Artificial Intelligence
Optimize your machine learning deployments with auto scaling on Amazon SageMaker
Machine learning (ML) has become ubiquitous. Our customers are employing ML in every aspect of their business, including the products and services they build, and for drawing insights about their customers.
To build an ML-based application, you have to first build the ML model that serves your business requirement. Building ML models involves preparing the data for training, extracting features, and then training and fine-tuning the model using the features. Next, the model has to be put to work so that it can generate inference (or predictions) from new data, which can then be used in the application. Although you can integrate the model directly into an application, the approach that works well for production-grade applications is to deploy the model behind an endpoint and then invoke the endpoint via a RESTful API call to obtain the inference. In this approach, the model is typically deployed on an infrastructure (compute, storage, and networking) that suits the price-performance requirements of the application. These requirements include the number inferences that the endpoint is expected to return in a second (called the throughput), how quickly the inference must be generated (the latency), and the overall cost of hosting the model.
Amazon SageMaker makes it easy to deploy ML models for inference at the best price-performance for any use case. It provides a broad selection of ML infrastructure and model deployment options to help meet all your ML inference needs. It is a fully managed service, so you can scale your model deployment, reduce inference costs, manage models more effectively in production, and reduce operational burden. One of the ways to minimize your costs is to provision only as much compute infrastructure as needed to serve the inference requests to the endpoint (also known as the inference workload) at any given time. Because the traffic pattern of inference requests can vary over time, the most cost-effective deployment system must be able to scale out when the workload increases and scale in when the workload decreases in real-time. SageMaker supports automatic scaling (auto scaling) for your hosted models. Auto scaling dynamically adjusts the number of instances provisioned for a model in response to changes in your inference workload. When the workload increases, auto scaling brings more instances online. When the workload decreases, auto scaling removes unnecessary instances so that you don’t pay for provisioned instances that you aren’t using.
With SageMaker, you can choose when to auto scale and how many instances to provision or remove to achieve the right availability and cost trade-off for your application. SageMaker supports three auto scaling options. The first and commonly used option is target tracking. In this option, you select an ideal value of an Amazon CloudWatch metric of your choice, such as the average CPU utilization or throughput that you want to achieve as a target, and SageMaker will automatically scale in or scale out the number of instances to achieve the target metric. The second option is to choose step scaling, which is an advanced method for scaling based on the size of the CloudWatch alarm breach. The third option is scheduled scaling, which lets you specify a recurring schedule for scaling your endpoint in and out based on anticipated demand. We recommend that you combine these scaling options for better resilience.
In this post, we provide a design pattern for deriving the right auto scaling configuration for your application. In addition, we provide a list of steps to follow, so even if your application has a unique behavior, such as different system characteristics or traffic patterns, this systemic approach can be applied to determine the right scaling policies. The procedure is further simplified with the use of Inference Recommender, a right-sizing and benchmarking tool built inside SageMaker. However, you can use any other benchmarking tool.
You can review the notebook we used to run this procedure to derive the right deployment configuration for our use case.
SageMaker hosting real-time endpoints and metrics
SageMaker real-time endpoints are ideal for ML applications that need to handle a variety of traffic and respond to requests in real time. The application setup begins with defining the runtime environment, including the containers, ML model, environment variables, and so on in the create-model API, and then defining the hosting details such as instance type and instance count for each variant in the create-endpoint-config API. The endpoint configuration API also allows you to split or duplicate traffic between variants using production and shadow variants. However, for this example, we define scaling policies using a single production variant. After setting up the application, you set up scaling, which involves registering the scaling target and applying scaling policies. Refer to Configuring autoscaling inference endpoints in Amazon SageMaker for more details on the various scaling options.
The following diagram illustrates the application and scaling setup in SageMaker.

Endpoint metrics
In order to understand the scaling exercise, it’s important to understand the metrics that the endpoint emits. At a high level, these metrics are categorized into three classes: invocation metrics, latency metrics, and utilization metrics.
The following diagram illustrates these metrics and the endpoint architecture.

