Artificial Intelligence
Getting started with Amazon SageMaker Feature Store
In a machine learning (ML) journey, one crucial step before building any ML model is to transform your data and design features from your data so that your data can be machine-readable. This step is known as feature engineering. This can include one-hot encoding categorical variables, converting text values to vectorized representation, aggregating log data to a daily summary, and more. The quality of your features directly influences your model predictability, and often needs a few iterations until a model reaches an ideal level of accuracy. Data scientists and developers can easily spend 60% of their time designing and creating features, and the challenges go beyond writing and testing your feature engineering code. Features built at different times and by different teams aren’t consistent. Extensive and repetitive feature engineering work is often needed when productionizing new features. Difficulty tracking versions and up-to-date features aren’t easily accessible.
To address these challenges, Amazon SageMaker Feature Store provides a fully managed central repository for ML features, making it easy to securely store and retrieve features without the heavy lifting of managing the infrastructure. It lets you define groups of features, use batch ingestion and streaming ingestion, and retrieve the latest feature values with low latency.
For an introduction to Feature Store and a basic use case using a credit card transaction dataset for fraud detection, see New – Store, Discover, and Share Machine Learning Features with Amazon SageMaker Feature Store. For further exploration of its features, see Using streaming ingestion with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time.
For this post, we focus on the integration of Feature Store with other Amazon SageMaker features to help you get started quickly. The associated sample notebook and the following video demonstrate how you can apply these concepts to the development of an ML model to predict the risk of heart failure.
The components of Feature Store
Feature Store is a centralized hub for features and associated metadata. Features are defined and stored in a collection called a feature group. You can visualize a feature group as a table in which each column is a feature, with a unique identifier for each row. In principle, a feature group is composed of features and values specific to each feature. A feature group’s definition is composed of a list of the following:
- Feature definitions – These consist of a name and data types.
- A record identifier name – Each feature group is defined with a record identifier name. It should be a unique ID to identify each instance of the data, for example, primary key, customer ID, transaction ID, and so on.
- Configurations for its online and offline store – You can create an online or offline store. The online store is used for low-latency, real-time inference use cases, and the offline store is used for training and batch inference.
The following diagram shows how you can use Feature Store as part of your ML pipeline. First, you read in your raw data and transform it to features ready for exploration and modeling. Then you can create a feature store, configure it to an online or offline store, or both. Next you can ingest data via streaming to the online and offline store, or in batches directly to the offline store. After your feature store is set up, you can create a model using data from your offline store and access it for real time inference or batch inference.

For more hands-on experience, follow the notebook example for a step-by-step guide to build a feature store, train a model for fraud detection, and access the feature store for inference.
Export data from Data Wrangler to Feature Store
Because Feature Store can ingest data in batches, you can author features using Amazon SageMaker Data Wrangler, create feature groups in Feature Store, and ingest features in batches using a SageMaker Processing job with a notebook exported from Data Wrangler. This mode allows for batch ingestion into the offline store. It also supports ingestion into the online store if the feature group is configured for both online and offline use.
To start off, after you complete your data transformation steps and analysis, you can conveniently export your data preparation workflow into a notebook with one click. When you export your flow steps, you have the option of exporting your processing code to a notebook that pushes your processed features to Feature Store.

Choose Export step and Feature Store to automatically create your notebook. This notebook recreates the manual steps you created, creates a feature group, and adds features to an offline or online feature store, allowing you easily rerun your manual steps.

This notebook defines the schema instead of auto-detection of data types for each column of the data, with the following format:
For more information on how to load the schema, map it, and add it as a FeatureDefinition that you can use to create the FeatureGroup, see Export to the SageMaker Feature Store.
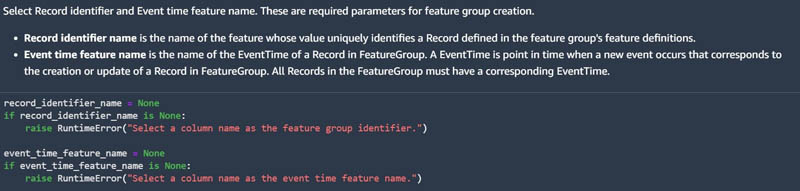
Additionally, you must specify a record identifier name and event time feature name in the following code:
- The
record_identifier_nameis the name of the feature whose value uniquely identifies a record defined in the feature store. - An
EventTimeis a point in time when a new event occurs that corresponds to the creation or update of a record in a feature. All records in the feature group must have a correspondingEventTime.
The notebook creates an offline store and the online by default with the following configuration set to True:
You can also disable an online store by setting EnableOnlineStore to False in the online and offline store configurations.
You can then run the notebook, and the notebook creates a feature group and processing job to process data in scale. The offline store is located in an Amazon Simple Storage Service (Amazon S3) bucket in your AWS account. Because Feature Store is integrated with Amazon SageMaker Studio, you can visualize the feature store by choosing Components and registries in the navigation pane, choosing Feature Store on the drop-down menu, and then finding your feature store on the list. You can check for feature definitions, manage feature group tags, and generate queries for the offline store.

Build a training set from an offline store
Now that you have created a feature store from your processed data, you can build a training dataset from your offline store by using services such as Amazon Athena, AWS Glue, or Amazon EMR. In the following example, because Feature Store automatically builds an AWS Glue Data Catalog when you create feature groups, you can easily create a training dataset with feature values from the feature group. This is done by utilizing the auto-built Data Catalog.
First, create an Athena query for your feature group with the following code. The table_name is the AWS Glue table that is automatically generated by Feature Store.
You can then write your query using SQL on your feature group, and run the query with the .run() command and specify your S3 bucket location for the dataset to be saved there. You can modify the query to include any operations needed for your data like joining, filtering, ordering, and so on. You can further process the output DataFrame until it’s ready for modeling, then upload it to your S3 bucket so that your SageMaker trainer can directly read the input from the S3 bucket.
Access your Feature Store for inference
After you build a model from the training set, you can access your online store conveniently to fetch a record and make predictions using the deployed model. Feature Store can be especially useful in supplementing data for inference requests because of the low-latency GetRecord functionality. In this example, you can use the following code to query the online feature group to build an inference request:
You can then call the deployed model predictor to generate a prediction for the selected record:
Integrate Feature Store in a SageMaker pipeline
Feature Store also integrates with Amazon SageMaker Pipelines to create, add feature search and discovery to, and reuse automated ML workflows. As a result, it’s easy to add feature search, discovery, and reuse to your ML workflow. The following code shows you how to configure the ProcessingOutput to directly write the output to your feature group instead of Amazon S3, so that you can maintain your model features in a feature store:
Conclusion
In this post, we explored how Feature Store can be a powerful tool in your ML journey. You can easily export your data processing and feature engineering results to a feature group and build your feature store. After your feature store is all set up, you can explore and build training sets from your offline store, taking advantage of its integration with other AWS analytics services such as Athena, AWS Glue, and Amazon EMR. After you train and deploy a model, you can fetch records from your online store for real-time inference. Lastly, you can add a feature store as a part of a complete SageMaker pipeline in your ML workflow. Feature Store makes it easy to store and retrieve features as needed in ML development.
Give it a try, and let us know what you think!
About the Author
As a data scientist and consultant, Zoe Ma has helped bring the latest tools and technologies and data-driven insights to businesses and enterprises. In her free time, she loves painting and crafting and enjoys all water sports.
Courtney McKay is a consultant. She is passionate about helping customers drive measurable ROI with AI/ML tools and technologies. In her free time, she enjoys camping, hiking and gardening.