Artificial Intelligence
Creating high-quality machine learning models for financial services using Amazon SageMaker Autopilot
Machine learning (ML) is used throughout the financial services industry to perform a wide variety of tasks, such as fraud detection, market surveillance, portfolio optimization, loan solvency prediction, direct marketing, and many others. This breadth of use cases has created a need for lines of business to quickly generate high-quality and performant models that can be produced with little to no code. This reduces the long cycles for taking use cases from concept to production and generates business value. In this post, we explore how to use Amazon SageMaker Autopilot for some common use cases in the financial services industry.
Autopilot automatically generates pipelines, trains and tunes the best ML models for classification or regression tasks on tabular data, while allowing you to maintain full control and visibility. Autopilot enables automatic creation of ML models without requiring any ML experience. Autopilot automatically analyzes the dataset, processes the data into features, and trains multiple optimized ML models.
Data scientists in financial services often work on tasks where the datasets are highly imbalanced (heavily skewed towards examples of one class). Examples of such tasks include credit card fraud (where a very small fraction of the transactions are actually fraudulent) or bankruptcy (only few corporations file for bankruptcy). We demonstrate how Autopilot automatically handles class imbalance without requiring any additional inputs from the user.
Autopilot recently announced the ability to tune models using the Area Under a Curve (AUC) metric in addition to F1 as the objective metric (which is the default objective for binary classification tasks), more specifically the area under the Receiver Operating Characteristic (ROC) curve. In this post, we show how using the AUC as the model evaluation metric for highly imbalanced data allows Autopilot to generate high-quality models.
Our first use case is to detect credit card fraud based on various anonymized attributes. The dataset is highly imbalanced, with over 99% of the transactions being non-fraudulent. Our second use case is to predict bankruptcy of Polish companies [2]. Here, bankruptcy is similarly a binary response variable (will bankrupt = 1, will not bankrupt = 0), with 96% of the companies not becoming bankrupt.
Prerequisites
To reproduce these steps in your own environment, you must complete the following prerequisites:
- Create an AWS Identity and Access Management (IAM) role that allows the Amazon SageMaker notebook access to Amazon Simple Storage Service (Amazon S3) for storing data.
- Create an Amazon SageMaker notebook instance.
- Create an S3 bucket to store the outputs of your machine learning models and any data.
Credit card fraud detection
In fraud detection tasks, companies are interested in maintaining a very low false positive rate while correctly identifying the fraudulent transactions to the greatest extent possible. A false positive can lead to a company canceling or placing a hold on a customers’ card over a legitimate transaction, which leads to a poor customer experience. As a result, accuracy is not the best metric to consider for this problem; better metrics are the AUC and the F1 score.
The following code shows data for a credit card fraud task:

Note that you can click on the previous table to for an expanded view of the data.
Class 0 and class 1 correspond to No Fraud and Fraud accordingly. As we can see, other than Amount, other columns are anonymized. A key differentiator of Autopilot is its ability to process raw data directly, without the need for data processing on the part of data scientists. For example, Autopilot automatically converts categorical features into numerical values, handles missing values (as we show in the second example), and performs simple text preprocessing.
Using the AWS boto3 API or the AWS Command Line Interface (AWS CLI), we upload the data to Amazon S3 in CSV format:
Now, we select all columns except Class as features and Class as target:
In the following code, we demonstrate how to configure Autopilot in Jupyter notebooks. We have to provide train and test files, and to set TargetAttributeName as Class, this is the target column (the column we predict):
After the Autopilot job is created, we call the fit() function to run it:
After the model is created, we can generate inferences for the test set using the following code. During inference time, Autopilot orchestrates deployment of the inference pipeline, including feature engineering and the ML algorithm on the inference machine.
Model metrics
Common metrics to compare classifiers are the ROC curve and the precision-recall curve. The ROC curve is a plot of the true positive rate against the false positive rate for various thresholds. The higher the prediction quality of the classification model, the more the ROC curve is skewed toward the top left.
The precision-recall curve demonstrates the trade-off between precision and recall, with the best models having a precision-recall curve that is flat initially and drops steeply as the recall approaches 1. The higher the precision and recall, the more the curve is skewed towards the upper right.
To optimize for the F1 score, we simply repeat the steps from earlier, setting the job_objective={'MetricName': 'F1'} and rerunning the Autopilot job. Because the steps are identical, we don’t repeat them in this section. Please note, F1 objective is default for binary classification problems. The following code plots the ROC curve:
The following plot shows the results.