The following tables elaborate on the details of each metric.
Invocation metrics
| Metrics | Overview | Period | Units | Statistics |
| Invocations | The number of InvokeEndpoint requests sent to a model endpoint. | 1 minute | None | Sum |
| InvocationsPerInstance | The number of invocations sent to a model, normalized by InstanceCount in each variant. 1/numberOfInstances is sent as the value on each request, where numberOfInstances is the number of active instances for the variant behind the endpoint at the time of the request. | 1 minute | None | Sum |
| Invocation4XXErrors | The number of InvokeEndpoint requests where the model returned a 4xx HTTP response code. | 1 minute | None | Average, Sum |
| Invocation5XXErrors | The number of InvokeEndpoint requests where the model returned a 5xx HTTP response code. | 1 minute | None | Average, Sum |
Latency metrics
| Metrics | Overview | Period | Units | Statistics |
| ModelLatency | The interval of time taken by a model to respond as viewed from SageMaker. This interval includes the local communication times taken to send the request and to fetch the response from the container of a model and the time taken to complete the inference in the container. | 1 minute | Microseconds | Average, Sum, Min, Max, Sample Count |
| OverheadLatency | The interval of time added to the time taken to respond to a client request by SageMaker overheads. This interval is measured from the time SageMaker receives the request until it returns a response to the client, minus the ModelLatency. Overhead latency can vary depending on multiple factors, including request and response payload sizes, request frequency, and authentication or authorization of the request. | 1 minute | Microseconds | Average, Sum, Min, Max, Sample Count |
Utilization metrics
| Metrics | Overview | Period | Units |
| CPUUtilization | The sum of each individual CPU core’s utilization. The CPU utilization of each core range is 0–100. For example, if there are four CPUs, the CPUUtilization range is 0–400%. | 1 minute | Percent |
| MemoryUtilization | The percentage of memory that is used by the containers on an instance. This value range is 0–100%. | 1 minute | Percent |
| GPUUtilization | The percentage of GPU units that are used by the containers on an instance. The value can range between 0–100 and is multiplied by the number of GPUs. | 1 minute | Percent |
| GPUMemoryUtilization | The percentage of GPU memory used by the containers on an instance. The value range is 0–100 and is multiplied by the number of GPUs. For example, if there are four GPUs, the GPUMemoryUtilization range is 0–400%. | 1 minute | Percent |
| DiskUtilization | The percentage of disk space used by the containers on an instance. This value range is 0–100%. | 1 minute | Percent |
Use case overview
We use a simple XGBoost classifier model for our application and have decided to host on the ml.c5.large instance type. However, the following procedure is independent of the model or deployment configuration, so you can adopt the same approach for your own application and deployment choice. We assume that you already have a desired instance type at the start of this process. If you need assistance in determining the ideal instance type for your application, you should use the Inference Recommender default job for getting instance type recommendations.
Scaling plan
The scaling plan is a three-step procedure, as illustrated in the following diagram:
- Identify the application characteristics – Knowing the bottlenecks of the application on the selected hardware is an essential part of this.
- Set scaling expectations – This involves determining the maximum number of requests per second, and how the request pattern will look (whether it will be smooth or spiky).
- Apply and evaluate – Scaling policies should be developed based on application characteristics and scaling expectations. As part of this final step, evaluate the policies by running the load that it is expected to handle. In addition, we recommend iterating the last step, until the scaling policy can handle the request load.

