Artificial Intelligence
How SIGNAL IDUNA operationalizes machine learning projects on AWS
This post is co-authored with Jan Paul Assendorp, Thomas Lietzow, Christopher Masch, Alexander Meinert, Dr. Lars Palzer, Jan Schillemans of SIGNAL IDUNA.
At SIGNAL IDUNA, a large German insurer, we are currently reinventing ourselves with our transformation program VISION2023 to become even more customer oriented. Two aspects are central to this transformation: the reorganization of large parts of the workforce into cross functional and agile teams, and becoming a truly data-driven company. Here, the motto “You build it, you run it” is an important requirement for a cross-functional team that builds a data or machine learning (ML) product. This places tight constraints on how much work team can spend to productionize and run a product.
This post shows how SIGNAL IDUNA tackles this challenge and utilizes the AWS Cloud to enable cross-functional teams to build and operationalize their own ML products. To this end, we first introduce the organizational structure of agile teams, which sets the central requirements for the cloud infrastructure used to develop and run a product. Next, we show how three central teams at SIGNAL IDUNA enable cross-functional teams to build data products in the AWS Cloud with minimal assistance, by providing a suitable workflow and infrastructure solutions that can easily be used and adapted. Finally, we review our approach and compare it with a more classical approach where development and operation are separated more strictly.
Agile@SI – the Foundation of Organizational Change
Since the start of 2021, SIGNAL IDUNA has begun placing its strategy Agile@SI into action and establishing agile methods for developing customer-oriented solutions across the entire company [1]. Previous tasks and goals are now undertaken by cross-functional teams, called squads. These squads employ agile methods (such as the Scrum framework), make their own decisions, and build customer-oriented products. Typically, the squads are located in business divisions, such as marketing, and many have a strong emphasis on building data-driven and ML powered products. As an example, typical use cases in insurance are customer churn prediction and product recommendation.
Due to the complexity of ML, creating an ML solution by a single squad is challenging, and thus requires the collaboration of different squads.
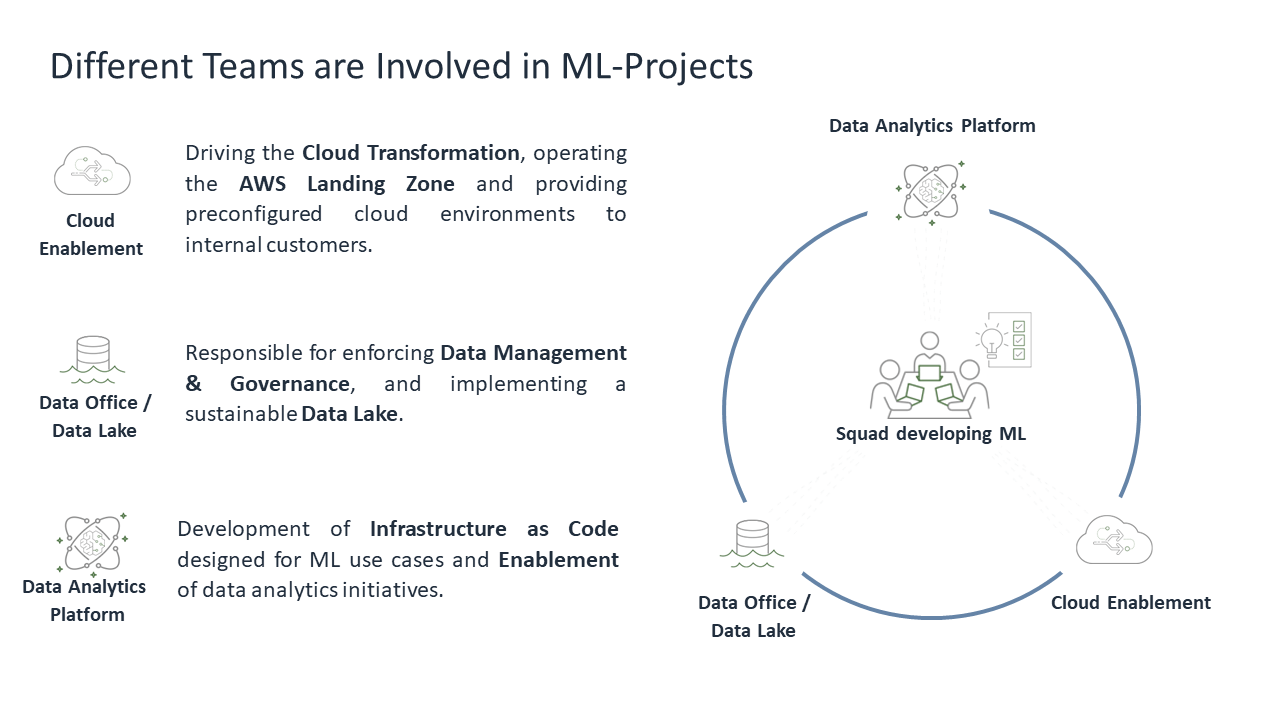
