Artificial Intelligence
Category: Advanced (300)

Implementing MLOps practices with Amazon SageMaker JumpStart pre-trained models
Amazon SageMaker JumpStart is the machine learning (ML) hub of SageMaker that offers over 350 built-in algorithms, pre-trained models, and pre-built solution templates to help you get started with ML fast. JumpStart provides one-click access to a wide variety of pre-trained models for common ML tasks such as object detection, text classification, summarization, text generation […]

Building AI chatbots using Amazon Lex and Amazon Kendra for filtering query results based on user context
Amazon Kendra is an intelligent search service powered by machine learning (ML). It indexes the documents stored in a wide range of repositories and finds the most relevant document based on the keywords or natural language questions the user has searched for. In some scenarios, you need the search results to be filtered based on […]

Detect signatures on documents or images using the signatures feature in Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Signatures is a feature within Amazon Textract that offers the ability to automatically detect signatures on any document. This can reduce the need for human review, custom code, or ML experience. In this post, […]

Monitoring Lake Mead drought using the new Amazon SageMaker geospatial capabilities
Earth’s changing climate poses an increased risk of drought due to global warming. Since 1880, the global temperature has increased 1.01 °C. Since 1993, sea levels have risen 102.5 millimeters. Since 2002, the land ice sheets in Antarctica have been losing mass at a rate of 151.0 billion metric tons per year. In 2022, the […]

Optimize your machine learning deployments with auto scaling on Amazon SageMaker
Machine learning (ML) has become ubiquitous. Our customers are employing ML in every aspect of their business, including the products and services they build, and for drawing insights about their customers. To build an ML-based application, you have to first build the ML model that serves your business requirement. Building ML models involves preparing the […]
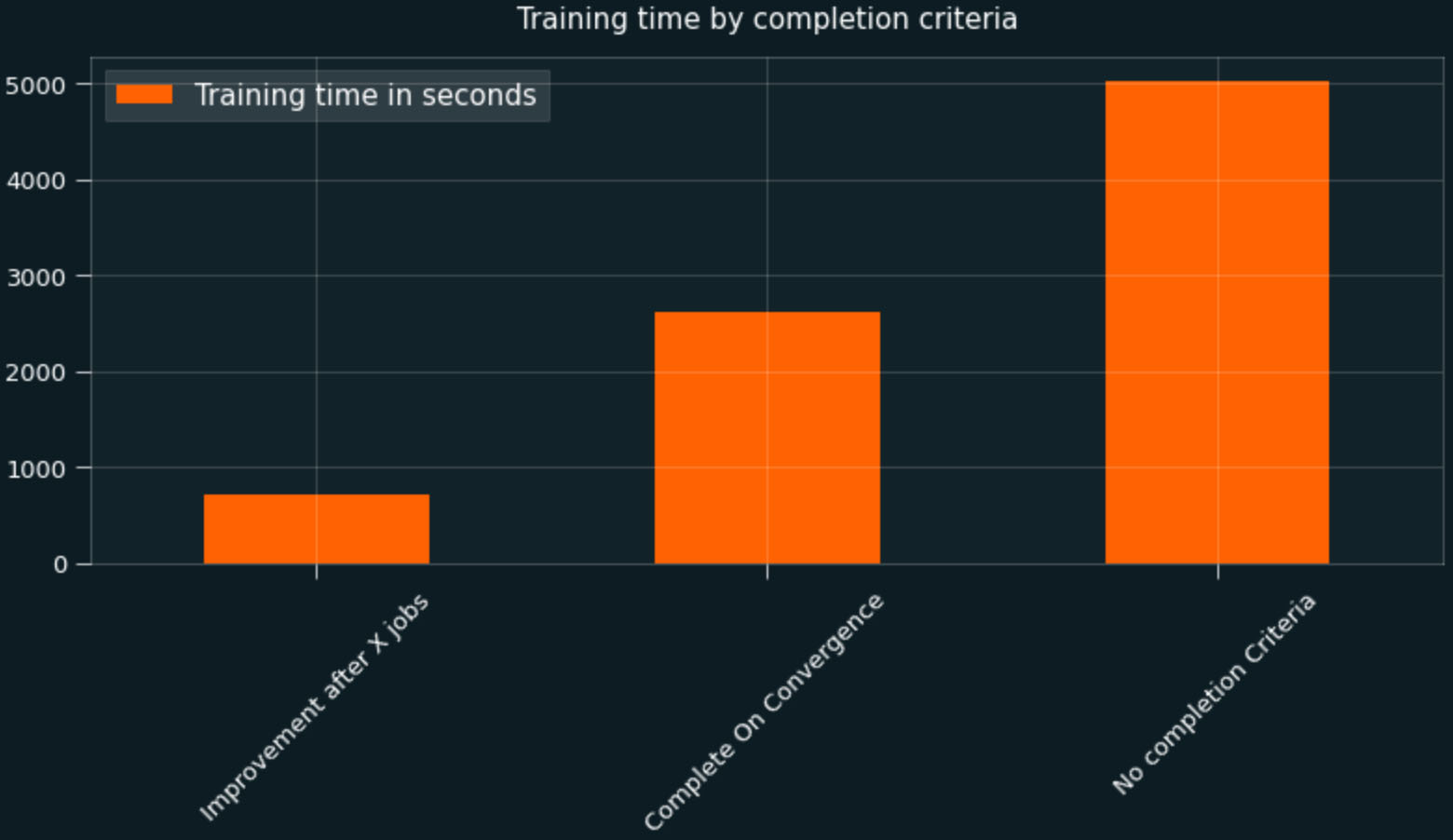
Amazon SageMaker Automatic Model Tuning now supports three new completion criteria for hyperparameter optimization
Amazon SageMaker has announced the support of three new completion criteria for Amazon SageMaker automatic model tuning, providing you with an additional set of levers to control the stopping criteria of the tuning job when finding the best hyperparameter configuration for your model. In this post, we discuss these new completion criteria, when to use them, and […]

Create powerful self-service experiences with Amazon Lex on Talkdesk CX Cloud contact center
This blog post is co-written with Bruno Mateus, Jonathan Diedrich and Crispim Tribuna at Talkdesk. Contact centers are using artificial intelligence (AI) and natural language processing (NLP) technologies to build a personalized customer experience and deliver effective self-service support through conversational bots. This is the first of a two-part series dedicated to the integration of […]

How to decide between Amazon Rekognition image and video API for video moderation
Almost 80% of today’s web content is user-generated, creating a deluge of content that organizations struggle to analyze with human-only processes. The availability of consumer information helps them make decisions, from buying a new pair of jeans to securing home loans. In a recent survey, 79% of consumers stated they rely on user videos, comments, […]

Scaling distributed training with AWS Trainium and Amazon EKS
Recent developments in deep learning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Although larger models tend to be more powerful, training such models requires significant computational resources. Even with the use of advanced distributed training libraries like FSDP and […]

Amazon SageMaker built-in LightGBM now offers distributed training using Dask
Amazon SageMaker provides a suite of built-in algorithms, pre-trained models, and pre-built solution templates to help data scientists and machine learning (ML) practitioners get started on training and deploying ML models quickly. You can use these algorithms and models for both supervised and unsupervised learning. They can process various types of input data, including tabular, […]