Artificial Intelligence
How Sonrai uses Amazon SageMaker AI to accelerate precision medicine trials
In precision medicine, researchers developing diagnostic tests for early disease detection face a critical challenge: datasets containing thousands of potential biomarkers but only hundreds of patient samples. This curse of dimensionality can determine the success or failure of breakthrough discoveries.
Modern bioinformatics use multiple omic modalities—genomics, lipidomics, proteomics, and metabolomics—to develop early disease detection tests. Researchers in this industry are also often challenged with datasets where features outnumber samples by orders of magnitude. As new modalities are considered, the permutations increase exponentially, making experiment tracking a significant challenge. Additionally, source control and code quality are a mission-critical aspect of the overall machine learning architecture. Without efficient machine learning operations (MLOps) processes in place, this can be overlooked, especially in the early discovery stage of the cycle.
In this post, we explore how Sonrai, a life sciences AI company, partnered with AWS to build a robust MLOps framework using Amazon SageMaker AI that addresses these challenges while maintaining the traceability and reproducibility required in regulated environments.
Overview of MLOps
MLOps combines ML, DevOps, and data engineering practices to deploy and maintain ML systems in production reliably and efficiently.
Implementing MLOps best practices from the start enables faster experiment iterations for and confident, traceable model deployment, all of which are essential in healthcare technology companies where governance and validation are paramount.
Sonrai’s data challenge
Sonrai partnered with a large biotechnology company developing biomarker tests for an underserved cancer type. The project involved a rich dataset spanning multiple omic modalities: proteomics, metabolomics, and lipidomics, with the objective to identify the optimal combination of features for an early detection biomarker with high sensitivity and specificity.The customer faced several critical challenges. Their dataset contained over 8,000 potential biomarkers across three modalities, but only a few hundred patient samples. This extreme feature-to-sample ratio required sophisticated feature selection to avoid overfitting. The team needed to evaluate hundreds of combinations of modalities and modeling approaches, making manual experiment tracking infeasible. As a diagnostic test destined for clinical use, complete traceability from raw data through every modeling decision to the final deployed model was essential for regulatory submissions.
Solution overview
To address these MLOps challenges, Sonrai architected a comprehensive solution using SageMaker AI, a fully managed service for data scientists and developers to build, train, and deploy ML models at scale. This solution helps provide more secure data management, flexible development environments, robust experiment tracking, and streamlined model deployment with full traceability.The following diagram illustrates the architecture and process flow.
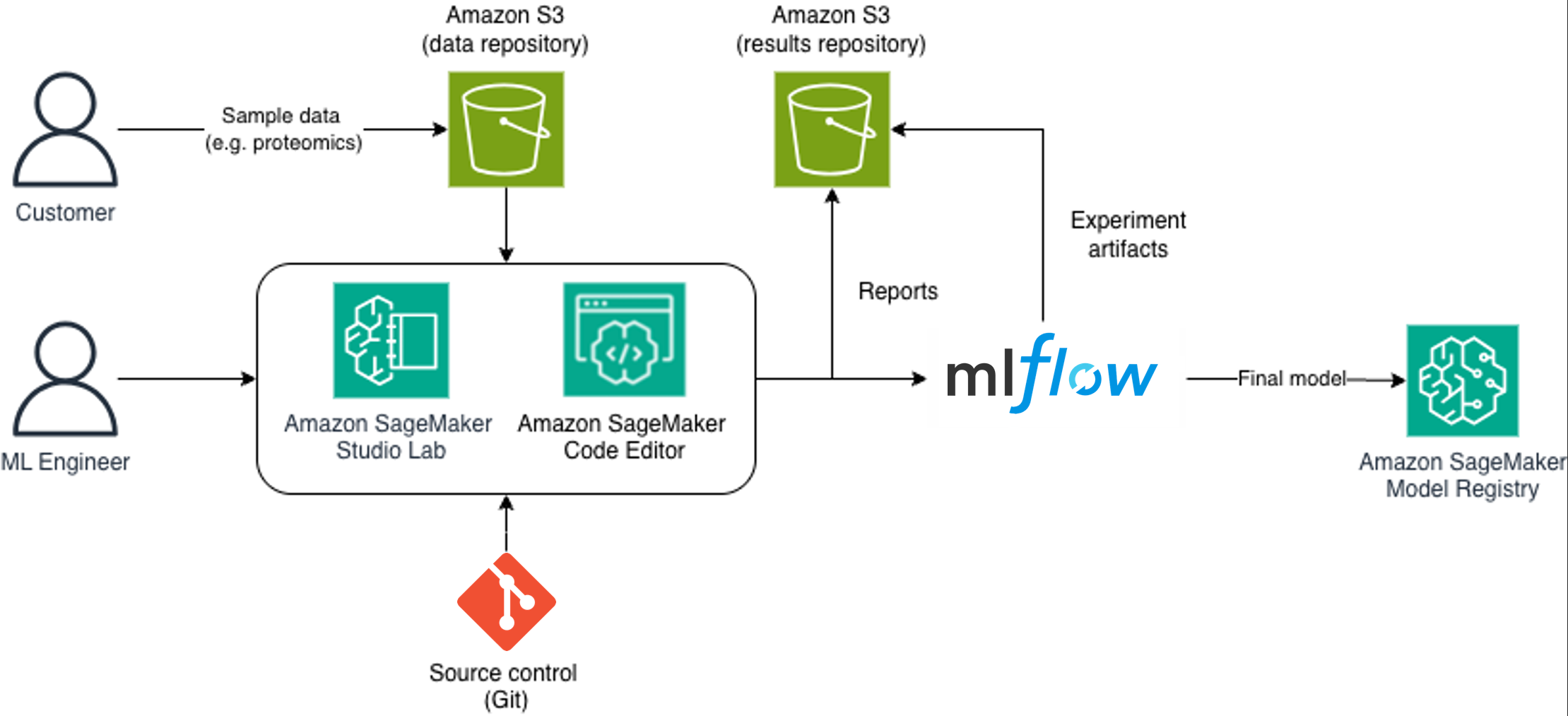
The end-to-end MLOps workflow follows a clear path:
- Customers provide sample data to the secure data repository in Amazon Simple Storage Service (Amazon S3).
- ML engineers use Amazon SageMaker Studio Lab and Code Editor, connected to source control.
- Pipelines read from the data repository, process data, and write results to Amazon S3.
- The experiments are logged in MLflow within Amazon SageMaker Studio.
