Artificial Intelligence
Category: Technical How-to
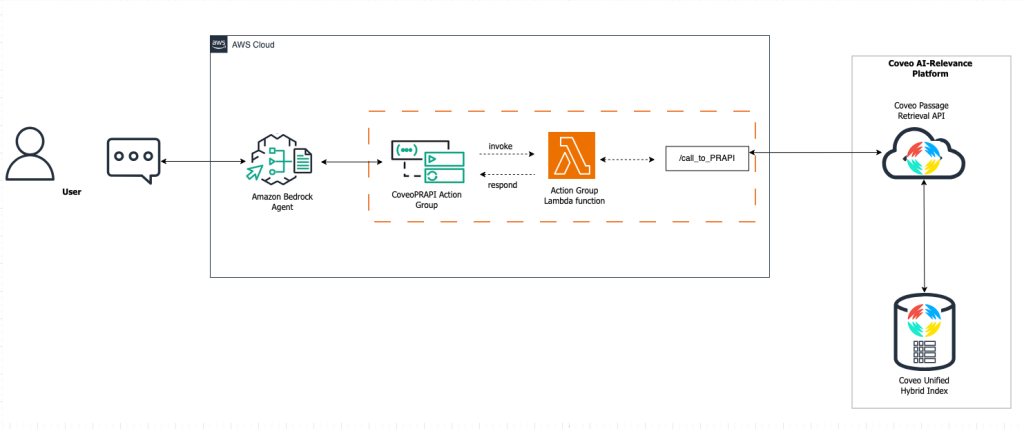
Enhancing LLM accuracy with Coveo Passage Retrieval on Amazon Bedrock
In this post, we show how to deploy Coveo’s Passage Retrieval API as an Amazon Bedrock Agents action group to enhance response accuracy, so Coveo users can use their current index to rapidly deploy new generative experiences across their organization.
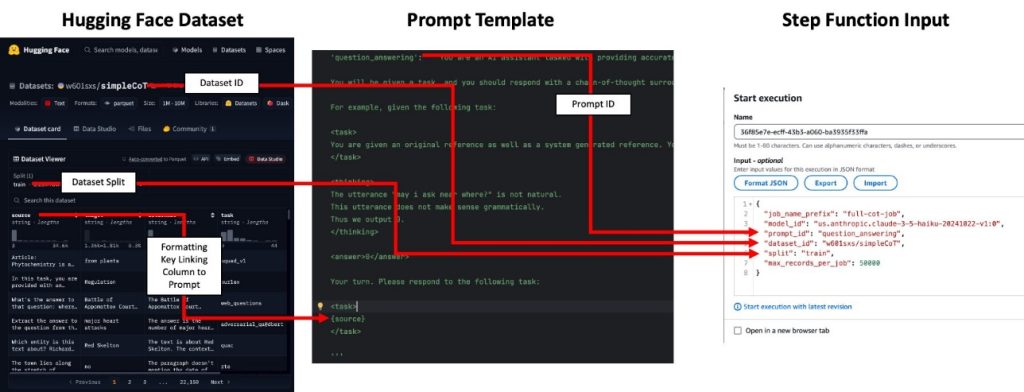
Build a serverless Amazon Bedrock batch job orchestration workflow using AWS Step Functions
In this post, we introduce a flexible and scalable solution that simplifies the batch inference workflow. This solution provides a highly scalable approach to managing your FM batch inference needs, such as generating embeddings for millions of documents or running custom evaluation or completion tasks with large datasets.

Deploy Amazon Bedrock Knowledge Bases using Terraform for RAG-based generative AI applications
In this post, we demonstrated how to automate the deployment of Amazon Knowledge Bases for RAG applications using Terraform.

Document intelligence evolved: Building and evaluating KIE solutions that scale
In this blog post, we demonstrate an end-to-end approach for building and evaluating a KIE solution using Amazon Nova models available through Amazon Bedrock. This end-to-end approach encompasses three critical phases: data readiness (understanding and preparing your documents), solution development (implementing extraction logic with appropriate models), and performance measurement (evaluating accuracy, efficiency, and cost-effectiveness). We illustrate this comprehensive approach using the FATURA dataset—a collection of diverse invoice documents that serves as a representative proxy for real-world enterprise data.
