Artificial Intelligence
Advancing ADHD diagnosis: How Qbtech built a mobile AI assessment Model Using Amazon SageMaker AI
This post is cowritten with Dr. Mikkel Hansen from Qbtech.
The assessment and diagnosis of attention deficit hyperactive disorder (ADHD) has traditionally relied on clinical observations and behavioral evaluations. While these methods are valuable, the process can be complex and time-intensive. Qbtech, founded in 2002 in Stockholm, Sweden, enhances ADHD diagnosis by integrating objective measurements with clinical expertise, helping clinicians make more informed diagnostic decisions. With over one million tests completed across 14 countries, the company’s FDA-cleared and CE-marked products—QbTest (clinic-based) and QbCheck (remote)— have established themselves as widely-adopted tools for objective ADHD testing. Now, Qbtech aims at extending their capabilities with QbMobile, a smartphone-native assessment that uses Amazon Web Services (AWS) to bring clinical-grade ADHD testing directly to patients’ devices.
In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. Qbtech developed and deployed a model that efficiently processes data from smartphone cameras, motion sensors, and test results. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers.
The challenge: Democratizing access to objective ADHD assessment
ADHD affects millions worldwide, yet traditional diagnosis often involves lengthy wait times and multiple clinic visits. While Qbtech’s existing solutions advanced in-clinic and remote webcam-based testing, the company identified an opportunity to expand access through smartphone technology. Qbtech needed to transform raw camera feeds and motion sensor data from diverse smartphone hardware into clinically validated ADHD assessments that could provide the same objective diagnostic value as their established clinical tools. This required processing complex multimodal data streams, extracting meaningful features, and training models that could maintain accuracy across thousands of device variations—all while meeting stringent healthcare regulatory requirements.
Building the artificial intelligence (AI) model: From raw data to clinical insights
Qbtech’s approach to mobile ADHD assessment utilizes machine learning techniques to process and analyze multiple data streams simultaneously. The team selected Binary LightGBM as their primary algorithm for the ADHD assessment model.
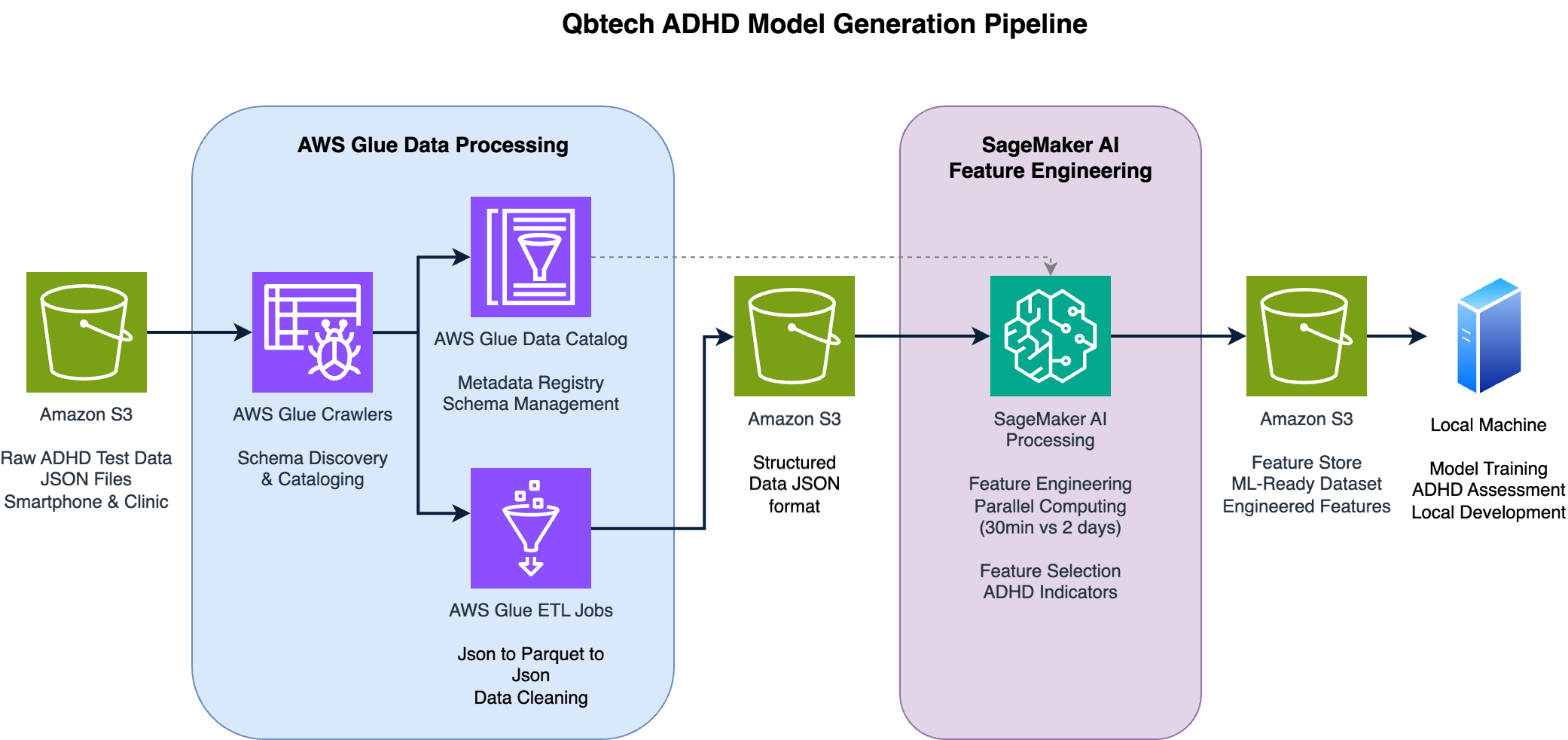
Figure 1: End-to-end data processing and feature engineering pipeline for QbMobile ADHD assessment model
