Artificial Intelligence
Category: Generative AI

Integrating AWS API MCP Server with Amazon Quick using Amazon Bedrock AgentCore Runtime
This post shows you how to use Amazon Bedrock AgentCore Runtime with Model Context Protocol (MCP) support to connect Amazon Quick with AWS services through the AWS API MCP Server, creating a conversational AI assistant that translates natural language into AWS Command Line Interface (AWS CLI) commands, without the need to switch between tools during critical moments.

Break the context window barrier with Amazon Bedrock AgentCore
In this post, you will learn how to implement Recursive Language Models (RLM) using Amazon Bedrock AgentCore Code Interpreter and the Strands Agents SDK. By the end, you will know how to process documents of varying lengths, with no upper bound on context size, use Bedrock AgentCore Code Interpreter as persistent working memory for iterative document analysis, and orchestrate sub-large language model (sub-LLM) calls from within a sandboxed Python environment to analyze specific document sections.

Build an AI-powered recruitment assistant using Amazon Bedrock
In this post, we demonstrate how to build an AI-powered recruitment assistant using Amazon Bedrock that brings efficiencies to candidate evaluation, generates personalized interview questions, and provides data-driven insights for human hiring decisions. This post presents a reference architecture for learning purposes — not a production-ready solution. Amazon Bedrock and the AWS services used here are general-purpose tools that customers can combine to support a wide variety of use cases, including recruitment workflows. The architecture demonstrates one possible approach; customers should adapt it to their specific requirements.
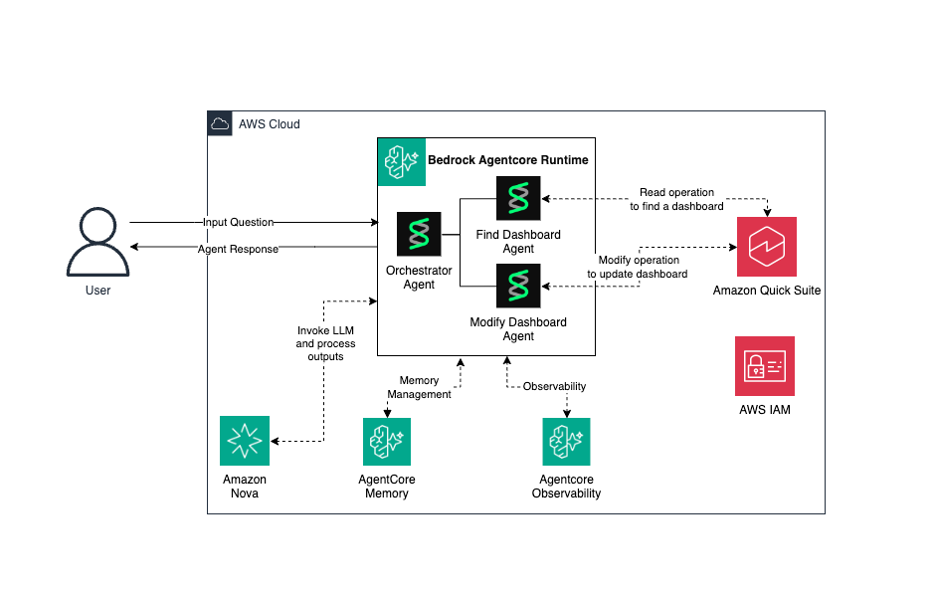
Build AI-powered dashboard automation agents with NLP on Amazon Bedrock AgentCore
This solution combines the power of Amazon Bedrock AgentCore, Strands Agents, and Amazon Quick transforms to deliver a secure, scalable, and intelligent system for building and operating AI agents while transforming data into actionable business insights.
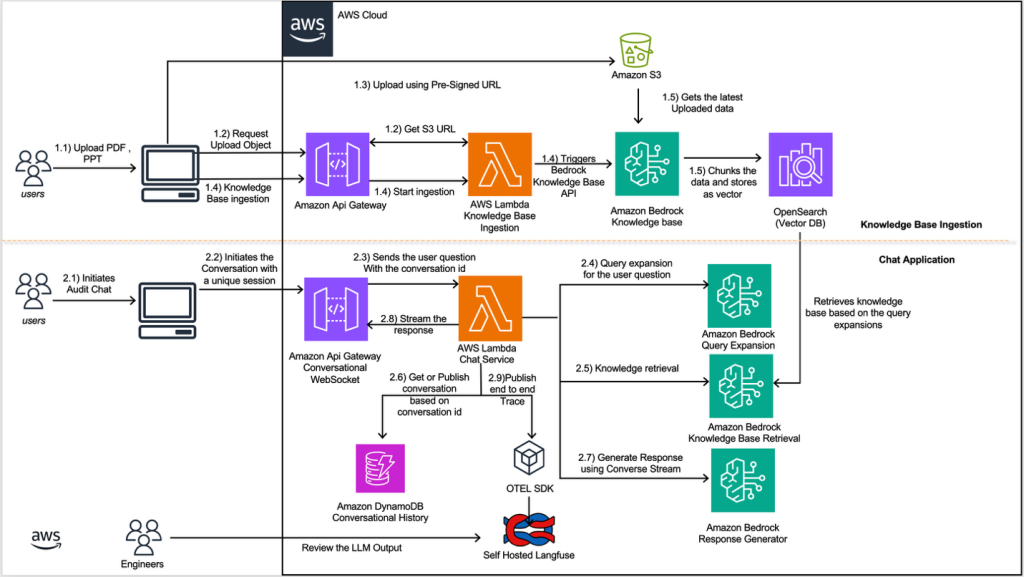
How Amazon Finance streamlines regulatory inquiries by using generative AI on AWS
In this post, we demonstrate how Amazon FinTech teams are using Amazon Bedrock and other AWS services to build a scalable AI application to transform how regulatory inquiries are handled. Each team using this solution creates and maintains its own dedicated knowledge base, populated with that team’s specific documents and reference materials.