SIGNAL IDUNA has three essential teams that support creating ML solutions. Surrounded by these three squads is the team that is responsible for the development and the long-term operation and of the ML solution. This approach follows the AWS shared responsibility model [2].
In the image above, all of the squads are represented in an overview.
Cloud Enablement
The underlying cloud infrastructure for the entire organization is provided by the squad Cloud Enablement. It is their task to enable the teams to build products upon cloud technologies on their own. This improves the time to market building new products like ML, and it follows the principle of “You build it, you run it”.
Data Office/Data Lake
Moving data into the cloud, as well as finding the right dataset, is supported by the squad Data Office/Data Lake. They set up a data catalogue that can be used to search and select required datasets. Their aim is to establish data transparency and governance. Additionally, they are responsible for establishing and operating a Data Lake that helps teams to access and process relevant data.
Data Analytics Platform
Our squad Data Analytics Platform (DAP) is a cloud and ML focused team at SIGNAL IDUNA that is proficient in ML engineering, data engineering, as well as data science. We enable internal teams using public cloud for ML by providing infrastructure components and knowledge. Our products and services are presented in detail in the following section.
Enabling Cross-Functional Teams to Build ML Solutions
To enable cross-functional teams at SIGNAL IDUNA to build ML solutions, we need a fast and versatile way to provision reusable cloud infrastructure as well as an efficient workflow for onboarding teams to utilize the cloud capabilities.
To this end, we created a standardized onboarding and support process, and provided modular infrastructure templates as Infrastructure as Code (IaC). These templates contain infrastructure components designed for common ML use cases that can be easily tailored to the requirements of a specific use case.
The Workflow of Building ML Solutions
There are three main technical roles involved in building and operating ML solutions: The data scientist, ML engineer, and a data engineer. Each role is part of the cross-functional squad and has different responsibilities. The data scientist has the required domain knowledge of functional as well as technical requirements of the use case. The ML engineer specializes in building automated ML solutions and model deployment. And the data engineer makes sure that the data flows from on-premises and within the cloud.