The final model uses 24 input features derived from face tracking, head movement measurements, error patterns during tests, patterns in how users handle their phones, and demography information. This scale was necessary to capture the nuanced patterns in attention, hyperactivity, and impulsivity that characterize ADHD across diverse patient populations. The team utilized three key frameworks: LightGBM as their primary machine learning algorithm, Scikit-learn (sklearn) as their machine learning tool library for data processing and model development, and SHAP (SHapley Additive exPlanations) as their methodology to assess feature importance. These tools were chosen for their flexibility in handling multimodal data and robust deployment capabilities. The team used approximately 2,000 samples, with each sample containing about 50MB of data. Within this dataset, there was a class imbalance with the minority class representing around 20% of the samples. The data was carefully split into train and test sets using stratification based on both diagnosis and demographic features, ensuring equal representation across intersectional groups. Additional consideration was given to grouping since some test takers completed multiple tests. The team implemented a five-fold cross-validation strategy using the same stratification and group approaches. This comprehensive dataset, derived from Qbtech’s decade-plus clinical testing experience, provided the foundation for training models that could generalize across different demographics and device types.
Training performance and evaluation
While the actual model training requires only about one minute of computation time, the resource-intensive component was the transformation of raw samples into structured features. This preprocessing stage is where SageMaker AI managed processing jobs provided substantial acceleration, reducing the processing time for feature extraction and enabling efficient iteration throughout the development lifecycle. To help ensure clinical validity, Qbtech employed rigorous evaluation metrics including sensitivity (85.7%), specificity (74.9%), and PR-AUC (73.2%). The team implemented nested cross-validation with Optuna for hyperparameter tuning across each evaluation fold, optimizing for the sum of sensitivity and specificity rather than PR-AUC to achieve more balanced errors. These metrics and optimization strategies were carefully chosen to align with clinical diagnostic criteria and regulatory requirements for medical devices. The team noted that in the medical sector, there is no absolute ground truth in diagnosing ADHD—the gold standard is when multiple doctors agree on a diagnosis. The real value of Qbtech’s solution is providing consistent, objective data that brings confidence to clinicians’ diagnostic decisions.
