Artificial Intelligence
How Latent Space used the Amazon SageMaker model parallelism library to push the frontiers of large-scale transformers
This blog is co-authored by Sarah Jane Hong CSO, Darryl Barnhart CTO, and Ian Thompson CEO of Latent Space and Prem Ranga of AWS.
Latent space is a hidden representation of abstract ideas that machine learning (ML) models learn. For example, “dog,” “flower,” or “door” are concepts or locations in latent space. At Latent Space, we’re working on an engine that allows you to manipulate and explore this space with both language and visual prompts. The Latent Space team comes from two fields that have long had little overlap: graphics and natural language processing (NLP). Traditionally, the modalities of images and text have been handled separately, each with their own history of complex, expensive, and fragile feature engineering. NLP tasks like document understanding or question answering have usually had little in common with vision tasks like scene understanding or rendering, and usually we use very different approaches and models for each task. But this is rapidly changing.
This merging of modalities in a single shared latent space unlocks a new generation of creative and commercial applications, from gaming to document understanding. But unlocking these new applications in a single model opens up new scaling challenges, as highlighted in “The Bitter Lesson” by Richard Sutton, and the exciting work in the last few years on scaling laws. To make this possible, Latent Space is working on cutting-edge research to fuse these modalities in a single model, but also to scale and do so efficiently. This is where model parallelism comes in.
Amazon SageMaker‘s unique automated model partitioning and efficient pipelining approach made our adoption of model parallelism possible with little engineering effort, and we scaled our training of models beyond 1 billion parameters (we use the p4d.24xlarge A100 instances), which is an important requirement for us. Furthermore, we observed that when training with a 16 node, eight GPU training setup with the SageMaker model parallelism library, we recorded a 38% improvement in efficiency compared to our previous training runs.
Challenges with training large-scale transformers
At Latent Space, we’re fusing language and vision in transformer models with billions of parameters to support “out of distribution” use cases from a user’s imagination or that would occur in the real world but not in our training data. We’re handling the challenges inherent in scaling to billions of parameters and beyond in two different ways:
- Retrieval-augmented generation
- The Amazon SageMaker model parallelism library
Information retrieval techniques have long been a key component of search engines and QA tasks. Recently, exciting progress has been made combining classic IR techniques with modern transformers, specifically for question answering tasks where a model is trained jointly with a neural retriever that learns to retrieve relevant documents to help answer questions. For an overview, see the recent work from FAIR in Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models and Fusion-in-Decoder, Google Brain’s REALM, and Nvidia’s Neural Retriever for question answering.
While retrieval-augmented techniques help with costs and efficiency, we are still unable to fit the model on a single GPU for our largest model. This means that we need to use model parallelism to train it. However, due to the nature of our retrieval architecture, designing our model splitting was challenging because of interdependencies between retrieved contexts across training inputs. Furthermore, even if we determine how we split our model, introducing model parallelism was a significant engineering task for us to do manually across our research and development lifecycle.
The SageMaker model parallelism library
Model parallelism is the process of splitting a model up between multiple devices or nodes (such as GPU-equipped instances) and creating an efficient pipeline to train the model across these devices to maximize GPU utilization. The model parallelism library in SageMaker makes model parallelism more accessible by providing automated model splitting, also referred to as automated model partitioning and sophisticated pipeline run scheduling. The model splitting algorithms can optimize for speed or memory consumption. The library uses a partitioning algorithm that balances memory, minimizes communication between devices, and optimizes performance.
Automated model partitioning
For our PyTorch use case, the model parallel library internally runs a tracing step (in the first training step) that constructs the model graph and determines the tensor and parameter shapes. It then constructs a tree, which consists of the nested nn.Module objects in the model, as well as additional data gathered from tracing, such as the amount of stored nn.Parameters, and runtime for each nn.Module.
The library then traverses this tree from the root and runs a partitioning algorithm that balances computational load and memory use, and minimizes communication between instances. If multiple nn.Modules share the same nn.Parameter, these modules are placed on the same device to avoid maintaining multiple versions of the same parameter. After the partitioning decision is made, the assigned modules and weights are loaded to their devices.
Pipeline run scheduling
Another core feature of the SageMaker distributed model parallel library is pipelined runs, which determine the order in which computations are made and data is processed across devices during model training. Pipelining is based on splitting a mini-batch into microbatches, which are fed into the training pipeline one by one and follow a run schedule defined by the library runtime.
The microbatch pipeline ensures that all the GPUs are fully utilized, which is something we would have to build ourselves, but with the model parallelism library this happens neatly behind the scenes. Lastly, we can use Amazon FSx, which is important to ensure our read speeds are fast given the number of files being read during the training of a multimodal model with retrieval.