The process of providing the platform is as follows:
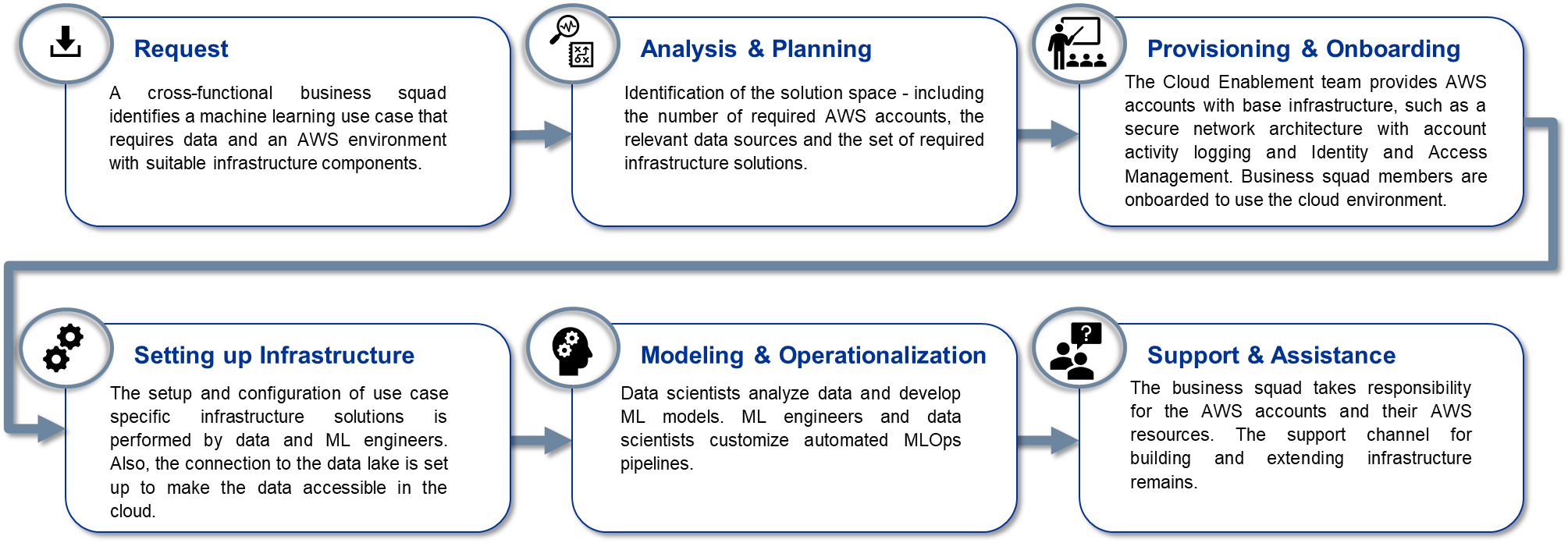
The infrastructure of the specific use case is defined in IaC and versioned in a central project repository. This also includes pipelines for model training and deployment, as well as other data science related code artifacts. Data scientists, ML engineers, and data engineers have access to the project repository and can configure and update all of the infrastructure code autonomously. This enables the team to rapidly alter the infrastructure if needed. However, the ML engineer can always support in developing and updating infrastructure or ML models.
Reusable and Modular Infrastructure Components
The hierarchical and modular IaC resources are implemented in Terraform and include infrastructure for common data science and ETL use cases. This lets us reuse infrastructure code and enforce required security and compliance policies, such as using AWS Key Management Service (KMS) encryption for data, as well as encapsulating infrastructure in Amazon Virtual Private Cloud (VPC) environments without direct internet access.