- Generated reports are stored in Amazon S3 and shared with stakeholders.
- Validated models are promoted to the Amazon SageMaker Model Registry.
- Final models are deployed for inference or further validation.
This architecture facilitates complete traceability: each registered model can be traced back through hyperparameter selection and dataset splits to the source data and code version that produced it.
Secure data management with Amazon S3
The foundation of Sonrai’s solution is secure data management with the help of Amazon S3. Sonrai configured S3 buckets with tiered access controls for sensitive patient data. Sample and clinical data were stored in a dedicated data repository bucket with restricted access, facilitating governance with data protection requirements. A separate results repository bucket stores processed data, model outputs, and generated reports. This separation makes sure raw patient data can remain secure while enabling flexible sharing of analysis results. Seamless integration with Git repositories enables collaboration, source control, and quality assurance processes while keeping sensitive patient data secure within the AWS environment—critical for maintaining governance in regulated industries.
SageMaker AI MLOps
From project inception, Sonrai used both JupyterLab and Code Editor interfaces within their SageMaker AI environment. This environment was integrated with the customer’s Git repository for source control, establishing version control and code review workflows from day one.SageMaker AI offers a wide range of ML-optimized compute instances that can be provisioned in minutes and stopped when not in use, optimizing cost-efficiency. For this project, Sonrai used compute instances with sufficient memory to handle large omic datasets, spinning them up for intensive modeling runs and shutting them down during analysis phases.Code Editor served as the primary development environment for building production-quality pipelines, with its integrated debugging and Git workflow features. JupyterLab was used for data exploration and customer collaboration meetings, where its interactive notebook format facilitated real-time discussion of results.
Third-party tools such as Quarto, an open source technical publishing system, were installed within the SageMaker compute environments to enable report generation within the modeling pipeline itself. A single quarto render command executes the complete pipeline and creates stakeholder-ready reports with interactive visualizations, statistical tables, and detailed markdown annotations. Reports are automatically written to the results S3 bucket, where customers can download them within minutes of pipeline completion.
Managed MLflow
The managed MLflow capability within SageMaker AI enabled seamless experiment tracking. Experiments executed within the SageMaker AI environment are automatically tracked and recorded in MLflow, capturing a comprehensive view of the experimentation process. For this project, MLflow became the single source of truth for the modeling experiments, logging performance metrics, hyperparameters, feature importance rankings, and custom artifacts such as ROC curves and confusion matrices. The MLflow UI provided an intuitive interface for comparing experiments side-by-side, enabling the team to quickly identify promising approaches and share results during customer review sessions.
MLOps pipelines
Sonrai’s modeling pipelines are structured as reproducible, version-controlled workflows that process raw data through multiple stages to produce final models:
- Raw omic data from Amazon S3 is loaded, normalized, and quality-controlled.
