Have you considered introducing anomaly detection technology to your business? Anomaly detection is a technique used to identify rare items, events, or observations which raise suspicion by differing significantly from the majority of the data you are analyzing. The applications of anomaly detection are wide-ranging including the detection of abnormal purchases or cyber intrusions in banking, spotting a malignant tumor in an MRI scan, identifying fraudulent insurance claims, finding unusual machine behavior in manufacturing, and even detecting strange patterns in network traffic that could signal an intrusion.
There are many commercial products to do this, but you can easily implement an anomaly detection system by using Amazon SageMaker, AWS Glue, and AWS Lambda. Amazon SageMaker is a fully-managed platform to help you quickly build, train, and deploy machine learning models at any scale. AWS Glue is a fully-managed ETL service that makes it easy for you to prepare your data/model for analytics. AWS Lambda is a well-known a serverless real-time platform. Using these services, your model can be automatically updated with new data, and the new model can be used to alert for anomalies in real time with better accuracy.
In this blog post I’ll describe how you can use AWS Glue to prepare your data and train an anomaly detection model using Amazon SageMaker. For this exercise, I’ll store a sample of the NAB NYC Taxi data in Amazon DynamoDB to be streamed in real time using an AWS Lambda function.
The solution that I describe provides the following benefits:
- You can make the best use of existing resources for anomaly detection. For example, if you have been using Amazon DynamoDB Streams for disaster recovery (DR) or other purposes, you can use the data in that stream for anomaly detection. In addition, stand-by storage usually has low utilization. The data in low awareness can be used for training data.
- You can automatically retrain the model with new data on a regular basis with no user intervention.
- You can make it easy to use the Random Cut Forest built-in Amazon SageMaker algorithm. Amazon SageMaker offers flexible distributed training options that adjust to your specific workflows in a secure and scalable environment.
Solution architecture
The following diagram shows the overall architecture of the solution.
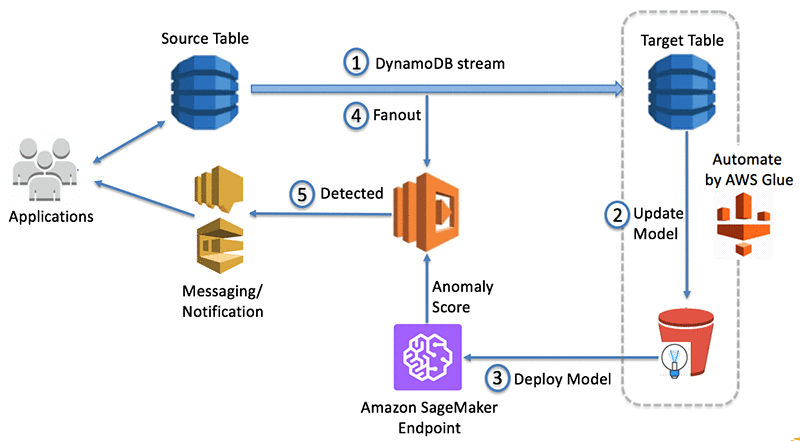
The steps that data follows through the architecture are as follows:
- Source DynamoDB captures changes and stores them in a DynamoDB stream.
- AWS Glue job regularly retrieves data from target DynamoDB table and runs a training job using Amazon SageMaker to create or update model artifacts on Amazon S3.
- The same AWS Glue job deploys the updated model on the Amazon SageMaker endpoint for real-time anomaly detection based on Random Cut Forest.
- AWS Lambda function polls data from the DynamoDB stream and invokes the Amazon SageMaker endpoint to get inferences.
- The Lambda function alerts user applications after anomalies are detected.
This blog post consists of two sections. The first section, “Building the auto-updating model,” explains how the previous steps 1, 2, and 3 can be automated using AWS Glue. All of the sample scripts in this section run in one AWS Glue job. The second section, “Detecting anomalies in real time,” shows how the AWS Lambda function processes previous steps 4 and 5 for anomaly detection.
Building the auto-updating model
This section explains how AWS Glue reads a DynamoDB table and automatically trains and deploys a model of Amazon SageMaker. I assume that the DynamoDB stream is already enabled and DynamoDB items are being written to the stream. If you have not set these up yet, you can reference these documents for more information: Capturing Table Activity with DynamoDB Streams, DynamoDB Streams and AWS Lambda Triggers, and Global Tables.
In this example, a DynamoDB table (“taxi_ridership”) in the us-west-2 Region is replicated to another DynamoDB table with same name in us-east-1 Region using the Global Tables of DynamoDB.