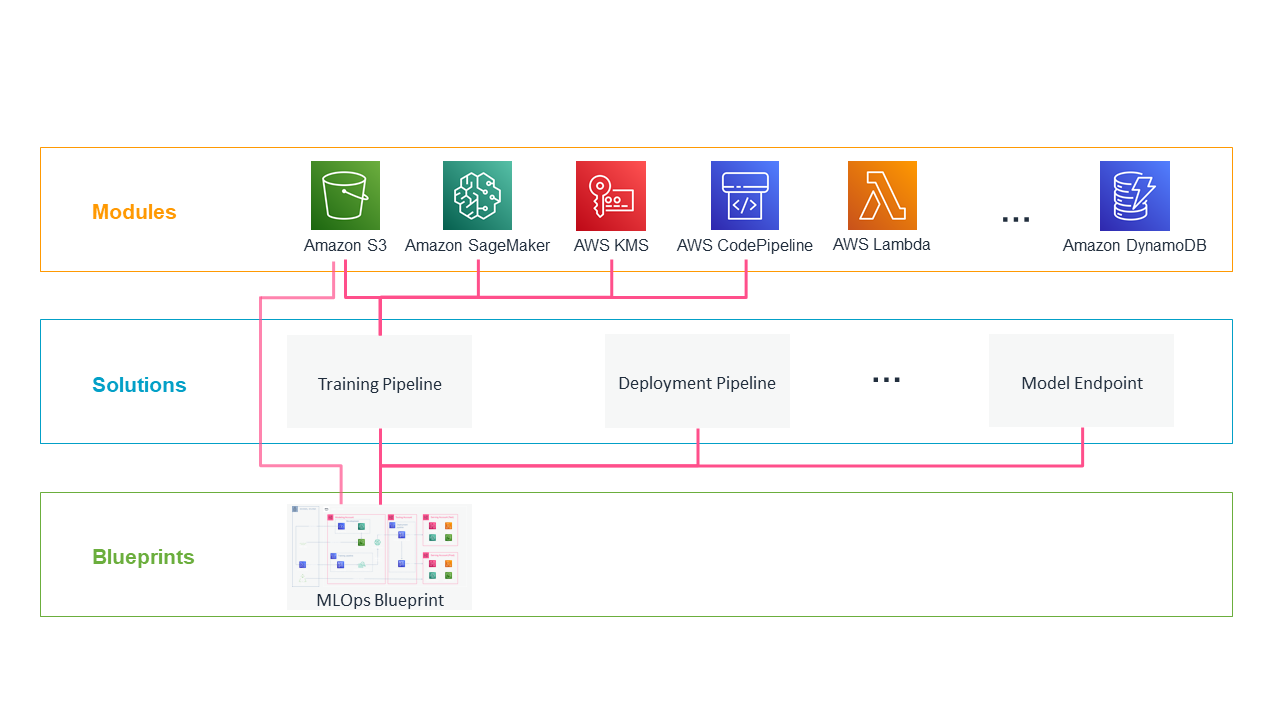
The hierarchical IaC structure is as follows:
- Modules encapsulate basic AWS services with the required configuration for security and access management. This includes best practice configurations such as the prevention of public access to Amazon Simple Storage Service (S3) buckets, or enforcing encryption for all files stored.
- In some cases, you need a variety of services to automate processes, such as to deploy ML models in different stages. Therefore, we defined Solutions as a bundle of different modules in a joint configuration for different types of tasks.
- In addition, we offer complete Blueprints that combine solutions in different environments to meet the many potential needs of a project. In our MLOps blueprint, we define a deployable infrastructure for training, provisioning, and monitoring ML models that are integrated and distributed in AWS accounts. We discuss further details in the next section.
These products are versioned in a central repository by the DAP squad. This lets us continuously improve our IaC and consider new features from AWS, such as Amazon SageMaker Model Registry. Each squad can reference these resources, parameterize them as needed, and finally deploy them in their own AWS accounts.
MLOps Architecture
We provide a ready-to-use blueprint with specific solutions to cover the entire MLOps process. The blueprint contains infrastructure distributed over four AWS accounts for building and deploying ML models. This lets us isolate resources and workflows for the different steps in the MLOps process. The following figure shows the multi-account architecture, and we describe how the responsibility over specific steps of the process is divided between the different technical roles.