Overcoming reward signal challenges: Verifiable rewards-based reinforcement learning with GRPO on SageMaker AI
In this post, you will learn how to implement reinforcement learning with verifiable rewards (RLVR) to introduce verification and transparency into reward signals to improve training performance. This approach works best when outputs can be objectively verified for correctness, such as in mathematical reasoning, code generation, or symbolic manipulation tasks. You will also learn how to layer techniques like Group Relative Policy Optimization (GRPO) and few-shot examples to further improve results. You’ll use the GSM8K dataset (Grade School Math 8K: a collection of grade school math problems) to improve math problem solving accuracy, but the techniques used here can be adapted to a wide variety of other use cases.

Introducing OS Level Actions in Amazon Bedrock AgentCore Browser
We’re announcing OS Level Actions for AgentCore Browser. This new capability unblocks these scenarios by exposing direct OS control through the InvokeBrowser API, so agents can interact with content visible on the screen, not only what’s accessible through the browser’s web layer. By combining full-desktop screenshots with mouse and keyboard control at the OS level, agents can observe native UI, reason about it, and act on it within the same session. This post walks through how OS Level Actions work, what actions are supported, and how to get started.

Generate dashboards from natural language prompts in Amazon Quick
Building meaningful dashboards demands hours of manual setup, even for experienced BI professionals. Amazon Quick now generates complete multi-sheet dashboards from natural language prompts, taking you from one or more datasets to a production-ready analysis in minutes. Data analysts building recurring operations reports, program managers preparing a leadership review, or engineers exploring a new dataset can […]

AWS Transform now automates BI migration to Amazon Quick in days
In this post, we walk through the full journey, from setting up your migration workspace in AWS Transform to subscribing to partner agents through AWS Marketplace to unlocking Amazon Quick capabilities that change how your organization consumes data.
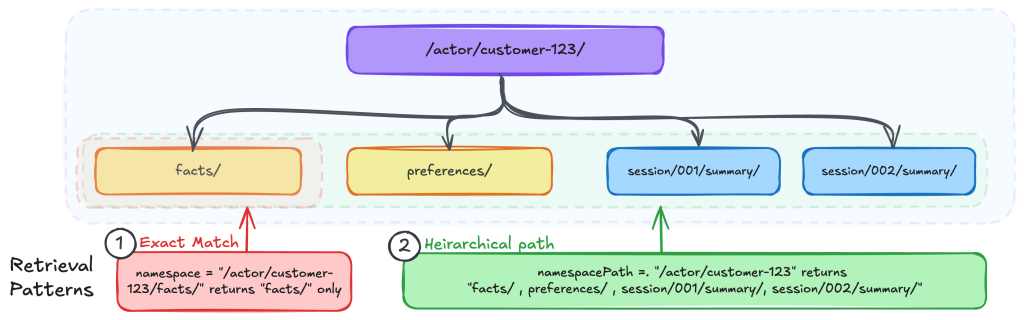
Organizing Agents’ memory at scale: Namespace design patterns in AgentCore Memory
In this post, you will learn how to design namespace hierarchies, choose the right retrieval patterns, and implement AWS Identity and Access Management (IAM)-based access control for AgentCore Memory.