Scaling feature engineering with Amazon SageMaker AI
A key improvement in Qbtech’s development process came from implementing parallel processing capabilities on cloud infrastructure. By implementing asynchronous processing that enables each test to run in parallel rather than sequentially, the team could perform downloading, JSON parsing, and feature transformation in parallel across multiple processes. The feature engineering pipeline begins by converting raw data into time series for each data source, then generating various features from these time series. For instance, face position data is processed to compute statistics such as minimum, maximum, and mean movement within 30-second windows. To achieve the reduction in processing time from 2 days to 30 minutes, Qbtech implemented a parallel processing approach using Python’s multiprocessing capabilities on Amazon Sagemaker AI:
This function creates a pool of workers equal to the number of central processing unit (CPU) cores available on the compute instance—for example, on an ml.m5.8xlarge instance with 32 cores, this means 32 files can be processed simultaneously. Each worker calls uuid_to_features, which handles retrieving the JSON test file from Amazon S3, parsing the 50MB of accelerometer and face tracking data, and performing the actual feature computation to extract the clinical indicators. The results from all workers are then combined into a single dataset using pandas’ concat function.
This parallel processing approach enabled a 96% reduction in computation time, allowing the team to iterate rapidly during model development while maintaining the reliability needed for healthcare applications. Qbtech reported no hardware failures or interruptions during their development process, allowing them to focus on model improvement rather than infrastructure management.
Data pipeline: From smartphone to clinical decision
The data pipeline begins with raw smartphone sensor data in various formats. The raw ADHD test data comes in JSON format, containing accelerometer readings, face tracking data, and tests results. AWS Glue jobs handle the initial extraction and transformation of this heterogeneous data into a standardized format suitable for analysis. These transformations help maintain data quality and consistency across different device types and operating systems, a critical requirement for preserving assessment accuracy. Glue jobs transform formats from raw files into a standard one, converting legacy formats to new formats and making the file structure more friendly for analysis (e.g., calculating average values from arrays).
Feature extraction and selection
The feature engineering process extracts meaningful clinical indicators from raw sensor data. Qbtech extracts approximately 200 features from the raw data, with only 24 making it to the final model. This reduction from raw features to model inputs was achieved through a systematic manual selection process, where histograms per label were analyzed to check for separation between classes. The team implemented an iterative approach, adding the most promising features incrementally while monitoring improvements in cross-validation performance. SHAP analysis was used to verify that features interacted with the diagnosis in clinically meaningful ways—for example, confirming that higher values in movement features corresponded to increased likelihood of ADHD. The team also eliminated features with high correlation as another technique to ensure the selected features were independently contributing to the diagnosis. This methodical feature selection process reflects the domain knowledge encoded into the model development. A key challenge was reducing long time series into tabular features while still capturing the essential signals. The team developed techniques to extract clinically relevant patterns from face tracking and motion sensor data, focusing on indicators that correlate with ADHD symptoms.
End-to-end latency
For a clinical tool to be practical, results must be available quickly. Qbtech’s pipeline delivers results in under a minute from data collection to model inference. This rapid turnaround supports real-time clinical decision-making and improves the patient experience.
Quantifiable impact: Development efficiency gains
The primary improvement came in time-to-result for feature engineering, dropping from two days to just 30 minutes through parallel processing. This 96% reduction in wall time enabled the team to complete 20 development iterations much more efficiently, significantly accelerating the model development cycle.
Clinical impact: Comparative clinical performance
The clinical validation of QbMobile against Qbtech’s established products shows promising results. Performance metrics indicate that the smartphone-based assessment maintains the high clinical standards of Qbtech’s existing solutions. The shift to mobile assessment has changed the care delivery model. For providers that are only remote-based, QbMobile allows for a 100% remote diagnostic process. It enables patients who would otherwise not be able to participate in an in-clinic assessment due to logistical challenges to receive proper evaluation. This transition reduces barriers to diagnosis and enables more frequent monitoring of treatment effectiveness.
Deployment and continuous improvement
The production deployment uses AWS services for reliability and scale. Qbtech packages the trained model, together with Python code, into a Docker image. The Docker image is then deployed to AWS ECR through GitHub releases that trigger a GitHub Action. Finally, the SageMaker AI endpoint is deployed by Terraform together with the rest of their backend infrastructure. To maintain consistent performance across devices, Qbtech conducts regular validation checks during development, examining whether device models affect assessment performance in any unintended ways.
Security and monitoring for healthcare compliance
Qbtech’s deployment on AWS incorporates comprehensive security and monitoring measures essential for healthcare applications. All data is encrypted at rest, and the system maintains patient privacy by keeping data anonymous —no individual can be identified with data stored at Qbtech. The system enforces multi-factor authentication and continuously monitors service availability, performance metrics, and potential security threats. All system access is logged and monitored, with automatic flagging of suspicious activity. This approach helps meet healthcare security requirements while maintaining the reliability needed for clinical workflows.