In the preceding AUC ROC plot, Autopilot models provide high AUC when optimizing both objective metrics. We also didn’t select any specific model or tune any hyperparameters; Autopilot did all that heavy lifting for us.
Finally, we plot the precision-recall curves for the trained Autopilot model:
The following plot shows the results.

As we can see from the plot, Autopilot models provide good precision and recall, because the graph is heavily skewed toward the top-right corner.
Autopilot outputs
In addition to handling the heavy lifting of building and training the models, Autopilot provides visibility into the steps taken to build the models by generating two notebooks: CandidateDefinitionNotebook and DataExplorationNotebook.
You can use the candidate definition notebook to interactively step through the steps taken by Autopilot to arrive at the best candidate. You can also use this notebook to override various runtime parameters like parallelism, hardware used, algorithms explored, feature engineering scripts, hyperparameter tuning ranges, and more.
You can download the notebook from the following Amazon S3 location:
The notebook also outlines the various feature engineering steps taken to build the models. The models are indexed by their model type and the feature engineering pipeline. For example, as shown in the Tuning Job Result Overview, the winning model corresponds to the pipeline dpp1-xgboost:
If we search for ModelDataUrl, we can find Autopilot used dpp1-xgboost 'ModelDataUrl': 's3://sagemaker-us-east-1-<ACCOUNT-NUM>/automl-card-fraud-7/tuning/automl-car-dpp1-xgb/tuning-job-1-7e8f6c9dffe840a0bf-009-636d28c2/output/model.tar.gz'.
dpp1-xgboost is a data transformation strategy that transforms numeric features using RobustImputer. It merges all the generated features and applies RobustPCA followed by RobustStandardScaler. The transformed data is used to tune an XGBoost model.
From the candidate definition notebook, we can also see that Autopilot automatically applied up-weighting to the minority class using scale_pos_weight. This improves prediction quality for imbalanced datasets where the model doesn’t see many examples of the minority class during training. You can change the scale_pos_weight to a different value:
The data exploration notebook generates a report that provides insights about the input dataset, such as the missing values or the data types for the different features:
Having described in detail the use of Autopilot to detect credit card fraud, we now briefly discuss a second task: predicting the bankruptcy of companies.
Predicting bankruptcy of Polish companies
For this post, we explore the various economic attributes in the Polish companies bankruptcy data dataset. There are 64 features and a target attribute class. We rename the column class to bankrupt (not bankrupt = 0, bankrupt = 1) for clarity. As noted before, this dataset is also highly imbalanced, with 96% of the data in the non-bankrupt category.
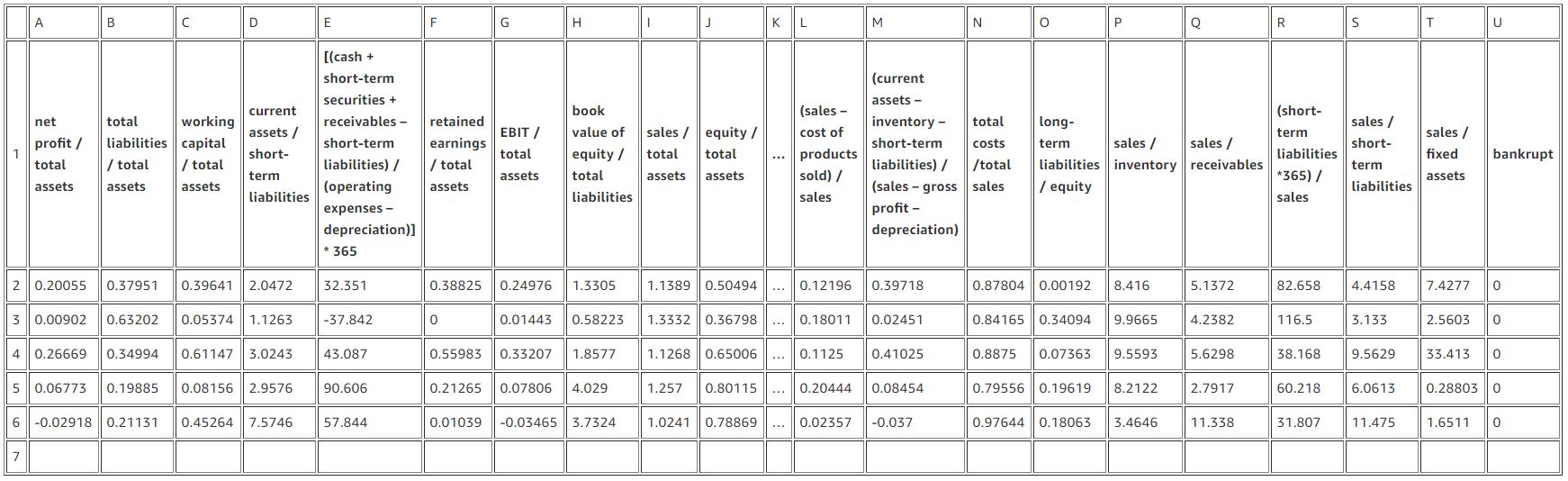
Note that you can click on the previous table to for an expanded view of the data.
We followed the same process for running and configuring Autopilot as in the credit card fraud use case. However, unlike the credit card fraud dataset, this dataset contains missing values. Because Autopilot automatically handles missing values, we simply pass the raw data to Autopilot.
We don’t repeat the code steps in this section; we merely show the ROC and precision-recall curves. Autopilot again yields high-quality models as evidenced from the AUC, ROC, and precision-recall curves. For bankruptcy prediction, incorrectly predicting false negatives can lead to poor investment decisions, and incorrectly predicting that solvent companies may go bankrupt might lead to missed opportunities.
To boost model performance, Autopilot also automatically up-weights the minority class label, penalizing the model for mis-classifying the minority class during training. The following plot shows the precision-recall curve.