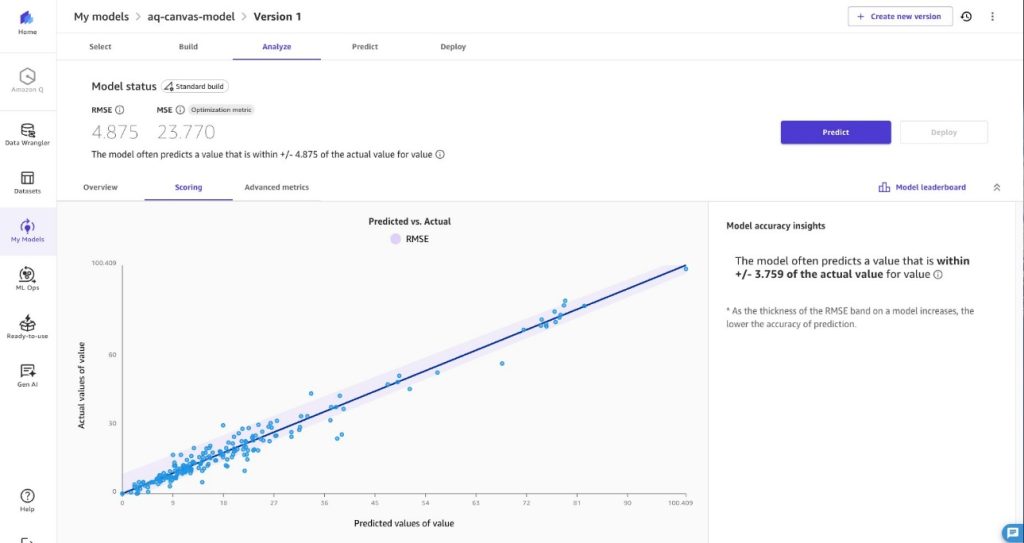
Empowering air quality research with secure, ML-driven predictive analytics
In this post, we provide a data imputation solution using Amazon SageMaker AI, AWS Lambda, and AWS Step Functions. This solution is designed for environmental analysts, public health officials, and business intelligence professionals who need reliable PM2.5 data for trend analysis, reporting, and decision-making. We sourced our sample training dataset from openAFRICA. Our solution predicts PM2.5 values using time-series forecasting.

Amazon SageMaker HyperPod enhances ML infrastructure with scalability and customizability
In this post, we introduced three features in SageMaker HyperPod that enhance scalability and customizability for ML infrastructure. Continuous provisioning offers flexible resource provisioning to help you start training and deploying your models faster and manage your cluster more efficiently. With custom AMIs, you can align your ML environments with organizational security standards and software requirements.

Speed up delivery of ML workloads using Code Editor in Amazon SageMaker Unified Studio
In this post, we walk through how you can use the new Code Editor and multiple spaces support in SageMaker Unified Studio. The sample solution shows how to develop an ML pipeline that automates the typical end-to-end ML activities to build, train, evaluate, and (optionally) deploy an ML model.
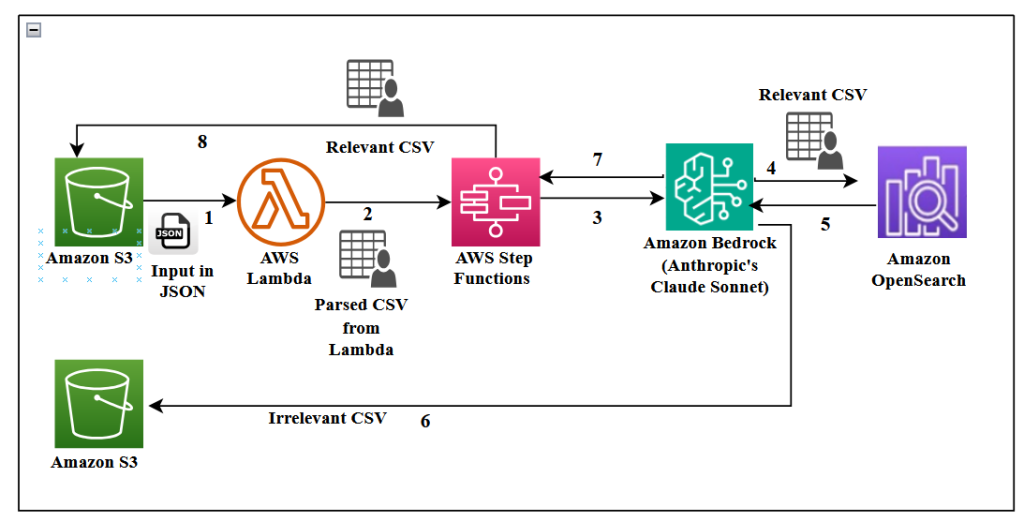
How Infosys Topaz leverages Amazon Bedrock to transform technical help desk operations
In this blog, we examine the use case of a large energy supplier whose technical help desk agents answer customer calls and support field agents. We use Amazon Bedrock along with capabilities from Infosys Topaz™ to build a generative AI application that can reduce call handling times, automate tasks, and improve the overall quality of technical support.