Looking Forward: Scaling for global impact
Qbtech’s infrastructure strategy anticipates QbMobile’s growing adoption worldwide. The team plans to use the elastic scaling capabilities of SageMaker AI to address any performance bottlenecks that emerge with increased usage. For model enhancement, Qbtech is implementing annual update cycles that go beyond simple retraining. As their dataset expands, they’ll incorporate new features that capture additional behavioral patterns, continuously improving diagnostic accuracy and robustness.
Future research directions
Building on their current work, Qbtech is exploring additional data streams and sensor inputs to further enhance assessment accuracy and expand diagnostic capabilities. They are also in dialogue with regulatory authorities on how to implement a continuous improvement plan in model performance, which could potentially include using different models like neural networks. The insights from over 1 million completed tests provide a unique foundation for feature calibration and threshold definitions. This data-driven approach enables mobile assessments to benefit from the company’s extensive clinical experience.
Looking beyond ADHD, the platform shows promise for broader applications. Qbtech believes that QbMobile enables researchers to access data types they haven’t had before or had difficulties obtaining. Through research collaborations, they aim to explore the full potential of QbMobile, Machine Learning, and additional features to impact ADHD and potentially other conditions in the future.
Conclusion
Qbtech’s implementation of QbMobile on AWS demonstrates meaningful progress towards accessible, objective ADHD assessment. By leveraging the parallel processing capabilities of Amazon SageMaker AI, and the data transformation capabilities of AWS Glue, they have reduced feature engineering time by 96% while building a clinically validated AI model that runs on smartphones worldwide.
The impact extends beyond technical metrics: patients can now access clinical-grade ADHD assessments from their devices, reducing wait times and improving access to care. For healthcare providers, the standardized, objective data enables more confident diagnoses and better treatment monitoring.
As mental health challenges continue to grow globally, Qbtech’s use of cloud-based AI shows how modern infrastructure can expand access to specialized healthcare services. Their approach provides insights for other healthcare organizations looking to use AI and cloud computing to improve patient outcomes at scale.
To learn more about building healthcare AI solutions on AWS, explore Amazon SageMaker AI and AWS Glue documentation, or contact AWS healthcare specialists to discuss your specific use case.
About the authors
 Antonio Martellotta is a Senior Solutions Architect at AWS. He advices Private Equity firms and their portfolio companies on digital value creation leveraging cloud and AI. His main areas of expertise are data strategy, data analytics, and Generative AI. He holds a bachelor’s degree in Biomedical Engineering and a triple master degree in Smart Systems Integrations.
Antonio Martellotta is a Senior Solutions Architect at AWS. He advices Private Equity firms and their portfolio companies on digital value creation leveraging cloud and AI. His main areas of expertise are data strategy, data analytics, and Generative AI. He holds a bachelor’s degree in Biomedical Engineering and a triple master degree in Smart Systems Integrations.
 Dr. Mikkel Hansen is a Danish-trained medical doctor and seasoned healthcare executive. Since October 2020, he has served as Medical Director and CMO at Qbtech, spearheading the integration of objective, data-driven technologies—such as QbTest and QbCheck—into ADHD diagnosis and management. Dr. Hansen is committed to improving diagnostic confidence and efficiency in ADHD care worldwide. Beyond clinical digital health innovation, Dr. Hansen engages directly with authorities—including the U.S. DEA, NICE, FDA, and EMA—helping to shape policy around safe ADHD diagnosis and stimulant use.
Dr. Mikkel Hansen is a Danish-trained medical doctor and seasoned healthcare executive. Since October 2020, he has served as Medical Director and CMO at Qbtech, spearheading the integration of objective, data-driven technologies—such as QbTest and QbCheck—into ADHD diagnosis and management. Dr. Hansen is committed to improving diagnostic confidence and efficiency in ADHD care worldwide. Beyond clinical digital health innovation, Dr. Hansen engages directly with authorities—including the U.S. DEA, NICE, FDA, and EMA—helping to shape policy around safe ADHD diagnosis and stimulant use.