Artificial Intelligence
Fine-tune and deploy a Wav2Vec2 model for speech recognition with Hugging Face and Amazon SageMaker
Automatic speech recognition (ASR) is a commonly used machine learning (ML) technology in our daily lives and business scenarios. Applications such as voice-controlled assistants like Alexa and Siri, and voice-to-text applications like automatic subtitling for videos and transcribing meetings, are all powered by this technology. These applications take audio clips as input and convert speech signals to text, also referred as speech-to-text applications. In recent years, ASR services such as Amazon Transcribe let customers add speech to text capabilities with no prior machine learning experience required. Amazon Transcribe is a fully managed AI service that provides customers with pre-trained models that are continually improving, cost flexibility, and scalability across languages, regions, and volume.
For data scientists who want to build their own ASR models, many of the latest models can achieve a good performance, such as transformer-based models Wav2Vec2 and Speech2Text. Transformer is a sequence-to-sequence deep learning architecture originally proposed for machine translation. Now it’s extended to solve all kinds of natural language processing (NLP) tasks, such as text classification, text summarization, and ASR. The transformer architecture yields very good model performance and results in various NLP tasks; however, the models’ sizes (the number of parameters) as well as the amount of data they’re pre-trained on increase exponentially when pursuing better performance. It becomes very time-consuming and costly to train a transformer from scratch, for example training a BERT model from scratch could take 4 days and cost $6,912 (for more information, see The Staggering Cost of Training SOTA AI Models). Hugging Face, an AI company, provides an open-source platform where developers can share and reuse thousands of pre-trained transformer models. With the transfer learning technique, you can fine-tune your model with a small set of labeled data for a target use case. This reduces the overall compute cost, speeds up the development lifecycle, and lessens the carbon footprint of the community.
AWS announced collaboration with Hugging Face in 2021. Developers can easily work with Hugging Face models on Amazon SageMaker and benefit from both worlds. You can fine-tune and optimize all models from Hugging Face, and SageMaker provides managed training and inference services that offer high performance resources and high scalability via Amazon SageMaker distributed training libraries. This collaboration can help you accelerate your NLP tasks’ productization journey and realize business benefits.
This post shows how to use SageMaker to easily fine-tune the latest Wav2Vec2 model from Hugging Face, and then deploy the model with a custom-defined inference process to a SageMaker managed inference endpoint. Finally, you can test the model performance with sample audio clips, and review the corresponding transcription as output.
Wav2Vec2 background
Wav2Vec2 is a transformer-based architecture for ASR tasks and was released in September 2020. The following diagram shows its simplified architecture. For more details, see the original paper. As the diagram shows, the model is composed of a multi-layer convolutional network (CNN) as a feature extractor, which takes an input audio signal and outputs audio representations, also considered as features. They are fed into a transformer network to generate contextualized representations. This part of training can be self-supervised; the transformer can be trained with unlabeled speech and learn from it. Then the model is fine-tuned on labeled data with the Connectionist Temporal Classification (CTC) algorithm for specific ASR tasks. The base model we use in this post is Wav2Vec2-Base-960h, fine-tuned on 960 hours of Librispeech on 16 kHz sampled speech audio.

CTC is a character-based algorithm. During training, it’s able to demarcate each character of the transcription in the speech automatically, so the timeframe alignment isn’t required between audio signal and transcription. For example, if the audio clip says “Hello World,” we don’t need to know in which second the word “hello” is located. It saves a lot of labeling effort for ASR use cases. For more information about how the algorithm works, refer to Sequence Modeling With CTC.
Solution overview
In this post, we use the SUPERB (Speech processing Universal PERformance Benchmark) dataset available from the Hugging Face Datasets library, and fine-tune the Wav2Vec2 model and deploy it as a SageMaker endpoint for real-time inference for an ASR task. SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks.
The following diagram provides a high-level view of the solution workflow.