Create an AWS Glue job and prepare data
To prepare data for model training, we’ll store our data in DynamoDB. The AWS Glue job retrieves data from the target DynamoDB table by using create_dynamic_frame_from_options() with a dynamodb connection_type argument. While you pull data from DynamoDB, we recommend that you choose only the necessary columns for model training and write them into Amazon S3 as CSV files. You can do this by using the ApplyMapping.apply() function in AWS Glue. In this example, only the transaction_id and ridecount columns are mapped.
In addition, when you run the write_dynamic_frame.from_options function, you need to add this option, format_options = {"writeHeader": False , "quoteChar": "-1" }, because the column’s name and double quotation marks (‘”‘) are not necessary for model training.
Finally, the AWS Glue job should be created in the same Region (for this blog post it’s us-east-1 ) where the DynamoDB table resides. For more information on creating an AWS Glue job. See Adding Jobs in AWS Glue.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
my_region = '<region name>'
my_bucket = '<bucket name>'
my_project = '<project name>'
my_train_data = "s3://{}/{}/taxi-ridership-rawdata/".format(my_bucket , my_project )
my_dynamodb_table = "taxi_ridership"
## Read raw(source) data from target DynamoDB
raw_data_dyf = glueContext.create_dynamic_frame_from_options("dynamodb", {"dynamodb.input.tableName" : my_dynamodb_table , "dynamodb.throughput.read.percent" : "0.7" } , transformation_ctx="raw_data_dyf" )
## Write necessary columns into S3 as CSV format for creating Random Cut Forest(RCF) model
selected_data_dyf = ApplyMapping.apply(frame = raw_data_dyf, mappings = [("transaction_id", "string", "transaction_id", "string"), ("ridecount", "string", "ridecount", "string")], transformation_ctx = "selected_data_dyf")
datasink = glueContext.write_dynamic_frame.from_options(frame=selected_data_dyf , connection_type="s3", connection_options={ "path": my_train_data }, format="csv", format_options = {"writeHeader": False , "quoteChar": "-1" }, transformation_ctx="datasink")
This AWS Glue job writes CSV files in the specified path on Amazon S3 ( “s3://<bucket name>/<project name>/taxi-ridership-rawdata/” ).