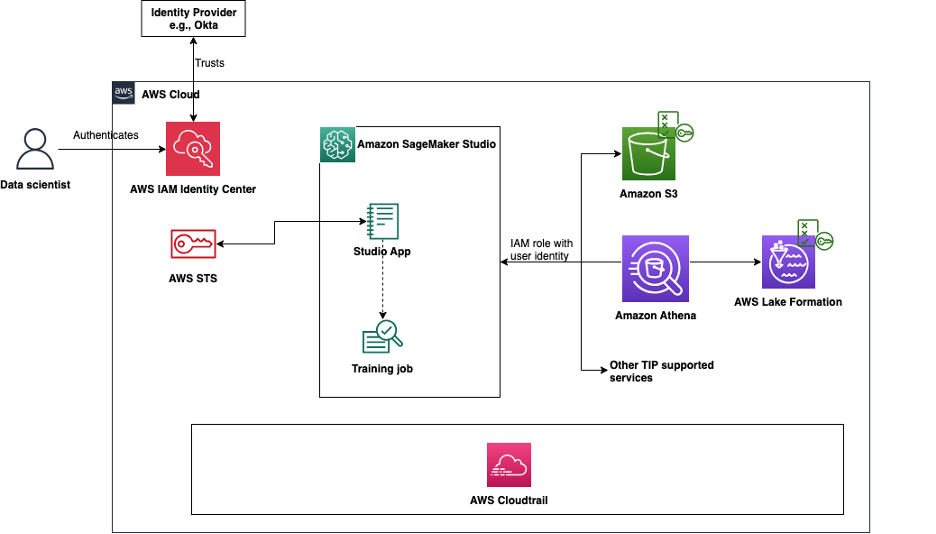
Simplify access control and auditing for Amazon SageMaker Studio using trusted identity propagation
In this post, we explore how to enable and use trusted identity propagation in Amazon SageMaker Studio, which allows organizations to simplify access management by granting permissions to existing AWS IAM Identity Center identities. The solution demonstrates how to implement fine-grained access controls based on a physical user’s identity, maintain detailed audit logs across supported AWS services, and support long-running user background sessions for training jobs.
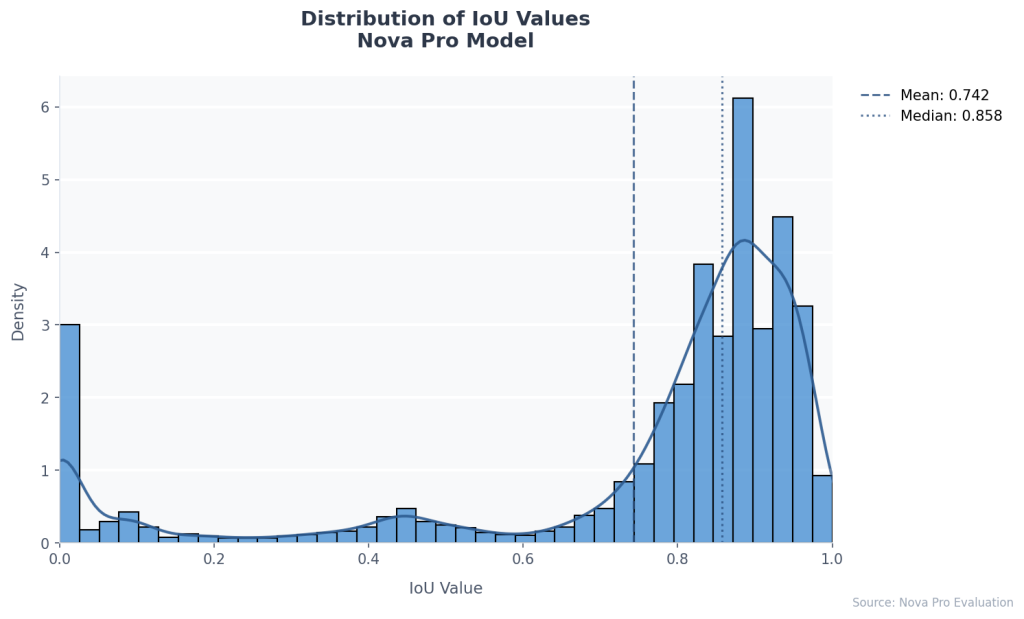
Benchmarking document information localization with Amazon Nova
This post demonstrates how to use foundation models (FMs) in Amazon Bedrock, specifically Amazon Nova Pro, to achieve high-accuracy document field localization while dramatically simplifying implementation. We show how these models can precisely locate and interpret document fields with minimal frontend effort, reducing processing errors and manual intervention.