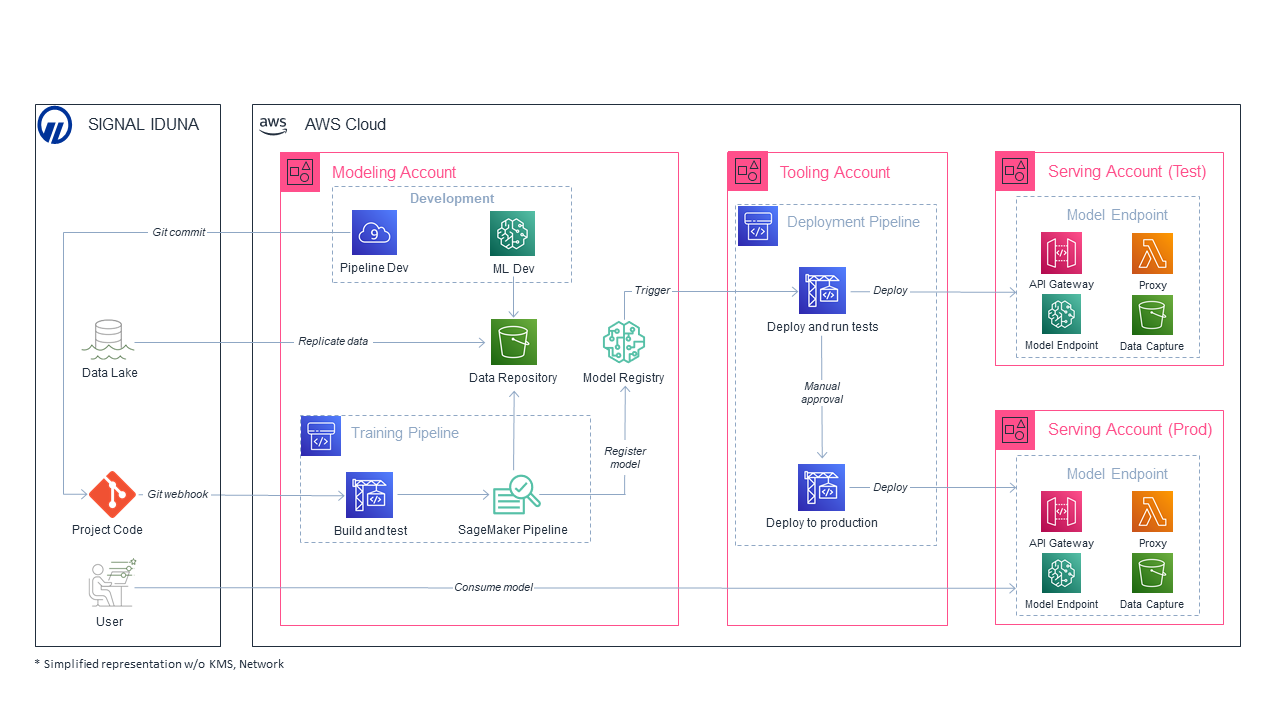
The modeling account includes services for the development of ML models. First, the data engineer employs an ETL process to provide relevant data from the SIGNAL IDUNA data lake, the centralized gateway for data-driven workflows in the AWS Cloud. Subsequently, the dataset can be utilized by the data scientist to train and evaluate model candidates. Once ready for extensive experiments, a model candidate is integrated into an automated training pipeline by the ML engineer. We use Amazon SageMaker Pipelines to automate training, hyperparameter tuning, and model evaluation at scale. This also includes model lineage and a standardized approval mechanism for models to be staged for deployment into production. Automated unit tests and code analysis ensure quality and reliability of the code for each step of the pipeline, such as data preprocessing, model training, and evaluation. Once a model is evaluated and approved, we use Amazon SageMaker ModelPackages as an interface to the trained model and relevant meta data.
The tooling account contains automated CI/CD pipelines with different stages for testing and deployment of trained models. In the test stage, models are deployed into the serving-nonprod account. Although model quality is evaluated in the training pipeline prior to the model being staged for production, here we run performance and integration tests in an isolated testing environment. After passing the testing stage, models are deployed into the serving-prod account to be integrated into production workflows.
Separating the stages of the MLOps workflow into different AWS accounts lets us isolate development and testing from production. Therefore, we can enforce a strict access and security policy. Furthermore, tailored IAM roles ensure that specific services can only access data and other services required for its scope, following the principle of least privilege. Services within the serving environments can additionally be made accessible to external business processes. For example, a business process can query an endpoint within the serving-prod environment for model predictions.