Run training job and update model
After the data is prepared, you can run a training job on Amazon SageMaker. To submit the training job to Amazon SageMaker the boto3 package, which is automatically bundled with your AWS Glue ETL script, should be imported. This enables you to use the low-level SDK for Python in the AWS Glue ETL script. To learn more about how to create a training job, see Create a Training Job.
The create_training_job function creates model artifacts on the S3 path you specified. Those model artifacts are required for creating the model in the next step.
## Execute training job with CSV data and create model artifacts for RCF
import boto3
from time import gmtime, strftime
sagemaker = boto3.client('sagemaker', region_name= my_region)
job_name = 'randomcutforest-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
sagemaker_role = "arn:aws:iam::<account id>:role/service-role/<AmazonSageMaker-ExecutionRole-Name>"
containers = {
'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/randomcutforest:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/randomcutforest:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/randomcutforest:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/randomcutforest:latest'}
image = containers[my_region]
artifacts_location = 's3://{}/{}/artifacts'.format(my_bucket , my_project )
print('myINFO : training artifacts will be uploaded to: {}'.format(artifacts_location))
create_training_params = \
{
"AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" },
"RoleArn": sagemaker_role, "OutputDataConfig": {"S3OutputPath": artifacts_location },
"ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.xlarge", "VolumeSizeInGB": 50 },
"TrainingJobName": job_name,
"HyperParameters": { "num_samples_per_tree": "200", "num_trees": "50", "feature_dim": "2" },
"StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 },
"InputDataConfig": [
{
"ChannelName": "train",
"ContentType": "text/csv;label_size=0",
"DataSource": {
"S3DataSource": {"S3DataType": "S3Prefix", "S3Uri": my_train_data, "S3DataDistributionType": "ShardedByS3Key" }
},
"CompressionType": "None",
"RecordWrapperType": "None"
}
]
}
sagemaker.create_training_job(**create_training_params)
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print('myINFO : Status of {} traning job ==> {}'.format(job_name , status ))
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name)
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("myINFO : Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('myINFO : Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')
## Create Model from model artifacts
model_name=job_name
print("myINFO : Model name - {}".format(model_name))
info = sagemaker.describe_training_job(TrainingJobName=job_name)
model_data = info['ModelArtifacts']['S3ModelArtifacts']
primary_container = {'Image': image, 'ModelDataUrl': model_data }
create_model_response = sagemaker.create_model(
ModelName = model_name,
ExecutionRoleArn = sagemaker_role,
PrimaryContainer = primary_container)
print("myINFO : Created Model ARN : {}".format( create_model_response['ModelArn']))
You can see a new model name with date format on the Amazon SageMaker console after model creation is successful.

Execute batch transform and obtain cut-off score
We can now use this trained model to compute anomaly scores for each of the training data points. As the amount of data to work with is big, I decided to use Amazon SageMaker Batch Transform. Batch transform uses a trained model to get inferences for an entire dataset in Amazon S3, and saves the inferences in an S3 bucket that you specify when you create a batch transform job.
After getting the inferences (=anomaly scores) on each data point, we need to obtain a score_cutoff value to be used for real-time anomaly detection. To make it simple, I used a standard technique for classifying anomalies. Anomaly scores outside three standard deviations from the mean score are considered anomalous.
## Execute Batch Transform in order to calculate anomaly scores and the value of score cutoff.
## score cutoff will be used in Lambda function in real time to identify anomalous transaction
import time
batch_job_name = 'Batch-Transform-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
batch_output = "s3://{}/{}/batch_output/".format(my_bucket , my_project )
request = {
"TransformJobName": batch_job_name,
"ModelName": model_name,
"MaxConcurrentTransforms": 1,
"TransformOutput": { "S3OutputPath": batch_output },
"TransformInput" : {
"ContentType": "text/csv;label_size=0",
"DataSource" : {
"S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": my_train_data }
}
},
"TransformResources": { "InstanceType": "ml.m4.xlarge","InstanceCount": 1 }
}
response = sagemaker.create_transform_job(**request)
batch_status = 'InProgress'
while batch_status == 'InProgress':
batch_status = sagemaker.describe_transform_job( TransformJobName=batch_job_name)['TransformJobStatus']
print("myINFO : Batch job {} in Progress ".format( batch_job_name ))
time.sleep(10)
if batch_status == 'Failed':
message = sagemaker.describe_transform_job(TransformJobName=batch_job_name)['FailureReason']
print('myINFO : Transforming job failed with the following error: {}'.format(message))
raise Exception('Transforming job failed')
## Calculate score_cutoff from the result of Batch-Transform
from pyspark.sql.functions import mean, stddev
from decimal import Decimal
all_scores_dfy = glueContext.create_dynamic_frame_from_options("s3", {'paths': [ batch_output ]}, format="json", transformation_ctx = "all_scores_dfy" ).toDF()
score_mean = all_scores_dfy.agg(mean(all_scores_dfy["score"]).alias("mean")).collect()[0]["mean"]
score_stddev = all_scores_dfy.agg(stddev(all_scores_dfy["score"]).alias("stddev")).collect()[0]["stddev"]
score_cutoff = Decimal( str( score_mean + 3*score_stddev ) )
print("myINFO : RFC score cutoff : {}".format( score_cutoff))
The history of the batch transform job can be found in the Batch transform jobs menu on the Amazon SageMaker console.

