Artificial Intelligence
Category: Analytics

How LinqAlpha assesses investment theses using Devil’s Advocate on Amazon Bedrock
LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.

Agentic AI for healthcare data analysis with Amazon SageMaker Data Agent
On November 21, 2025, Amazon SageMaker introduced a built-in data agent within Amazon SageMaker Unified Studio that transforms large-scale data analysis. In this post, we demonstrate, through a detailed case study of an epidemiologist conducting clinical cohort analysis, how SageMaker Data Agent can help reduce weeks of data preparation into days, and days of analysis development into hours—ultimately accelerating the path from clinical questions to research conclusions.

Build a serverless AI Gateway architecture with AWS AppSync Events
In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.

How CLICKFORCE accelerates data-driven advertising with Amazon Bedrock Agents
In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process.

How Palo Alto Networks enhanced device security infra log analysis with Amazon Bedrock
Palo Alto Networks’ Device Security team wanted to detect early warning signs of potential production issues to provide more time to SMEs to react to these emerging problems. They partnered with the AWS Generative AI Innovation Center (GenAIIC) to develop an automated log classification pipeline powered by Amazon Bedrock. In this post, we discuss how Amazon Bedrock, through Anthropic’ s Claude Haiku model, and Amazon Titan Text Embeddings work together to automatically classify and analyze log data. We explore how this automated pipeline detects critical issues, examine the solution architecture, and share implementation insights that have delivered measurable operational improvements.

How dLocal automated compliance reviews using Amazon Quick Automate
In this post, we share how dLocal worked closely with the AWS team to help shape the product roadmap, reinforce its role as an industry innovator, and set new benchmarks for operational excellence in the global fintech landscape.

Advancing ADHD diagnosis: How Qbtech built a mobile AI assessment Model Using Amazon SageMaker AI
In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers.

Unlocking video understanding with TwelveLabs Marengo on Amazon Bedrock
In this post, we’ll show how the TwelveLabs Marengo embedding model, available on Amazon Bedrock, enhances video understanding through multimodal AI. We’ll build a video semantic search and analysis solution using embeddings from the Marengo model with Amazon OpenSearch Serverless as the vector database, for semantic search capabilities that go beyond simple metadata matching to deliver intelligent content discovery.
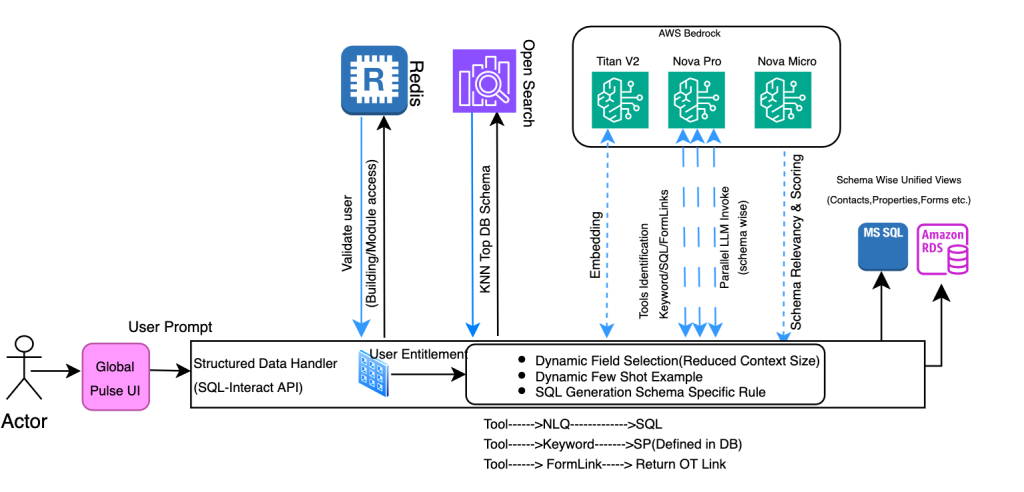
How CBRE powers unified property management search and digital assistant using Amazon Bedrock
In this post, CBRE and AWS demonstrate how they transformed property management by building a unified search and digital assistant using Amazon Bedrock, enabling professionals to access millions of documents and multiple databases through natural language queries. The solution combines Amazon Nova Pro for SQL generation and Claude Haiku for document interactions, achieving a 67% reduction in processing time while maintaining enterprise-grade security across more than eight million documents.
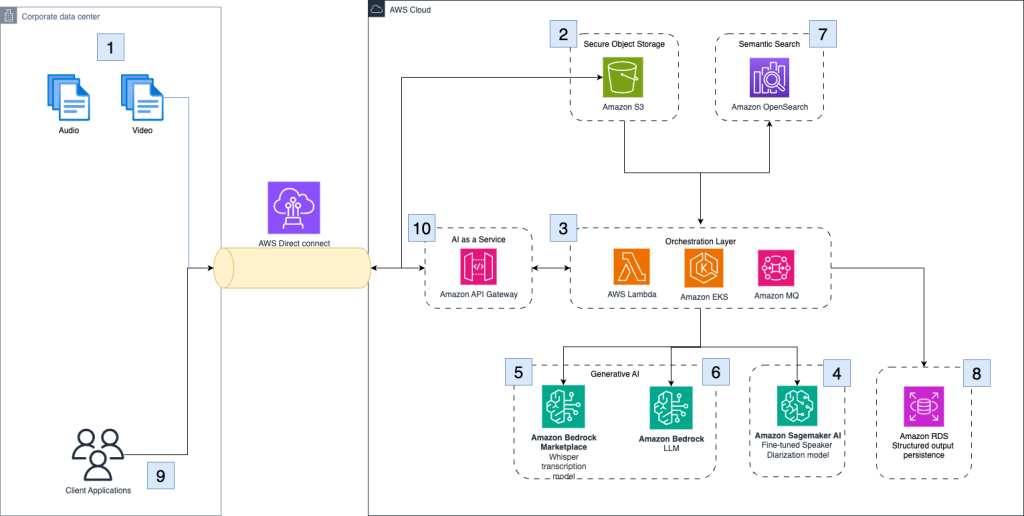
How Clario automates clinical research analysis using generative AI on AWS
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.