Training architecture
The following diagram represents how we set up our training architecture. Our primary objectives were to improve training speed and reduce costs. The image and language transformers we are training are highly complex, with a significantly large number of layers and weights inside, running to billions of parameters, all of which makes them unable to fit in the memory of a single node. Each node carries a subset of the model, through which the data flows and the transformations are shared and compiled. We setup 16 p4d.24xlarge instances each with eight GPUs using the following architecture representation:
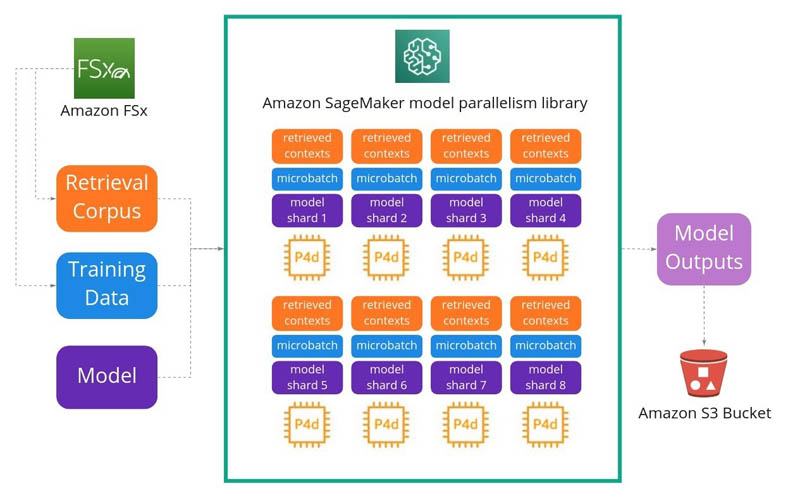
As we scale up our models, a common trend is to have everything stored in the weights of the network. However, for practical purposes, we want to augment our models to learn how to look for relevant contexts to help with the task of rendering. This enables us to keep our serving costs down without compromising on image quality. We use a large transformer-based NLP model and as mentioned before, we observed a 38% increase in training efficiency with the SageMaker model parallelism library as shown by the following:
- We need an allreduce for every computation in the case of tensor level parallelism. This takes O(log_2 n) parallel steps. That is n machines taking O(n) steps, for O(n log_2 n) total operations.
- For pipeline parallelism, we require O(1) parallel steps for passing data down the pipeline
- Given 16 machines with eight GPUs, we have O(1) cost for pipeline parallel, and O(log_2(8)) = O(3) cost for depth-wise model parallel.
- In this case, we see that the network cost is reduced to 1/3rd by switching to pipeline parallel that what we use with SageMaker model parallelism, and the overall training cost reduces to 1/2 + 1/2 * 1/log_2(16) = 0.625 of the original cost leading to a corresponding efficiency improvement.
In general, when the need warrants distributed training (issues with scaling model size or training data), we can follow a set of best practices to determine what approach works best.
Best practices for distributed training
Based on our experience, we suggest starting with a distributed data parallel approach. Distributed data parallelism such as the SageMaker distributed data parallel library resolves most of the networking issues with model replicas, so you should fit models into the smallest number of nodes, then replicate to scale batch size as needed.
If you run out of memory during training, as we did in this scenario, you may want to switch to a model parallel approach. However, consider these alternatives before trying model parallel training:
- On NVIDIA Tensor Core-equipped hardware, use mixed-precision training to create speedup and reduce memory consumption.
- Reduce the batch size (or reduce image resolution or NLP sequence length, if possible).
Additionally, we prefer model designs that do not have batch normalization as described in High-performance large-scale image recognition without normalization. If it cannot be avoided, ensure batch normalization is synced across devices. When you use distributed training, your batch is split across GPUs, so accurate batch statistics require synchronization across all devices. Without this, the normalization will have increased error and thereby impair convergence.
Start with model parallel training when you have the following constraints:
- Your model doesn’t fit on a single device
- Due to your model size, you’re facing limitations in choosing larger batch sizes, such as if your model weights take up most of your GPU memory and you’re forced to choose a smaller, suboptimal batch size
When optimizing for performance, do the following:
- Use pipelining for inter-node communications to minimize latency and increase throughput
- Keep pipelines as short as possible to minimize any bubbles. The number of microbatches should be tuned to balance computational efficiency with bubble size, and be at least the pipeline length. If needed you can form microbatches at the token level as described in TeraPipe: Token Level Pipeline Parallelism for training large-scale language models
When optimizing for cost, use SageMaker managed Spot Instances for training. This can optimize the cost of training models up to 90% over On-Demand instances. SageMaker manages the Spot interruptions on your behalf.