Deploy model and update cut-off score
The final step in the AWS Glue ETL script is to deploy the updated model on the Amazon SageMaker endpoint and upload the obtained score_cutoff value in the DynamoDB table for real-time anomaly detection. The Lambda function queries this score_cutoff value on DynamoDB to compare it with anomaly scores of new transactions.
## Create Endpoint Configuration for realtime service
endpoint_config_name = 'randomcutforest-endpointconfig-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
create_endpoint_config_response = sagemaker.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{ 'InstanceType':'ml.m4.xlarge', 'InitialInstanceCount':1, 'ModelName':model_name, 'VariantName':'AllTraffic'}]
)
print("myINFO : Endpoint Config Arn: " + create_endpoint_config_response['EndpointConfigArn'] )
## Create/Update Endpoint with new configuration that has updated model.
endpoint_name = 'randomcutforest-endpoint'
endpoint_status = ""
try:
endpoint_status = sagemaker.describe_endpoint(EndpointName=endpoint_name)['EndpointStatus']
except Exception as e :
endpoint_status = "NotInService"
print("myINFO : randomcutforest-endpoint Status: " + status)
if endpoint_status == 'InService':
update_endpoint_response = sagemaker.update_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name)
try:
sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name)
finally:
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("myINFO : Update endpoint {} ended with {} status: ".format( resp['EndpointArn'] , status ) )
if status != 'InService':
message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason']
print('myINFO : Endpoint update failed with the following error: {}'.format(message))
raise Exception('Endpoint update did not succeed')
else:
create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name)
try:
sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name)
finally:
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("myINFO : Create endpoint {} ended with {} status: ".format( resp['EndpointArn'] , status ) )
if status != 'InService':
message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason']
print('myINFO : Endpoint creation failed with the following error: {}'.format(message))
raise Exception('Endpoint creation did not succeed')
## Add the score_cutoff value into DynamoDB
## score_cutoff will be queried by Lambda function for real time abnormal detection
dynamodb_table = boto3.resource('dynamodb', region_name= my_region).Table('anomaly_cut_off')
dynamodb_table.put_item(Item= {'data_kind': my_dynamodb_table ,'update_time': strftime("%Y%m%d%H%M%S", gmtime()), 'score_cutoff': score_cutoff })
print('myINFO : New score_cutoff value has been updated in DynamoDB table.')
## Delete Temporary data to save cost.
s3 = boto3.resource('s3').Bucket(my_bucket )
s3.objects.filter(Prefix="{}/taxi-ridership-rawdata".format(my_project)).delete()
s3.objects.filter(Prefix="{}/batch_output".format(my_project)).delete()
print('myINFO : Temporary S3 objects have been deleted.')
## End job
job.commit()
Now the Amazon SageMaker endpoint is created, and the AWS Glue job has been completed. You can check the detailed log of the AWS Glue job by choosing the Logs link in the AWS Glue console.

The score_cutoff value is stored in a DynamoDB table whose partition key is taxi-ridership and whose range key is a latest update time.

Schedule the AWS Glue job
Those previous scripts run in the same AWS Glue job and AWS Glue supports a time-based schedule by creating a trigger. You can retrain model with new data on regular basis if you define a time-based schedule and associate it with your job. I do not think the model should be updated too frequently. Weekly or bi-weekly renewal should be enough.

Detecting anomalies in real time
This section discusses how to detect anomalous transactions in real time from an AWS Lambda function. You need to create an AWS Lambda function to poll the DynamoDB stream. While you create the AWS Lambda function, you can use the “dynamodb-process-stream-python3” blueprint for quick implementation. The Lambda function with the blueprint can be integrated with the DynamoDB table that you specify. The blueprint provides the basic Lambda code.