- Domain-specific transformations are applied to create modeling-ready features.
- Recursive Feature Elimination (RFE) reduces thousands of features to the most significant for disease detection.
- Multiple models are trained across individual and combined modalities.
- Model performance is assessed and comprehensive reports are generated.
Each pipeline execution is tracked in MLflow, capturing input data versions, code commits, hyperparameters, and performance metrics. This creates an auditable trail from raw data to final model, essential for regulatory submissions. The pipelines are executed on SageMaker training jobs, which provide scalable compute resources and automatic capture of training metadata.The most critical pipeline stage was RFE, which iteratively removes less important features while monitoring model performance. MLflow tracked each iteration, logging which features were removed, the model’s performance at each step, and the final selected feature set. This detailed tracking enabled validation of feature selection decisions and provided documentation for regulatory review.
Model deployment
Sonrai uses both MLflow and the SageMaker Model Registry in a complementary fashion to manage model artifacts and metadata throughout the development lifecycle. During active experimentation, MLflow serves as the primary tracking system, enabling rapid iteration with lightweight experiment tracking. When a model meets predetermined performance thresholds and is ready for broader validation or deployment, it is promoted to the SageMaker Model Registry.This promotion represents a formal transition from research to development. Candidate models are evaluated against success criteria, packaged with their inference code and containers, and registered in the SageMaker Model Registry with a unique version identifier. The SageMaker Model Registry supports a formal deployment approval workflow aligned with Sonrai’s quality management system:
- Pending – Newly registered models awaiting review
- Approved – Models that have passed validation criteria and are ready for deployment
- Rejected – Models that did not meet acceptance criteria, with documented reasons
For the cancer biomarker project, models were evaluated against stringent clinical criteria: sensitivity of at least 90%, specificity of at least 85%, and AUC-ROC of at least 0.90. For approved models, deployment options include SageMaker endpoints for real-time inference, batch transform jobs for processing large datasets, or retrieval of model artifacts for deployment in customer-specific environments.
Results and model performance
Using ML-optimized compute instances on SageMaker AI, the entire pipeline—from raw data to final models and reports—executed in under 10 minutes. This rapid iteration cycle enabled daily model updates, real-time collaboration during customer meetings, and immediate validation of hypotheses. What previously would have taken days could now be accomplished in a single customer call.The modeling pipeline generated 15 individual models across single-modality and multi-modality combinations. The top-performing model combined proteomic and metabolomic features, achieving 94% sensitivity and 89% specificity with an AUC-ROC of 0.93. This multi-modal approach outperformed single modalities alone, demonstrating the value of integrating different omic data types.The winning model was promoted to the SageMaker Model Registry with complete metadata, including model artifact location, training dataset, MLflow experiment IDs, evaluation metrics, and custom metadata. This registered model underwent additional validation by the customer’s clinical team before approval for clinical validation studies. “Using SageMaker AI for the full model development process enabled the team to collaborate and rapidly iterate with full traceability and confidence in the final result. The rich set of services available in Amazon SageMaker AI make it a complete solution for robust model development, deployment, and monitoring,” says Matthew Lee, Director of AI & Medical Imaging at Sonrai.
Conclusion
Sonrai partnered with AWS to develop an MLOps solution that accelerates precision medicine trials using SageMaker AI. The solution addresses key challenges in biomarker discovery: managing datasets with thousands of features from multiple omic modalities while working with limited patient samples, tracking hundreds of complex experimental permutations, and maintaining version control and traceability for regulatory readiness.The result is a scalable MLOps framework that reduces development iteration time from days to minutes while facilitating reproducibility and regulatory readiness. The combination of the SageMaker AI development environment, MLflow experiment tracking, and SageMaker Model Registry provides end-to-end traceability from raw data to deployed models—essential for both scientific validity and governance. Sonrai saw the following key results:
- 8,916 biomarkers modeled and tracked
- Hundreds of experiments performed with full lineage
- 50% reduction in time spent curating data for biomarker reports
Building on this foundation, Sonrai is expanding its SageMaker AI MLOps capabilities. The team is developing automated retraining pipelines that trigger model updates when new patient data becomes available, using Amazon EventBridge to orchestrate SageMaker AI pipelines that monitor data drift and model performance degradation.
Sonrai is also extending the architecture to support federated learning across multiple clinical sites, enabling collaborative model development while keeping sensitive patient data at each institution. Selected models are being deployed to SageMaker endpoints for real-time predictions, supporting clinical decision support applications.
Get started today with Amazon SageMaker for MLOps to build your own ML Ops piplines. Please find our introductory Amazon SageMaker ML Ops workshop to get started.