge management systems) and structured data (stored in transactional databases, data warehouses, and external software-as-a-service (SaaS)). Making each type of data widely available involves different treatment. For unstructured data, building up a metadata index layer makes it searchable. One way of doing so is to use vectorization, which uses embedding models to convert unstructured data into vector representations and stores them in vector databases. With vector search capabilities, you can build knowledge bases for different organizational domains—such as HR, Finance, and Marketing. These vector databases are progressively evolved to improve search and retrieval accuracy and relevancy with newer technology, chunking strategy and embedding models.
For structured data, while it’s possible for LLMs to query a database by writing their own SQL queries and doing so over preconfigured JDBC or ODBC connections, it’s more scalable and secure to build dedicated interfaces meant for generative AI use. These can be well-defined data APIs designed to handle larger queries using read-replicas, which help insulate primary transactional systems from surges in read requests originating from generative AI applications. While RESTful APIs are an good choice because of their low complexity and speed to deploy, you could also explore GraphQL based APIs, which are more powerful, particularly in querying several datastores at once through a common interface. GraphQL does this using different data resolvers to interface with different databases, even when those databases operate on different underlying technologies (SQL or NoSQL). Generative AI applications can remember the same GraphQL API endpoint and API calls but get access to more data sources as more resolvers are added. On AWS, you can implement both RESTful and GraphQL APIs using Amazon API Gateway and Amazon AppSync respectively.
As increasing amounts of data become available to generative AI applications, setting up strong data governance becomes necessary to track, monitor and secure access to the data. You should apply fine-grained permissions at the data level to makes sure that each generative AI application can only access the data that it (or its users) are allowed to. To implement this at scale, you can use AWS Lake Formation to define and enforce granular access controls on data stored in Amazon Simple Storage Service (Amazon S3) without needing to manage individual AWS Identity and Access Management (IAM) policies manually. It supports table- and column-level permissions, integrates with AWS CloudTrail for auditing, and enables centralized, fine-grained governance across AI workloads sharing the same data lake.
Controls
You can build a unified output control layer that applies across all generative AI applications built in your organization. By doing this, you can apply a consistent set of quality and security policies across all outputs regardless of the language model used. Output controls can be categorized into two main sets. The first set, safety controls, focuses on making sure that responses are non-toxic (toxicity), avoids sensitive topics or keywords (filtering), and limits the exposure of personally identifiable information (PII) (redaction). The second set, quality controls, helps ensure the accuracy of responses, including aspects such as faithfulness, correctness, and relevancy to the original prompt. To uniformly enforce these controls across all generative AI applications, you can implement a standardized enforcement layer. This layer should include a fine-tuned language model trained to sanitize outputs and evaluate responses before they’re made available to users.
Observability
Observability is crucial in maintaining the health and performance of generative AI applications. It involves monitoring, logging, and evaluating model behaviour, user interactions, and system performance to ensure generative AI applications run smoothly and issues are detected promptly. Monitoring includes feedback mechanisms to capture user interactions and record response times, making sure that the system meets performance expectations. Capacity monitoring makes sure that the system scales appropriately under varying loads. Logging involves capturing detailed interaction logs that help in diagnosing issues and understanding user behavior. Evaluation and testing through benchmarking and adversarial testing help assess the robustness and accuracy of the AI models. By implementing comprehensive observability practices, you can maintain high standards of performance and reliability across all generative AI applications. AWS observability services including Amazon CloudWatch, AWS X-Ray, and Amazon OpenSearch Service provide comprehensive monitoring, logging, and analysis capabilities.
Orchestration
As generative AI applications become more sophisticated, they often move beyond single-prompt interactions to workflows that coordinate multiple steps and services. This is where orchestration becomes essential. Complex tasks might involve classical AI components such as optical character recognition (OCR), prompt decomposition, or using specialized language models for sub-tasks. To manage these workflows, AWS Step Functions provides serverless, event-driven orchestration that sequences tasks, handles retries, and maintains state—forming the backbone of AI e logic. A key part of this is prompt management—the ability to track, version, and persist prompt templates, sub-prompts, and intermediate results across executions. Amazon DynamoDB supports this by offering scalable, low-latency storage that enables real-time access to prompt metadata and agent state, providing consistent and traceable workflow behavior.
Reusable logic or API calls can be embedded using AWS Lambda, allowing flexible function execution within chains. As applications adopt agentic workflows, where LLMs function as modular agents with defined roles, Step Functions coordinates agent interactions while DynamoDB serves as persistent context memory.