Get an anomaly score on each data point
I’ll briefly explain the code in the Lambda function. It filters only INSERT and MODIFY events because they are new data. The Lambda function adds them into instances array in order to get inferences for an entire events in the array. The Amazon SageMaker Random Cut Forest algorithm accepts multiple records as input requests and return multi-record inferences to support a mini-batch predictions. To learn more, see Common Data Formats—Inference.
import json
import boto3
from boto3.dynamodb.conditions import Key, Attr
print("Starting Lambda Function.... ")
sagemaker = boto3.client('sagemaker-runtime', region_name ='<region name>' )
dynamodb_table = boto3.resource('dynamodb', region_name='us-east-1').Table('anomaly_cut_off')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
transaction_data = {} # key : transaction_id / value : ridecount
for record in event['Records']:
## filter only INSERT or MODIFY event and add to "transaction_data" dictionary
if record['eventName'] == "INSERT" or record['eventName'] == "MODIFY":
transaction_id = record['dynamodb']['NewImage']['transaction_id']['S']
ridecount = record['dynamodb']['NewImage']['ridecount']['S']
transaction_data[transaction_id] = ridecount
print( "transaction_data: " + str(transaction_data ))
features=[]
features_dic={}
instances=[]
instances_dic={} # example, {'instances': [{'features': ['10231', '3837']}, {'features': ['10232', '10844']}]}
for key in transaction_data.keys():
features.append(key)
features.append(transaction_data[key])
features_dic["features"] = features
instances.append(features_dic)
features=[]
features_dic={}
instances_dic["instances"] = instances
transaction_json = json.dumps(instances_dic) # To make argument format for invoke_endpoint method.
Alert anomalous transaction
An array of features can be submitted to the sagemaker.invoke_endpoint function. It returns an array of scores corresponding to each feature in the instances array. We can compare each score in response to the latest value of score_cutoff retrieved from the DynamoDB table. If the anomaly score of a new transaction is larger than the value of score_cutoff, that transaction is considered to be anomalous. Then the Lambda function will alert the user application.
response = sagemaker.invoke_endpoint( EndpointName='randomcutforest-endpoint', Body=transaction_json , ContentType='application/json' )
scores_result = json.loads(response['Body'].read().decode())
print("Result score : "+ str(scores_result)) # return an array of score
response = dynamodb_table.query(
Limit = 1,
ScanIndexForward = False,
KeyConditionExpression=Key('data_kind').eq('taxi_ridership') & Key('update_time').lte('99990000000000')
)
socre_cutoff = response['Items'][0]['score_cutoff']
print("socre cutoff : " + str(socre_cutoff) )
for index in range(len(scores_result['scores'])):
if scores_result['scores'][index]['score'] > socre_cutoff:
print("Detected abnormal transaction ID : {} , Ridecount : {}".format(instances[index]['features'][0], instances[index]['features'][1] ))
## Add your codes to send a notification
return 'Successfully processed {} records.'.format(len(event['Records']))
The following is an example of an output log in Amazon CloudWatch. Two transactions (10231 and 21101) were created in DynamoDB, and those transaction triggered a Lambda function as new events. The anomaly score of transaction of 21101 is 3.6189932108. That is larger than the cut-off value (1.31462299965) in the DynamoDB table, so the transaction is detected to be anomalous.

Conclusion
In this blog post, I introduced an example of how to build an anomaly detection system on Amazon DynamoDB Streams by using Amazon SageMaker, AWS Glue, and AWS Lambda.
In addition, you can adapt this example to your specific use case because AWS Glue is very flexible based on user’s script and continues to add new data source. Other kinds of data sources and streams can be applied to this architecture because AWS Lambda function also works with many other AWS streaming services.
Finally, I hope this post helps you reduce business risks and save cost while adopting anomaly detection system.
About the Author
 Yong Seong Lee is a Cloud Support Engineer for AWS Big Data Services. He is interested in every technology related to Big Data/Data Analysis/Machine Learning and helping customers who have difficulties in using AWS services. His motto is “Enjoy life, be curious and have maximum experience.”
Yong Seong Lee is a Cloud Support Engineer for AWS Big Data Services. He is interested in every technology related to Big Data/Data Analysis/Machine Learning and helping customers who have difficulties in using AWS services. His motto is “Enjoy life, be curious and have maximum experience.”