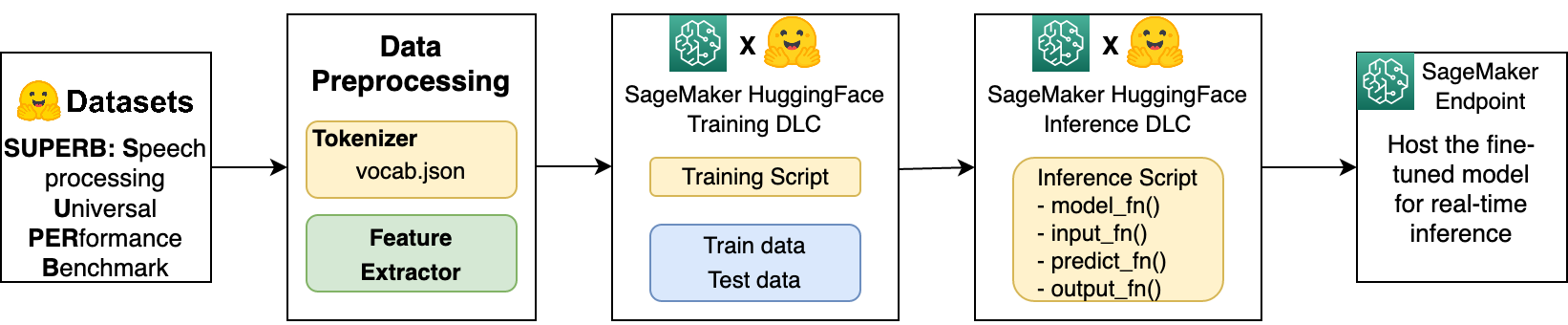
First, we show how to load and preprocess the SUPERB dataset in a SageMaker environment in order to obtain a tokenizer and feature extractor, which are required for fine-tuning the Wav2Vec2 model. Then we use SageMaker Script Mode for training and inference steps, which allows you to define and use custom training and inference scripts, and SageMaker provides supported Hugging Face framework Docker containers. For more information about training and serving Hugging Face models on SageMaker, see Use Hugging Face with Amazon SageMaker. This functionality is available through the development of Hugging Face AWS Deep Learning Containers (DLCs).
The notebook and code from this post are available on GitHub. The notebook is tested in both Amazon SageMaker Studio and SageMaker notebook environments.
Data preprocessing
In this section, we walk through the steps to preprocess the data.
Process the dataset
In this post we use SUPERB dataset, which you can load from the Hugging Face Datasets library directly using the load_dataset function. The SUPERB dataset also includes speaker_id and chapter_id; we remove these columns and only keep audio files and transcriptions to fine-tune the Wav2Vec2 model for an ASR task, which transcribes speech to text. To speed up the fine-tuning process for this example, we only take the test dataset from the original dataset, then split it into train and test datasets. See the following code:
After we process the data, the dataset structure is as follows:
Let’s print one data point from the train dataset and examine the information in each feature. ‘file’ is the audio file path where it’s saved and cached in the local repository. ‘audio’ contains three components: ‘path’ is the same as ‘file’, ‘array’ is the numerical representation of the raw waveform of the audio file in NumPy array format, and ‘sampling_rate’ shows the number of samples of audio recorded every second. ‘text’ is the transcript of the audio file.
Build a vocabulary file
The Wav2Vec2 model uses the CTC algorithm to train deep neural networks in sequence problems, and its output is a single letter or blank. It uses a character-based tokenizer. Therefore, we extract distinct letters from the dataset and build the vocabulary file using the following code:
Create a tokenizer and feature extractor
The Wav2Vec2 model contains a tokenizer and feature extractor. In this step, we use the vocab.json file that we created from the previous step to create the Wav2Vec2CTCTokenizer. We use Wav2Vec2FeatureExtractor to make sure that the dataset used in fine-tuning has the same audio sampling rate as the dataset used for pre-training. Finally, we create a Wav2Vec2 processor that can wrap the feature extractor and the tokenizer into one single processor. See the following code:
Prepare the train and test datasets
Next, we extract the array representation of the audio files and its sampling_rate from the dataset and process them using the processor, in order to have train and test data that can be consumed by the model:
Then we upload the train and test data to Amazon Simple Storage Service (Amazon S3) using the following code:
Fine-tune the Hugging Face model (Wav2Vec2)
We use SageMaker Hugging Face DLC script mode to construct the training and inference job, which allows you to write custom training and serving code and using Hugging Face framework containers that are maintained and supported by AWS.
When we create a training job using the script mode, the entry_point script, hyperparameters, its dependencies (inside requirements.txt), and input data (train and test datasets) are copied into the container. Then it invokes the entry_point training script, where the train and test datasets are loaded, training steps are performed, and model artifacts are saved in /opt/ml/model in the container. After training, artifacts in this directory are uploaded to Amazon S3 for later model hosting.
You can inspect the training script in the GitHub repo, in the scripts/ directory.
Create an estimator and start a training job
We use the Hugging Face estimator class to train our model. When creating the estimator, you need to specify the following parameters:
- entry_point – The name of the training script. It loads data from the input channels, configures training with hyperparameters, trains a model, and saves the model.
- source_dir – The location of the training scripts.
- transformers_version – The Hugging Face Transformers library version we want to use.
- pytorch_version – The PyTorch version that’s compatible with the Transformers library.