The following plot shows the ROC curve.

As we can see from these plots, for bankruptcy, the AUC objective is slightly better than F1. Autopilot can generate accurate predictions for a complex event like bankruptcy without any specialized manual feature-engineering steps.
Cleaning up
The Autopilot job creates many underlying artifacts, such as dataset splits, preprocessing scripts, and preprocessed data. To avoid incurring costs, delete these resources using the following code:
Conclusion
In this post, we demonstrated how to create ML models without any prior knowledge of algorithms using Autopilot. For imbalanced data, which is common in financial services use cases, we showed that using objective metrics such as AUC and F1 along with the automatic minority class up-weighting can lead to high-quality models. Autopilot provides the flexibility of AutoML with the control and detail of a do-it-yourself approach by unveiling the underlying metadata and the code used to preprocess the data and train the models. Importantly, AutoPilot works on datasets of all sizes ranging from few MBs to hundreds of GBs without you having to set up the underlying infrastructure. Finally, note that Amazon SageMaker Studio provides a UI for you to build, train, and deploy models using Autopilot with little to no code. For more information about tuning, training, and deploying Autopilot models, see Create a machine learning model automatically with Amazon SageMaker Autopilot.
References
[1] Yeh, I. C., & Lien, C. H. (2009). The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Systems with Applications, 36(2), 2473-2480.
[2] Zieba, M., Tomczak, S. K., & Tomczak, J. M. (2016). Ensemble Boosted Trees with Synthetic Features Generation in Application to Bankruptcy Prediction. Expert Systems with Applications.
About the Authors
 Sumon Samanta is a Senior Specialist Architect for Global Financial Services at AWS. Previously, he worked as a Quantitative Developer at several investment banks to develop pricing and risk systems.
Sumon Samanta is a Senior Specialist Architect for Global Financial Services at AWS. Previously, he worked as a Quantitative Developer at several investment banks to develop pricing and risk systems.
 Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
 Miroslav Miladinovic is a Software Development Manager at Amazon SageMaker.
Miroslav Miladinovic is a Software Development Manager at Amazon SageMaker.
 Jean Baptiste Faddoul is an Applied Science Manager working on SageMaker Autopilot and Automatic Model Tuning
Jean Baptiste Faddoul is an Applied Science Manager working on SageMaker Autopilot and Automatic Model Tuning
 Yotam Elor is a Senior Applied Scientist at AWS Sagemaker. He works on Sagemaker Autopilot – AWS’s auto ML solution.
Yotam Elor is a Senior Applied Scientist at AWS Sagemaker. He works on Sagemaker Autopilot – AWS’s auto ML solution.