Benefits of our Approach
This process has many advantages as compared to a strict separation of development and operation for both the ML models, as well as the required infrastructure:
- Isolation: Every team receives their own set of AWS accounts that are completely isolated from other teams’ environments. This makes it easy to manage access rights and keep the data private to those who are entitled to work with it.
- Cloud enablement: Team members with little prior experience in cloud DevOps (such as many data scientists) can easily watch the whole process of designing and managing infrastructure since (almost) nothing is hidden from them behind a central service. This creates a better understanding of the infrastructure, which can in turn help them create data science products more efficiently.
- Product ownership: The use of preconfigured infrastructure solutions and managed services keeps the barrier to managing an ML product in production very low. Therefore, a data scientist can easily take ownership of a model that is put into production. This minimizes the well-known risk of failing to put a model into production after development.
- Innovation: Since ML engineers are involved long before a model is ready to put into production, they can create infrastructure solutions suitable for new use cases while the data scientists develop an ML model.
- Adaptability: Since the IaC solution developed by DAP are freely available, any team can easily adapt these to match a specific need for their use case.
- Open source: All new infrastructure solutions can easily be made available via the central DAP code repo to be used by other teams. Over time, this will create a rich code base with infrastructure components tailored to different use cases.
Summary
In this post, we illustrated how cross-functional teams at SIGNAL IDUNA are being enabled to build and run ML products on AWS. Central to our approach is the usage of a dedicated set of AWS accounts for each team in combination with bespoke IaC blueprints and solutions. These two components enable a cross-functional team to create and operate production quality infrastructure. In turn, they can take full end-to-end ownership of their ML products.
Refer to Amazon SageMaker Model Building Pipelines – Amazon SageMaker to learn more.
Find more information on ML on AWS on our official page.
References
[1] https://www.handelsblatt.com/finanzen/versicherungsbranche-vorbild-spotify-signal-iduna-wird-von-einer-handwerker-versicherung-zum-agilen-konzern/27381902.html
[2] https://blog.crisp.se/wp-content/uploads/2012/11/SpotifyScaling.pdf
[3] https://aws.amazon.com/compliance/shared-responsibility-model/
About the Authors
 Jan Paul Assendorp is an ML engineer with a strong data science focus. He builds ML models and automates model training and the deployment into production environments.
Jan Paul Assendorp is an ML engineer with a strong data science focus. He builds ML models and automates model training and the deployment into production environments.
 Thomas Lietzow is the Scrum Master of the squad Data Analytics Platform.
Thomas Lietzow is the Scrum Master of the squad Data Analytics Platform.
 Christopher Masch is the Product Owner of the squad Data Analytics Platform with knowledge in data engineering, data science, and ML engineering.
Christopher Masch is the Product Owner of the squad Data Analytics Platform with knowledge in data engineering, data science, and ML engineering.
 Alexander Meinert is part of the Data Analytics Platform team and works as an ML engineer. Started with statistics, grew on data science projects, found passion for ML methods and architecture.
Alexander Meinert is part of the Data Analytics Platform team and works as an ML engineer. Started with statistics, grew on data science projects, found passion for ML methods and architecture.
 Dr. Lars Palzer is a data scientist and part of the Data Analytics Platform team. After helping to build the MLOps architecture components, he is now using them to build ML products.
Dr. Lars Palzer is a data scientist and part of the Data Analytics Platform team. After helping to build the MLOps architecture components, he is now using them to build ML products.
 Jan Schillemans is a ML engineer with a software engineering background. He focusses on applying software engineering best practices onto ML environments (MLOps).
Jan Schillemans is a ML engineer with a software engineering background. He focusses on applying software engineering best practices onto ML environments (MLOps).