For this use case and dataset, we use one ml.p3.2xlarge instance, and the training job is able to finish in around 2 hours. You can select a more powerful instance with more memory and GPU to reduce the training time; however, it incurs more cost.
When you create a Hugging Face estimator, you can configure hyperparameters and provide a custom parameter into the training script, such as vocab_url in this example. Also, you can specify the metrics in the estimator, parse the logs of these metrics, and send them to Amazon CloudWatch to monitor and track the training performance. For more details, see Monitor and Analyze Training Jobs Using Amazon CloudWatch Metrics.
In the following figure of CloudWatch training job logs, you can see that, after 10 epochs of training, the model evaluation metrics WER (word error rate) can achieve around 0.17 for the subset of the SUPERB dataset. WER is a commonly used metric to evaluate speech recognition model performance, and the objective is to minimize it. You can increase the number of epochs or use the full SUPERB dataset to improve the model further.

Deploy the model as an endpoint on SageMaker and run inference
In this section, we walk through the steps to deploy the model and perform inference.
Inference script
We use the SageMaker Hugging Face Inference Toolkit to host our fine-tuned model. It provides default functions for preprocessing, predicting, and postprocessing for certain tasks. However, the default capabilities can’t inference our model properly. Therefore, we defined the custom functions model_fn(), input_fn(), predict_fn(), and output_fn() in the inference.py script to override the default settings with custom requirements. For more details, refer to the GitHub repo.
As of January 2022, the Inference Toolkit can inference tasks from architectures that end with 'TapasForQuestionAnswering', 'ForQuestionAnswering', 'ForTokenClassification', 'ForSequenceClassification', 'ForMultipleChoice', 'ForMaskedLM', 'ForCausalLM', 'ForConditionalGeneration', 'MTModel', 'EncoderDecoderModel','GPT2LMHeadModel', and 'T5WithLMHeadModel'. The Wav2Vec2 model is not currently supported.
You can inspect the full inference script in the GitHub repo, in the scripts/ directory.
Create a Hugging Face model from the estimator
We use the Hugging Face Model class to create a model object, which you can deploy to a SageMaker endpoint. When creating the model, specify the following parameters:
- entry_point – The name of the inference script. The methods defined in the inference script are implemented to the endpoint.
- source_dir – The location of the inference scripts.
- transformers_version – The Hugging Face Transformers library version we want to use. It should be consistent with the training step.
- pytorch_version – The PyTorch version that is compatible with the Transformers library. It should be consistent with the training step.
- model_data – The Amazon S3 location of a SageMaker model data .tar.gz file.
When you create a predictor by using the model.deploy function, you can change the instance count and instance type based on your performance requirements.
Inference audio files
After you deploy the endpoint, you can run prediction tests to check the model performance. You can download an audio file from the S3 bucket by using the following code:
Alternatively, you can download a sample audio file to run the inference request:
The predicted result is as follows:
Clean up
When you’re finished using the solution, delete the SageMaker endpoint to avoid ongoing charges:
Conclusion
Automatic speech recognition technology has matured in recent years and ASR services such as Amazon Transcribe let customers add speech to text capabilities with no prior machine learning experience required. In this post, we show how data scientists who want to build their own ASR models can fine-tune the pre-trained Wav2Vec2 model on SageMaker using a Hugging Face estimator, and also how to host the model on SageMaker as a real-time inference endpoint using the SageMaker Hugging Face Inference Toolkit. For both training and inference steps, we provided custom defined scripts for greater flexibility, which are enabled and supported by SageMaker Hugging Face DLCs. You can use the method from this post to fine-tune a We2Vec2 model with your own datasets, or to fine-tune and deploy a different transformer model from Hugging Face.
Check out the notebook and code of this project from GitHub, and let us know your comments. For more comprehensive information, see Hugging Face on SageMaker and Use Hugging Face with Amazon SageMaker.
In addition, Hugging Face and AWS announced a partnership in 2022 that makes it even easier to train Hugging Face models on SageMaker. This functionality is available through the development of Hugging Face AWS DLCs. These containers include the Hugging Face Transformers, Tokenizers, and Datasets libraries, which allow us to use these resources for training and inference jobs. For a list of the available DLC images, see Available Deep Learning Containers Images. They are maintained and regularly updated with security patches. You can find many examples of how to train Hugging Face models with these DLCs and the Hugging Face Python SDK in the following GitHub repo.
About the Author
 Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her main areas of interests are deep learning, computer vision, NLP, and time series data prediction. In her spare time, she enjoys reading novels and hiking in national parks in the UK.
Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her main areas of interests are deep learning, computer vision, NLP, and time series data prediction. In her spare time, she enjoys reading novels and hiking in national parks in the UK.