Other factors to consider:
- Within a node when there is a fast interconnect, it’s more nuanced. If there is ample intra-node network capacity, reshuffling data for more optimal compute may show a benefit.
- If activations are much larger than weight tensors, a sharded optimizer may also help. Please refer to ZeRO for more details.
The following table provides some common training scaleup scenarios and how you can configure them on AWS.
| Scenario | When does it apply? | Solution |
| Scaling from a single GPU to many GPUs | When the amount of training data or the size of the model is too large | Change to a multi-GPU instance such as p3.16xlarge, which has eight GPUs, with the data and processing split across the eight GPUs, and producing a near-linear speedup in the time it takes to train your model. |
| Scaling from a single instance to multiple instances | When the scaling needs extend beyond changing the instance size | Scale the number of instances with the SageMaker Python SDK’s estimator function by setting your instance_type to p3.16xlarge and instance_count to 2. Instead of the eight GPUs on a single p3.16xlarge, you have 16 GPUs across two identical instances. Consider using the SageMaker distributed data parallel library. |
| Selecting a model parallel approach for training | When encountering out of memory errors during training | Switch to a model parallel approach using the SageMaker distributed model parallel library. |
| Network performance for inter-node communications | For distributed training with multiple instances (for example, communication between the nodes in the cluster when doing an AllReduce operation) | Your instances need to be in the same Region and same Availability Zone. When you use the SageMaker Python SDK, this is handled for you. Your training data should also be in the same Availability Zone. Consider using the SageMaker distributed data parallel library. |
| Optimized GPU, network, and Storage | For large scale distributed training needs | The p4d.24xlarge instance type was designed for fast local storage and a fast network backplane with up to 400 gigabits, and we highly recommend it as the most performant option for distributed training. |
Conclusion
With the model parallel library in SageMaker, we get a lot of the benefits out of the box, such as automated model partitioning and efficient pipelining. In this post, we shared our challenges with our ML use case, our considerations on different training approaches, and how we used the Amazon SageMaker model parallelism library to speed up our training. Best of all, it can now take only a few hours to adopt best practices for model parallelism and performance improvements described here. If this post helps you or inspires you to solve a problem, we would love to hear about it! Please share your comments and feedback.
References
For more information, please see following:
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Facebook’s blog on retrieval augmented generation architecture.
- Scaling Laws for Autoregressive Generative Modeling
- REALM: Retrieval-Augmented Language Model Pre-Training
- Distilling Knowledge from Reader to Retriever for Question Answering
- High-performance large-scale image recognition without normalization
- TeraPipe: Token Level Pipeline Parallelism for training large-scale language models
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
About the Authors
 Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an autonomous vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Atlanta, GA. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an autonomous vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
 Sarah Jane Hong is the co-founder and Chief Science Officer at Latent Space. Her background lies at the intersection of human-computer interaction and machine learning. She previously led NLP research at Sonar (acquired by Marchex), which serves businesses in the conversational AI space. She is also an esteemed AR/VR developer, having received awards and fellowships from Oculus, Mozilla Mixed Reality, and Microsoft Hololens.
Sarah Jane Hong is the co-founder and Chief Science Officer at Latent Space. Her background lies at the intersection of human-computer interaction and machine learning. She previously led NLP research at Sonar (acquired by Marchex), which serves businesses in the conversational AI space. She is also an esteemed AR/VR developer, having received awards and fellowships from Oculus, Mozilla Mixed Reality, and Microsoft Hololens.
 Darryl Barnhart is the co-founder and Chief Technology Officer at Latent Space. He is a seasoned developer with experience in GPU acceleration, computer graphics, large-scale data, and machine learning. Other passions include mathematics, game development, and the study of information.
Darryl Barnhart is the co-founder and Chief Technology Officer at Latent Space. He is a seasoned developer with experience in GPU acceleration, computer graphics, large-scale data, and machine learning. Other passions include mathematics, game development, and the study of information.
 Ian Thompson is the founder and CEO at Latent Space. Ian is an engineer and researcher inspired by the “adjacent possible” — technologies about to have a big impact on our lives. Currently focused on simplifying and scaling multimodal representation learning to help build safe and creative AI. He previously helped build companies in graphics/virtual reality (AltspaceVR, acquired by Microsoft) and education/NLP (HSE).
Ian Thompson is the founder and CEO at Latent Space. Ian is an engineer and researcher inspired by the “adjacent possible” — technologies about to have a big impact on our lives. Currently focused on simplifying and scaling multimodal representation learning to help build safe and creative AI. He previously helped build companies in graphics/virtual reality (AltspaceVR, acquired by Microsoft) and education/NLP (HSE).