Identify application characteristics
In this section, we discuss the methods to identify application characteristics.
Benchmarking
To derive the right scaling policy, the first step in the plan is to determine application behavior on the chosen hardware. This can be achieved by running the application on a single host and increasing the request load to the endpoint gradually until it saturates. In many cases, after saturation, the endpoint can no longer handle any more requests and performance begins to deteriorate. This can be seen in the endpoint invocation metrics. We also recommend that you review hardware utilization metrics and understand the bottlenecks, if any. For CPU instances, the bottleneck can be in the CPU, memory, or disk utilization metrics, while for GPU instances, the bottleneck can be in GPU utilization and its memory. We discuss invocations and utilization metrics on ml.c5.large hardware in the following section. It’s also important to remember that CPU utilization is aggregated across all cores, therefore it is at 200% scale for an ml.c5.large two-core machine.
For benchmarking, we use the Inference Recommender default job. Inference Recommender default jobs will, by default, benchmark with multiple instance types. However, you can narrow down the search to your chosen instance type by passing those in supported instances. The service then provisioning the endpoint gradually increases the request and stops when the benchmark reaches saturation or if the endpoint invoke API call fails for 1% of the results. The hosting metrics can be used to determine the hardware bounds and set the right scaling limit. In the event that there is a hardware bottleneck, we recommend that you scale up the instance size in the same family or change the instance family entirely.
The following diagram illustrates the architecture of benchmarking using Inference Recommender.
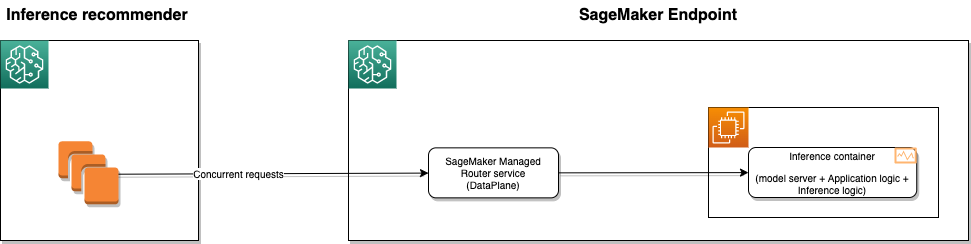
Use the following code:
def trigger_inference_recommender(model_url, payload_url, container_url, instance_type, execution_role, framework,
framework_version, domain="MACHINE_LEARNING", task="OTHER", model_name="classifier",
mime_type="text/csv"):
model_package_arn = create_model_package(model_url, payload_url, container_url, instance_type,
framework, framework_version, domain, task, model_name, mime_type)
job_name = create_inference_recommender_job(model_package_arn, execution_role)
wait_for_job_completion(job_name)
return job_nameAnalyze the result
We then analyze the results of the recommendation job using endpoint metrics. From the following hardware utilization graph, we confirm that the hardware limits are within the bounds. Furthermore, the CPUUtilization line increases proportional to request load, so it is necessary to have scaling limits on CPU utilization as well.

From the following figure, we confirm that the invocation flattens after it reaches its peak.

Next, we move on to the invocations and latency metrics for setting the scaling limit.
Find scaling limits
In this step, we run various scaling percentages to find the right scaling limit. As a general scaling rule, the hardware utilization percentage should be around 40% if you’re optimizing for availability, around 70% if you’re optimizing for cost, and around 50% if you want to balance availability and cost. The guidance gives an overview of the two dimensions: availability and cost. The lower the threshold, the better the availability. The higher the threshold, the better the cost. In the following figure, we plotted the graph with 55% as the upper limit and 45% as the lower limit for invocation metrics. The top graph shows invocations and latency metrics; the bottom graph shows utilization metrics.

You can use the following sample code to change the percentages and see what the limits are for the invocations, latency, and utilization metrics. We highly recommend that you play around with percentages and find the best fit based on your metrics.
def analysis_inference_recommender_result(job_name, index=0,
upper_threshold=80.0, lower_threshold=65.0):Because we want to optimize for availability and cost in this example, we decided to use 50% aggregate CPU utilization. As we selected a two-core machine, our aggregated CPU utilization is 200%. We therefore set a threshold of 100% for CPU utilization because we’re doing 50% for two cores. In addition to the utilization threshold, we also set the InvocationPerInstance threshold to 5000. The value for InvocationPerInstance is derived by overlaying CPUUtilization = 100% over the invocations graph.
As part of step 1 of the scaling plan (shown in the following figure), we benchmarked the application using the Inference Recommender default job, analyzed the results, and determined the scaling limit based on cost and availability.

Set scaling expectations
The next step is to set expectations and develop scaling policies based on these expectations. This step involves defining the maximum and minimum requests to be served, as well as additional details, like what is the maximum request growth of the application should handle? Is it smooth or spiky traffic pattern? Data like this will help define the expectation and help you develop a scaling policy that meets your demand.
The following diagram illustrates an example traffic pattern.

For our application, the expectations are maximum requests per second (max) = 500, and minimum request per second (min) = 70.
Based on these expectations, we define MinCapacity and MaxCapacity using the following formula. For the following calculations, we normalize InvocationsPerInstance to seconds because it is per minute. Additionally, we define growth factor, which is the amount of additional capacity that you are willing to add when your scale exceeds the maximum requests per second. The growth_factor should always be greater than 1, and it is essential in planning for additional growth.
MinCapacity = ceil(min / (InvocationsPerInstance/60) )
MaxCapacity = ceil(max / (InvocationsPerInstance/60)) * Growth_factorIn the end, we arrive at MinCapacity = 1 and MaxCapacity = 8 (with 20% as growth factor), and we plan to handle a spiky traffic pattern.

