Artificial Intelligence
Category: Artificial Intelligence

How TransPerfect Improved Translation Quality and Efficiency Using Amazon Bedrock
This post describes how the AWS Customer Channel Technology – Localization Team worked with TransPerfect to integrate Amazon Bedrock into the GlobalLink translation management system, a cloud-based solution designed to help organizations manage their multilingual content and translation workflows. Organizations use TransPerfect’s solution to rapidly create and deploy content at scale in multiple languages using AI.

Racing beyond DeepRacer: Debut of the AWS LLM League
The AWS LLM League was designed to lower the barriers to entry in generative AI model customization by providing an experience where participants, regardless of their prior data science experience, could engage in fine-tuning LLMs. Using Amazon SageMaker JumpStart, attendees were guided through the process of customizing LLMs to address real business challenges adaptable to their domain.

Reduce ML training costs with Amazon SageMaker HyperPod
In this post, we explore the challenges of large-scale frontier model training, focusing on hardware failures and the benefits of Amazon SageMaker HyperPod – a solution that minimizes disruptions, enhances efficiency, and reduces training costs.
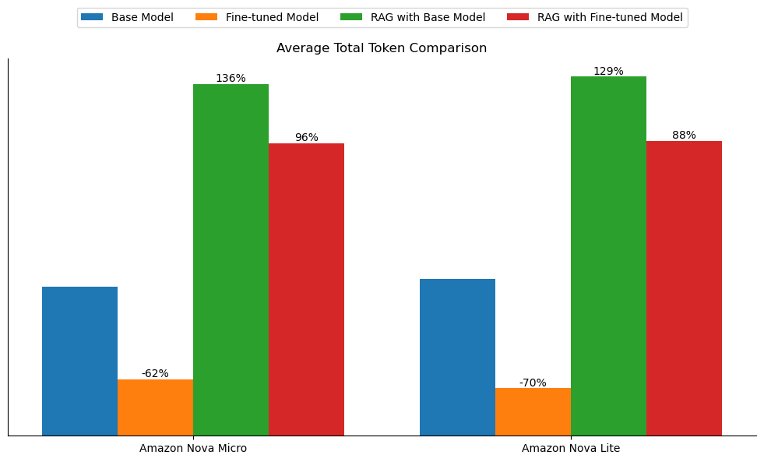
Model customization, RAG, or both: A case study with Amazon Nova
The introduction of Amazon Nova models represent a significant advancement in the field of AI, offering new opportunities for large language model (LLM) optimization. In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. We conducted a comprehensive comparison study between model customization and RAG using the latest Amazon Nova models, and share these valuable insights.

Generate user-personalized communication with Amazon Personalize and Amazon Bedrock
In this post, we demonstrate how to use Amazon Personalize and Amazon Bedrock to generate personalized outreach emails for individual users using a video-on-demand use case. This concept can be applied to other domains, such as compelling customer experiences for ecommerce and digital marketing use cases.

Automating regulatory compliance: A multi-agent solution using Amazon Bedrock and CrewAI
In this post, we explore how AI agents can streamline compliance and fulfill regulatory requirements for financial institutions using Amazon Bedrock and CrewAI. We demonstrate how to build a multi-agent system that can automatically summarize new regulations, assess their impact on operations, and provide prescriptive technical guidance. You’ll learn how to use Amazon Bedrock Knowledge Bases and Amazon Bedrock Agents with CrewAI to create a comprehensive, automated compliance solution.

Pixtral Large is now available in Amazon Bedrock
In this post, we demonstrate how to get started with the Pixtral Large model in Amazon Bedrock. The Pixtral Large multimodal model allows you to tackle a variety of use cases, such as document understanding, logical reasoning, handwriting recognition, image comparison, entity extraction, extracting structured data from scanned images, and caption generation.

Implement human-in-the-loop confirmation with Amazon Bedrock Agents
In this post, we focus specifically on enabling end-users to approve actions and provide feedback using built-in Amazon Bedrock Agents features, specifically HITL patterns for providing safe and effective agent operations. We explore the patterns available using a Human Resources (HR) agent example that helps employees requesting time off.

Boost team productivity with Amazon Q Business Insights
In this post, we explore Amazon Q Business Insights capabilities and its importance for organizations. We begin with an overview of the available metrics and how they can be used for measuring user engagement and system effectiveness. Then we provide instructions for accessing and navigating this dashboard.

Multi-LLM routing strategies for generative AI applications on AWS
Organizations are increasingly using multiple large language models (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. The multi-LLM approach enables organizations to effectively choose the right model for each task, adapt to different […]