Together, these components support structured chaining, reliable prompt management, and scalable agentic workflows, enabling modular, resilient, and intelligent orchestration for complex generative AI systems.
Large language models
Large language models are deployed in the generation layer of the application. We have a variety of models to choose from that vary in performance and cost, and these fall into categories of pretrained models, fine-tuned models, and custom models. Each type serves distinct purposes and offers unique advantages depending on the specific requirements of the application.
Pretrained models are the foundation of many generative AI applications. These models are trained on vast amounts of diverse data and can generate coherent and contextually relevant text based on the input prompt. Pretrained models are ideal for general-purpose tasks where extensive domain-specific customization isn’t required. Examples of pretrained models available on Amazon Bedrock include Anthropic’s Claude models and Meta’s Llama models. Orgnaizaitons can use AWS services such as Amazon Comprehend and Amazon Polly to use these pretrained models for tasks such as natural language understanding and text-to-speech conversion. These models provide a strong baseline and can be quickly deployed to perform a wide range of functions, saving time and resources.
While pretrained models are highly versatile, fine-tuned models offer greater specificity and accuracy for particular tasks. Fine-tuning involves taking a pretrained model and further training it on a smaller, domain-specific dataset. This process allows the model to adapt to the nuances and intricacies of specific industries or applications. For instance, an LLM can be fine-tuned to understand medical terminology for healthcare applications or legal jargon for legal solutions. Amazon SageMaker provides end-to-end capabilities for building, training, and deploying machine learning models at scale, which organizations can use to efficiently fine-tune pretrained models for domain-specific precision.
Custom models are built from the ground up to meet highly specialized requirements. These models are trained exclusively on a curated dataset that represents the specific needs and context of the application. Custom models are ideal for scenarios where existing pretrained or fine-tuned models don’t suffice because of the unique nature of the data or the complexity of the tasks. Developing custom models requires significant expertise and resources, but they offer unparalleled accuracy and relevance. AWS provides extensive tools and frameworks through SageMaker that data scientists and machine learning engineers can use to build, train, and deploy custom models tailored to their exact specifications.
Conclusion
The relentless development of ever more capable LLMs, coupled with the rise of specialized models outperforming generalists for specific tasks, underscores the need for a flexible platform engineering approach. Such an approach simplifies the evaluation, integration, and operationalization of new models, enabling organizations to continuously enhance their generative AI applications. Crucially, it facilitates the orchestration of multi-model workflows, stringing together outputs from different specialized models to maximize overall capability. By embracing this platform-centric strategy, companies can future-proof their generative AI initiatives, rapidly realizing innovations while maintaining scalability, consistency, and responsible practices.To further explore the implementation of platform engineering in generative AI applications, consider the following AWS resources:
- Best practices to build generative AI applications on AWS: This blog post delves into various approaches for developing generative AI applications, including prompt engineering, Retrieval-Augmented Generation (RAG), and model customization.
- Achieve operational excellence with well-architected generative AI solutions using Amazon Bedrock This article discusses strategies for deploying generative AI at scale while maintaining operational excellence, emphasizing the importance of a well-architected approach.
- Choosing a generative AI service: This AWS documentation guide helps you select the most suitable AWS generative AI services and tools based on organizational needs.
- Generative AI Application Builder on AWS: This solution speeds up your AI development by incorporating your business data, comparing the performance of LLMs, running multi-step tasks through AI agents, quickly building extensible applications, and deploying them with enterprise-grade architecture.
About the authors
 Thong Seng Foo is a Principal Solutions Architect at Amazon Web Services based in Singapore, specializing in public sector digital transformation and large-scale AI platform design. He advises governments across Asia-Pacific on building secure cloud foundations, digital public infrastructure, and national AI capabilities.
Thong Seng Foo is a Principal Solutions Architect at Amazon Web Services based in Singapore, specializing in public sector digital transformation and large-scale AI platform design. He advises governments across Asia-Pacific on building secure cloud foundations, digital public infrastructure, and national AI capabilities.
 Kamlesh Bhatt is a Senior ProServe Architect at AWS Professional Services based in Singapore. He brings a decade of cloud and data expertise, with a strong focus on artificial intelligence, machine learning and generative Al. Specializing in building machine learning platforms and generative Al products, he helps organisations leverage the power of cloud computing and advanced Al technologies.
Kamlesh Bhatt is a Senior ProServe Architect at AWS Professional Services based in Singapore. He brings a decade of cloud and data expertise, with a strong focus on artificial intelligence, machine learning and generative Al. Specializing in building machine learning platforms and generative Al products, he helps organisations leverage the power of cloud computing and advanced Al technologies.