Define scaling policies and verify
The final step is to define a scaling policy and evaluate its impact. The evaluation serves to validate the results of the calculations made so far. In addition, it helps us adjust the scaling setting if it doesn’t meet our needs. The evaluation is done using the Inference Recommender advanced job, where we specify the traffic pattern, MaxInvocations, and endpoint to benchmark against. In this case, we provision the endpoint and set the scaling policies, then run the Inference Recommender advanced job to validate the policy.
Target tracking
It is recommended to set up target tracking based on InvocationsPerInstance. The threshold has already been defined in step 1, so we set the CPUUtilization threshold to 100 and the InvocationsPerInstance threshold to 5000. First, we define a scaling policy based on the number of InvocationsPerInstance, and then we create a scaling policy that relies on CPU utilization.
As in the sample notebook, we use the following functions to register and set scaling policies:
def set_target_scaling_on_invocation(endpoint_name, variant_name, target_value,
scale_out_cool_down=10,
scale_in_cool_down=100):
policy_name = 'target-tracking-invocations-{}'.format(str(round(time.time())))
resource_id = "endpoint/{}/variant/{}".format(endpoint_name, variant_name)
response = aas_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
PolicyType='TargetTrackingScaling',
TargetTrackingScalingPolicyConfiguration={
'TargetValue': target_value,
'PredefinedMetricSpecification': {
'PredefinedMetricType': 'SageMakerVariantInvocationsPerInstance',
},
'ScaleOutCooldown': scale_out_cool_down,
'ScaleInCooldown': scale_in_cool_down,
'DisableScaleIn': False
}
)
return policy_name, response
def set_target_scaling_on_cpu_utilization(endpoint_name, variant_name, target_value,
scale_out_cool_down=10,
scale_in_cool_down=100):
policy_name = 'target-tracking-cpu-util-{}'.format(str(round(time.time())))
resource_id = "endpoint/{}/variant/{}".format(endpoint_name, variant_name)
response = aas_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
PolicyType='TargetTrackingScaling',
TargetTrackingScalingPolicyConfiguration={
'TargetValue': target_value,
'CustomizedMetricSpecification':
{
'MetricName': 'CPUUtilization',
'Namespace': '/aws/sagemaker/Endpoints',
'Dimensions': [
{'Name': 'EndpointName', 'Value': endpoint_name},
{'Name': 'VariantName', 'Value': variant_name}
],
'Statistic': 'Average',
'Unit': 'Percent'
},
'ScaleOutCooldown': scale_out_cool_down,
'ScaleInCooldown': scale_in_cool_down,
'DisableScaleIn': False
}
)
return policy_name, responseBecause we need to handle spiky traffic patterns, the sample notebook uses ScaleOutCooldown = 10 and ScaleInCooldown = 100 as the cooldown values. As we evaluate the policy in the next step, we plan to adjust the cooldown period (if needed).
Evaluation target tracking
The evaluation is done using the Inference Recommender advanced job, where we specify the traffic pattern, MaxInvocations, and endpoint to benchmark against. In this case, we provision the endpoint and set the scaling policies, then run the Inference Recommender advanced job to validate the policy.
from inference_recommender import trigger_inference_recommender_evaluation_job
from result_analysis import analysis_evaluation_result
eval_job = trigger_inference_recommender_evaluation_job(model_package_arn=model_package_arn,
execution_role=role,
endpoint_name=endpoint_name,
instance_type=instance_type,
max_invocations=max_tps*60,
max_model_latency=10000,
spawn_rate=1)
print ("Evaluation job = {}, EndpointName = {}".format(eval_job, endpoint_name))
# In the next step, we will visualize the cloudwatch metrics and verify if we reach 30000 invocations.
max_value = analysis_evaluation_result(endpoint_name, variant_name, job_name=eval_job)
print("Max invocation realized = {}, and the expecation is {}".format(max_value, 30000))Following benchmarking, we visualized the invocations graph to understand how the system responds to scaling policies. The scaling policy that we established can handle the requests and can reach up to 30,000 invocations without error.

Now, let’s consider what happens if we triple the rate of new user. Does the same policy apply? We can rerun the same evaluation set with a higher request rate and set the spawn rate (an additional user per minute) to 3.

With the above result, we confirm that the current auto-scaling policy can cover even the aggressive traffic pattern.
Step scaling
In addition to Target tracking, we also recommend using step scaling to have better control over aggressive traffic. Therefore, we defined an additional step scale with scaling adjustments to handle spiky traffic.
def set_step_scaling(endpoint_name, variant_name):
policy_name = 'step-scaling-{}'.format(str(round(time.time())))
resource_id = "endpoint/{}/variant/{}".format(endpoint_name, variant_name)
response = aas_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount',
PolicyType='StepScaling',
StepScalingPolicyConfiguration={
'AdjustmentType': 'ChangeInCapacity',
'StepAdjustments': [
{
'MetricIntervalLowerBound': 0.0,
'MetricIntervalUpperBound': 5.0,
'ScalingAdjustment': 1
},
{
'MetricIntervalLowerBound': 5.0,
'MetricIntervalUpperBound': 80.0,
'ScalingAdjustment': 3
},
{
'MetricIntervalLowerBound': 80.0,
'ScalingAdjustment': 4
},
],
'MetricAggregationType': 'Average'
},
)
return policy_name, responseEvaluation step scaling
We then follow the same step to evaluate, and after the benchmark we confirm that the scaling policy can handle a spiky traffic pattern and reach 30,000 invocations without any errors.

Therefore, defining the scaling policies and evaluating the results using the Inference Recommender is a necessary part of validation.

Further tuning
In this section, we discuss further tuning options.
Multiple scaling options
As shown in our use case, you can pick multiple scaling policies that meet your needs. In addition to the options mentioned previously, you should also consider scheduled scaling if you forecast traffic for a period of time. The combination of scaling policies is powerful and should be evaluated using benchmarking tools like Inference Recommender.
Scale up or down
SageMaker Hosting offers over 100 instance types to host your model. Your traffic load may be limited by the hardware you have chosen, so consider other hosting hardware. For example, if you want a system to handle 1,000 requests per second, scale up instead of out. Accelerator instances such as G5 and Inf1 can process higher numbers of requests on a single host. Scaling up and down can provide better resilience for some traffic needs than scaling in and out. In order to scale up or down an existing endpoint, you must create a new production variant and shift traffic as described here.
Custom metrics
In addition to InvocationsPerInstance and other SageMaker hosting metrics, you can also define metrics for scaling your application. However, any custom metrics that are used for scaling should depict the load of the system. The metrics should increase in value when utilization is high, and decrease otherwise. The custom metrics could bring more granularity to the load and help in defining custom scaling policies.
Adjusting scaling alarm
By defining the scaling policy, you are creating an alarm for scaling, and these alarms are used for scale in and scale out. However, these alarms have a default number of data points on which they are alerted. In case you want to alter the number of data points of the alarm, you can do so. Nevertheless, after any update to scaling policies, it is recommended to evaluate the policy by using a benchmarking tool with the load it should handle.

Conclusion
The process of defining the scaling policy for your application can be challenging. You must understand the characteristics of the application, determine your scaling needs, and iterate scaling policies to meet those needs. This post has reviewed each of these steps and explained the approach you should take at each step. You can find your application characteristics and evaluate scaling policies by using the Inference Recommender benchmarking system. The proposed design pattern can help you create a scalable application within hours, rather than days, that takes into account the availability and cost of your application.
About the Authors
 Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
 Venkatesh Krishnan leads Product Management for Amazon SageMaker in AWS. He is the product owner for a portfolio of SageMaker services that enable customers to deploy machine learning models for Inference. Earlier he was the Head of Product, Integrations and the lead product manager for Amazon AppFlow, a new AWS service that he helped build from the ground up. Before joining Amazon in 2018, Venkatesh served in various research, engineering, and product roles at Qualcomm, Inc. He holds a PhD in Electrical and Computer Engineering from Georgia Tech and an MBA from ULCA’s Anderson School of Management.
Venkatesh Krishnan leads Product Management for Amazon SageMaker in AWS. He is the product owner for a portfolio of SageMaker services that enable customers to deploy machine learning models for Inference. Earlier he was the Head of Product, Integrations and the lead product manager for Amazon AppFlow, a new AWS service that he helped build from the ground up. Before joining Amazon in 2018, Venkatesh served in various research, engineering, and product roles at Qualcomm, Inc. He holds a PhD in Electrical and Computer Engineering from Georgia Tech and an MBA from ULCA’s Anderson School of Management.